-
-
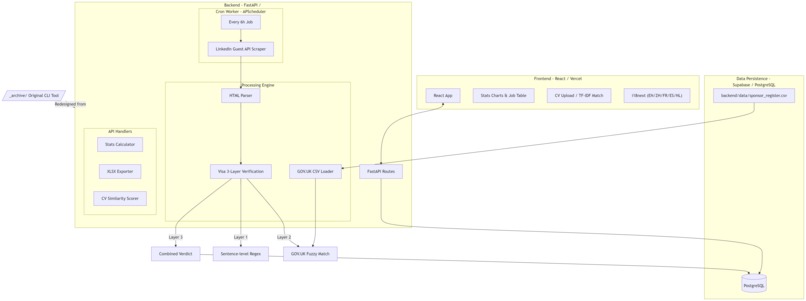
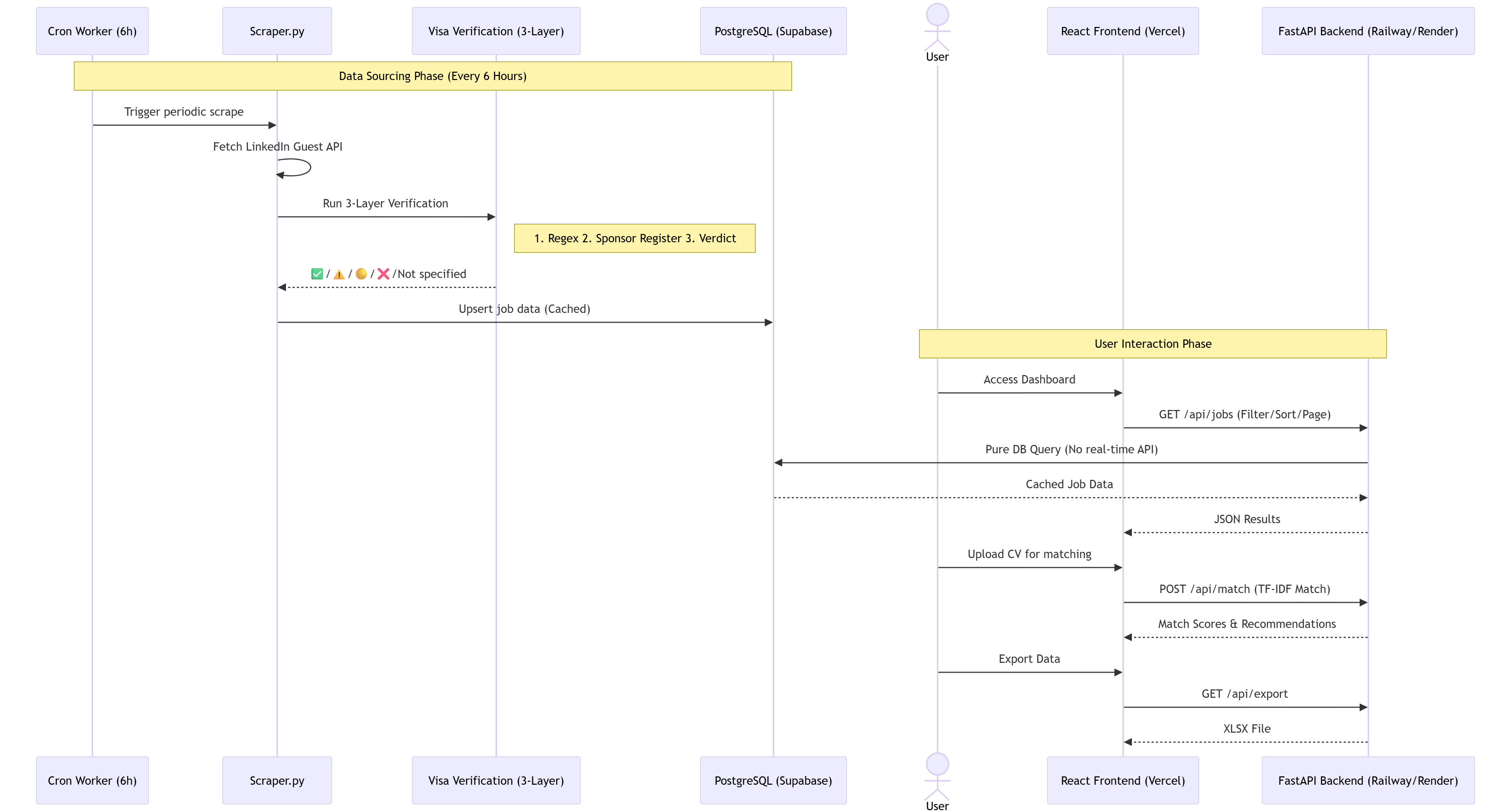
System architecture featuring FastAPI, React, and PostgreSQL, illustrating the pipeline from automated LinkedIn
-
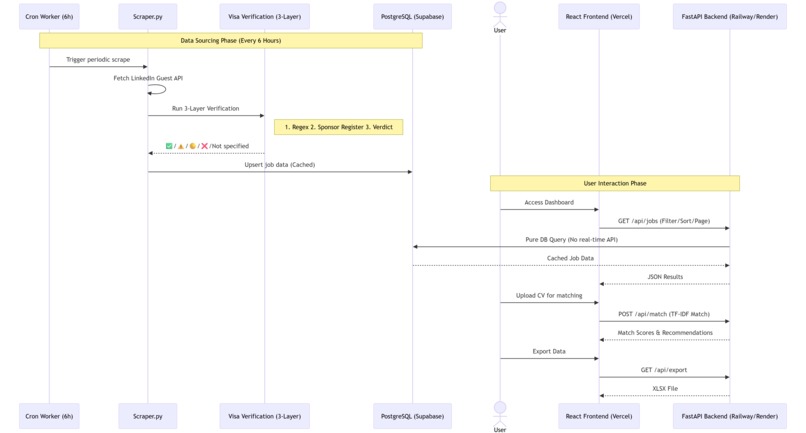
Sequence diagram
GradJobsUK
Inspiration
Every graduate student faces the overwhelming pressure of navigating hundreds of unstructured LinkedIn job descriptions. For international students, there's an additional, critical pain point: identifying which companies actually offer visa sponsorship.
Our research revealed two core problems with traditional platforms:
1. Unstructured Data
Job descriptions are massive blocks of text, making bulk filtering nearly impossible.
2. Unreliable Visa Information
Companies with sponsor licenses often omit this information, while others include the word "sponsor" only to state "this role does not offer sponsorship."
Manually screening these takes 1–3 hours daily.
To solve this, we applied Text Mining and Correlation Analysis to build GradJobsUK — a quantified, scalable, and highly relevant data platform tailored specifically for graduate students in the tech space.
What It Does
GradJobsUK is a job aggregation platform anchored on the job seeker's specific skills.
It automatically scrapes LinkedIn every 6 hours, exclusively targeting CS and Data roles:
- Software Engineering (SWE)
- Machine Learning (ML)
- DevOps
- Quant
- Data-related roles
The system only collects jobs that:
- Were posted within the last 24 hours
- Have fewer than 100 applicants
User Experience
The platform focuses on high-efficiency data consumption.
Interactive Dashboard
Features:
- 4 macro statistical metrics
- 3 visual charts
All components dynamically sync with a global time filter, allowing users to quickly identify market trends.
Advanced Filtering
Users can rapidly narrow down opportunities using:
- Top search bar
- Left-side multi-variable filters
Excel-Grade Job List
Results are displayed in a virtualized table that supports:
- Free sorting
- Column filtering
- Direct links to the original LinkedIn job post
- One-click Excel export
CV Matching
Users can upload their CV.
The system then:
- Calculates a TF-IDF cosine similarity score
- Compares the CV with all active job listings
- Adds the match percentage as a sortable column
International Ready
The platform supports 5 languages:
- English (EN)
- Chinese (ZH)
- French (FR)
- Spanish (ES)
- Dutch (NL)
It also includes our core 5-tier visa status verification system.
How I Built It (Under the Hood)
The system was engineered to address two major technical challenges.
1. Caching Architecture (Read/Write Separation)
Users never trigger LinkedIn requests directly.
Write Path
- APScheduler triggers background tasks
- Python FastAPI (async) scrapers run periodically
- Data is upserted into PostgreSQL
- Database hosted on Railway
Read Path
- React + Vite frontend
- Queries only the PostgreSQL database
Benefits
This read/write separation ensures:
- Even with 100 concurrent users, the backend only queries the database
- The server IP never interacts with LinkedIn directly
- Avoids rate limits
- Provides high stability and performance
2. The 3-Layer Visa Verification Pipeline
Visa classification accuracy was the biggest challenge.
Scanning full job descriptions for the word "sponsor" produced massive false positives.
We designed a three-layer validation architecture.
Layer 1: Sentence-Level NLP
The system:
- Splits job descriptions into individual sentences
- Uses regex patterns
- Detects negation terms such as: cannot sponsor/does not offer sponsorship
This prevents cross-sentence mismatches.
Layer 2: GOV.UK Cross-Validation
The system performs token-set fuzzy matching against the official:
Home Office Licensed Sponsors database
- 90,000+ companies
- 85% similarity threshold
This verifies whether the company is officially licensed to sponsor visas.
Layer 3: Composite Verdict
Both sources are synthesized into a 5-tier confidence rating:
| Status | Meaning |
|---|---|
| ✅ Confirmed | Explicitly states sponsorship |
| 🟡 Licensed | Company is licensed but not stated |
| ⚠️ Unverified | Unclear sponsorship status |
| ❌ No Sponsorship | Explicitly states no sponsorship |
| Not Specified | No relevant information |
Challenges
Scraping Resilience
Balancing scraping speed and LinkedIn rate limits required careful tuning.
Final configuration:
- 3-thread concurrency
- 0.8–2s random delays
- 6-hour scraping interval
This reduced total scraping time:
- From 30 minutes (serial)
- To under 10 minutes
While remaining well under LinkedIn detection thresholds.
What I Learned
Cross-source Data Validation
Combining:
- GOV.UK official data
- NLP-parsed job descriptions
created a far more reliable verification system than keyword detection alone.
Importance of Caching Architecture
Separating read and write paths:
- Solved rate-limiting issues
- Improved system performance
- Increased scraper stability
Async System Design
Building a fully asynchronous pipeline helped me understand how Python's event loop interacts with:
- I/O-bound tasks (scraping, database operations)
- CPU-bound tasks (TF-IDF computation)
Built With
- ag-grid
- apscheduler
- fastapi
- pypdf2
- python
- railway
- react
- react-i18next
- recharts
- scikit-learn
- sqlalchemy
- sqlite
- tailwind-css
- vercel
- vite
 Zuo")
Log in or sign up for Devpost to join the conversation.