Inspiration
Every business runs on one tool nobody builds connectors for. The climbing-gym scheduler. The regional invoicing app. The niche device cloud. Fivetran moves data from 750+ sources, beautifully — but the long tail is long, and the data inside it just sits there: orphaned. The only way out used to be hand-writing an ETL script that rots in a cron job. I kept thinking about the gym manager who just wants to know her quietest hour so she can schedule route-setting. Why should the answer depend on whether your tool is famous enough to deserve a connector?
What it does
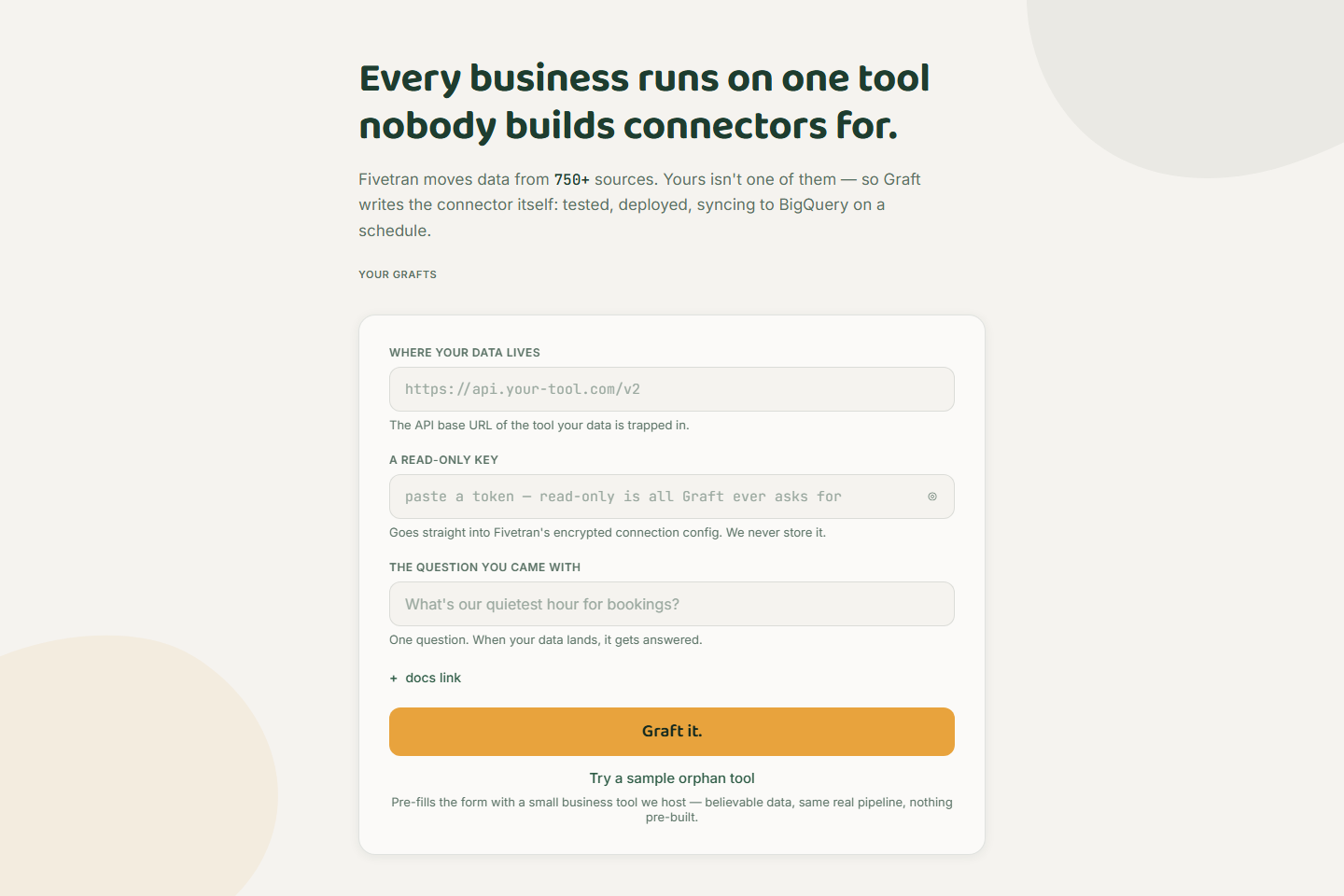
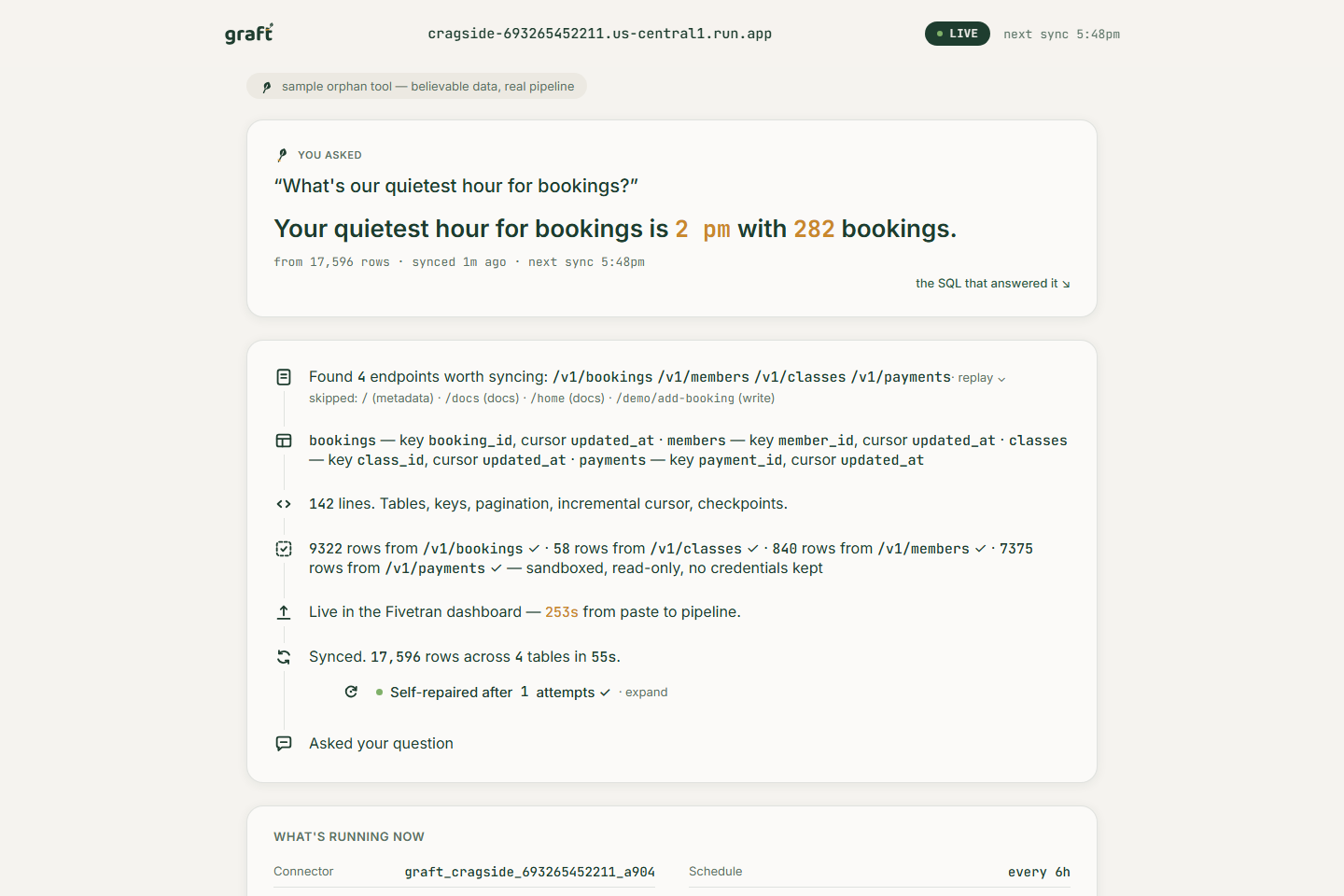
You give Graft three things — an API base URL, a read-only key, and the question you actually came with. Then an agent operates Fivetran itself, end to end, while you watch:
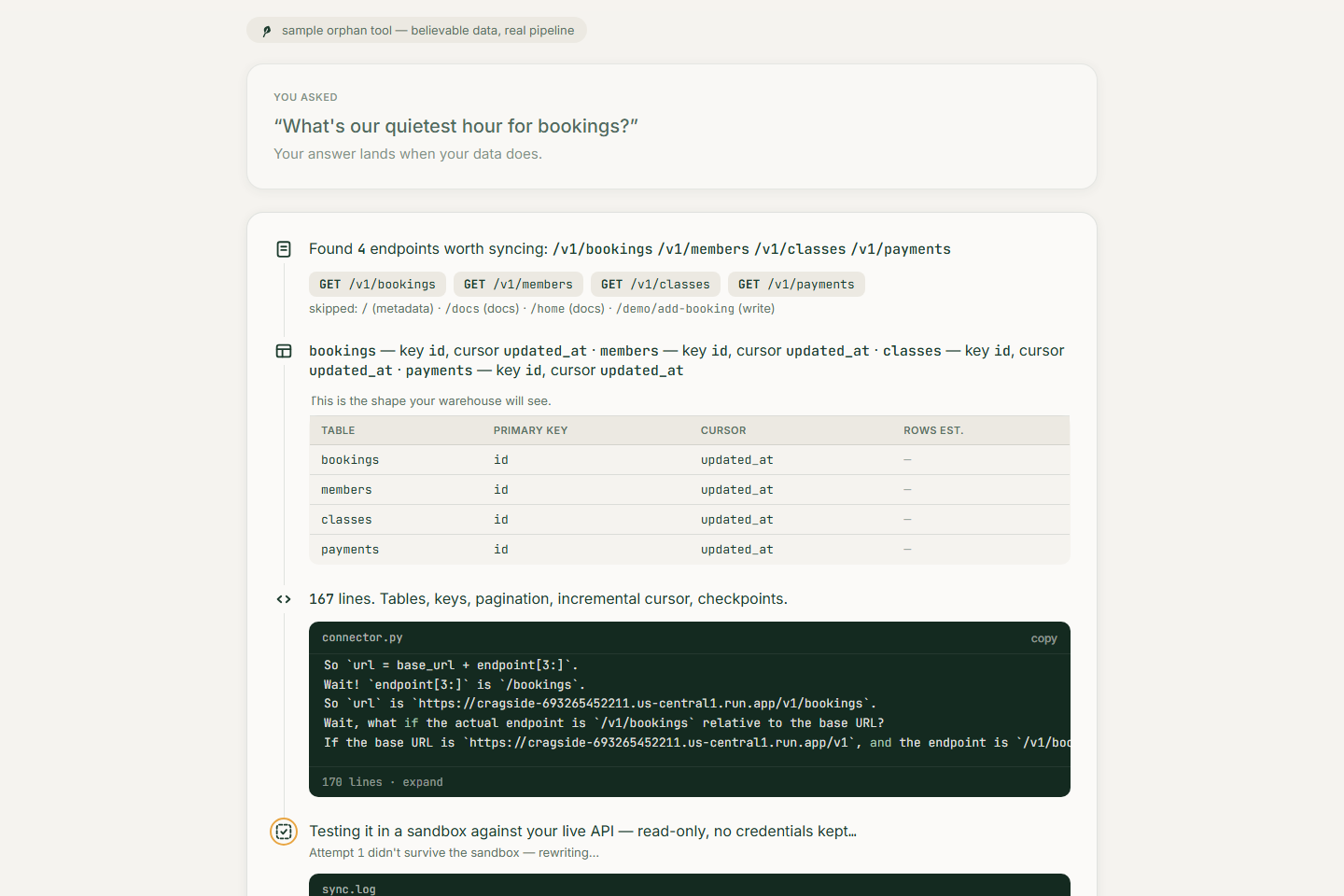
- Reads the tool's API docs — or probes the live endpoint and infers schema and pagination from raw JSON
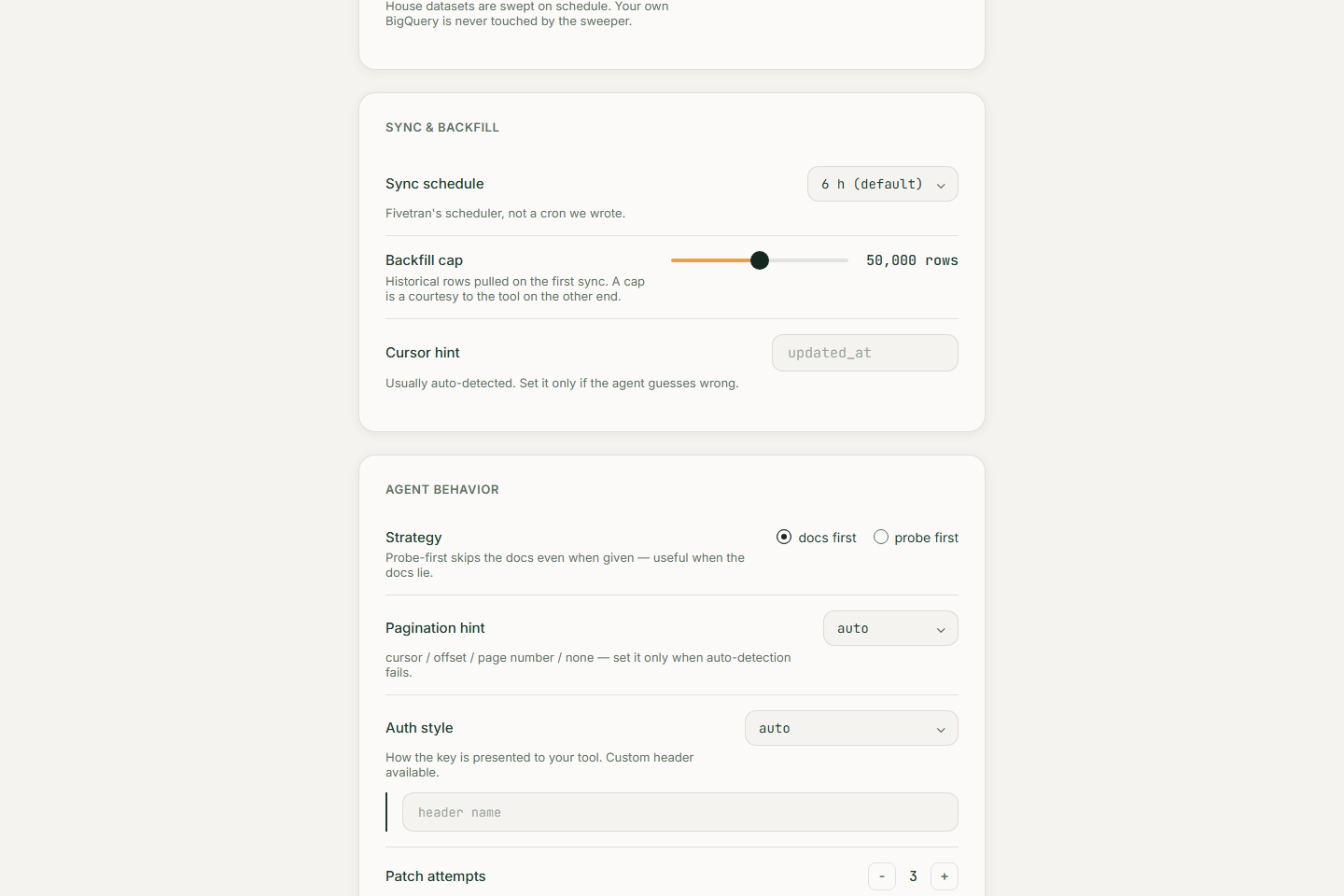
- Writes a real Fivetran Connector SDK connector in Python: tables, primary keys, pagination, incremental cursor, checkpoints
- Tests it with the SDK's local debug run in a credential-scrubbed sandbox against the live API — you see the actual rows it pulled
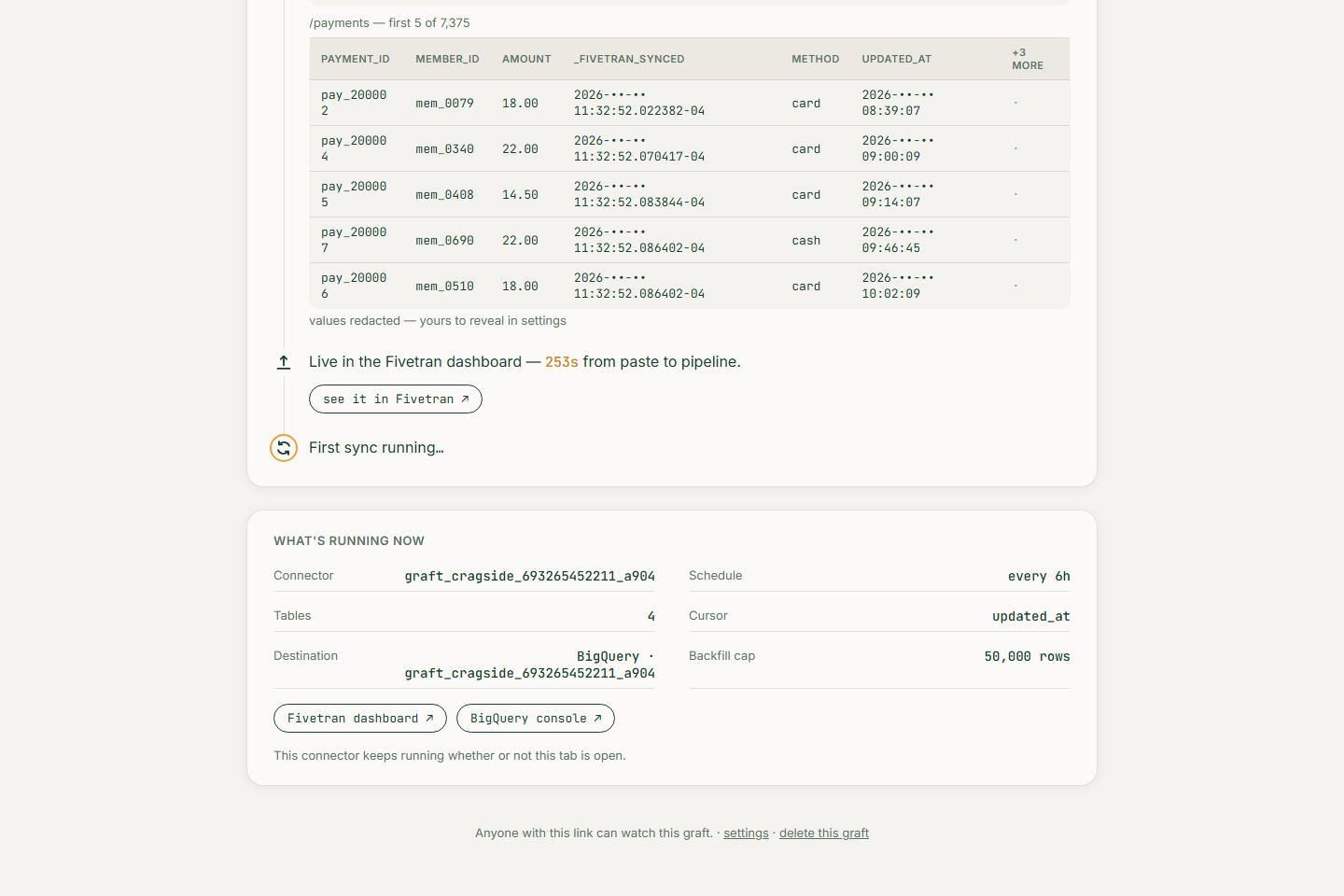
- Deploys it into a live Fivetran account with the SDK's real deploy command — it shows up in the Fivetran dashboard like any native connector
- Watches the first sync over MCP; if a sync fails, it reads the logs, rewrites its own connector, and redeploys (up to 3 attempts, then it gives up honestly)
- Answers your question with one Gemini-written SQL query over the landed BigQuery tables
- Keeps going — Fivetran's scheduler runs future syncs; after each one Graft writes a what-changed digest and re-answers your question, whether or not anyone has the page open
The connector is the product. Everything else exists to put that mechanic on stage.
How I built it
The agent's hands — a fivetran-mcp fork. I forked Fivetran's official MCP server
and extended it with the five tools the agent needs to operate the platform:
sdk_debug_run, sdk_deploy, connection_status, sync_logs, trigger_sync —
wrapping the Connector SDK CLI and the Fivetran REST API. The Graft agent connects
to the fork over stdio MCP; flip "Show raw MCP traffic" in settings and every tool
call renders inline in the build feed.
The agent's brain — Gemini on Vertex AI. Gemini handles everything that needs judgment: endpoint extraction from docs, schema planning, connector codegen, sync-log diagnosis, answer SQL, digest lines. Orchestrated in Python (Google ADK), hosted on Cloud Run.
The pipeline. A stage machine (THINKING → READING → WRITING → TESTING → DEPLOYING → SYNCING → LIVE) emits every event into a Firestore-backed log plus a live SSE bus — so the graft page is a permalink: refresh mid-run and the whole feed replays.
The proof harness. Generated connectors run first in an isolated sandbox with no
ambient credentials (fivetran debug, DuckDB inspected for the sample rows you see),
and only then deploy. Landed data goes to BigQuery, one dataset per graft.
The sample orphan tool. "Cragside," a fictional climbing-gym scheduler, is a real hosted API — token auth, cursor pagination, docs page, even an add-a-booking button so anyone can create the +1 record that proves incremental sync. Pressing "Try a sample orphan tool" just pre-fills the form; the pipeline that runs is identical to what runs on your own API, and the UI labels the sample path wherever it's active.
Challenges I ran into
1. Letting an agent deploy code without trusting it blindly: generated connectors execute only in a credential-scrubbed sandbox before any deploy, backfills are row-capped (50,000 by default), keys are requested read-only, and a "review the code before deploy" gate is one settings toggle away.
2. Making self-repair real instead of theatrical: when a sync fails, an agent
holding the MCP toolset reads sync_logs itself, names the root cause, rewrites
connector.py, sandbox-checks it, and redeploys — capped at 3 attempts, after which
Graft pauses the connector and says so. The patch loop you see in the feed is never
simulated.
3. A permalink that survives anything: runs are long, judges refresh pages. Every event lands in Firestore before it hits the SSE bus, so the feed replays byte-for-byte on every reload.
4. Where the user's API key lives: only inside the Fivetran connection's encrypted config. Never in app storage, never logged, redacted from the feed.
Accomplishments that I'm proud of
- From pasted URL to a LIVE connector in minutes — on my demo run the generated connector was 150 lines, and the first sync landed 17,599 rows across 4 tables in 2m 42s.
- A meaningful MCP fork — five new tools that turn Fivetran's read-only MCP server into hands that can debug, deploy, watch, and retrigger connectors.
- No invented numbers anywhere — every figure in the UI (row counts, deploy seconds, line counts) is measured at runtime. If it wasn't measured, it isn't shown.
- The whole real path works for strangers: paste any token-authenticated API and watch a connector appear in a live Fivetran dashboard, cold.
What I learned
- Incremental state is the moat. Anyone can generate a one-off ETL script; the hard, valuable part is what Fivetran's runtime provides — schedules, cursors, retries, monitoring. Putting the agent on top of that machinery beats rebuilding it.
- Show the work, win the trust. Streaming the actual connector code and the actual sandbox rows converted skeptics faster than any landing-page claim.
- Agents need narrow, well-named tools. The fork's five purpose-built MCP tools made the self-repair loop reliable; one giant "do Fivetran stuff" tool did not.
What's next for Graft
- Auth breadth: OAuth flows (today: token/header auth, which covers most of the long tail honestly).
- Schema evolution: when the source adds fields, regenerate and redeploy the connector as a routine digest event.
- Bring-your-own everything: the settings page already takes your own Fivetran account and BigQuery project; next is org-level sharing of grafted connectors.
- A gallery of grafts: every orphan tool somebody grafts is a connector the long tail didn't have yesterday.
The Bigger Picture
The long tail deserves real pipelines. Your data belongs in your warehouse even when your tool is something nobody's heard of — no connector? Graft one.
Built With
Python · FastAPI · Gemini (Vertex AI) · Google ADK · MCP (fivetran-mcp fork) · Fivetran Connector SDK · Fivetran REST API · BigQuery · Firestore · Cloud Run · DuckDB · Server-Sent Events · Jinja2
Try it out
- Live app: https://graft-693265452211.us-central1.run.app — no login; press "Try a sample orphan tool", press "Graft it.", and watch. Or paste any token-authenticated JSON API you own.
- Code: https://github.com/RemiKG/graft-fivetran (Apache-2.0)
- The sample orphan tool (real hosted API + docs): https://cragside-u62i6pqsxq-uc.a.run.app/home

Log in or sign up for Devpost to join the conversation.