-
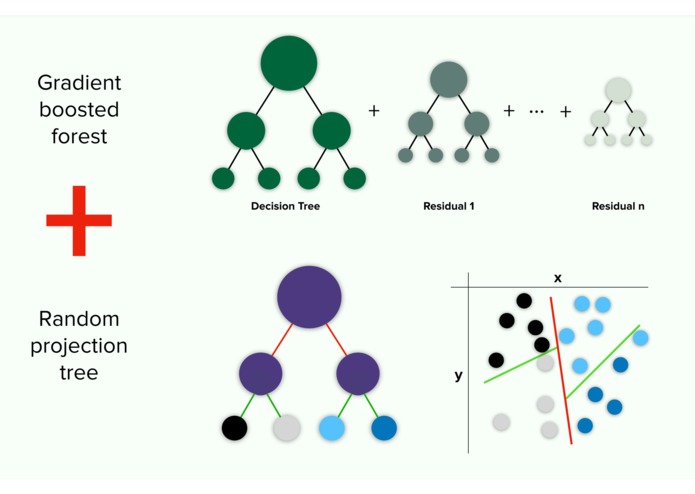
Gradient Boosted Random Projection Forests
-
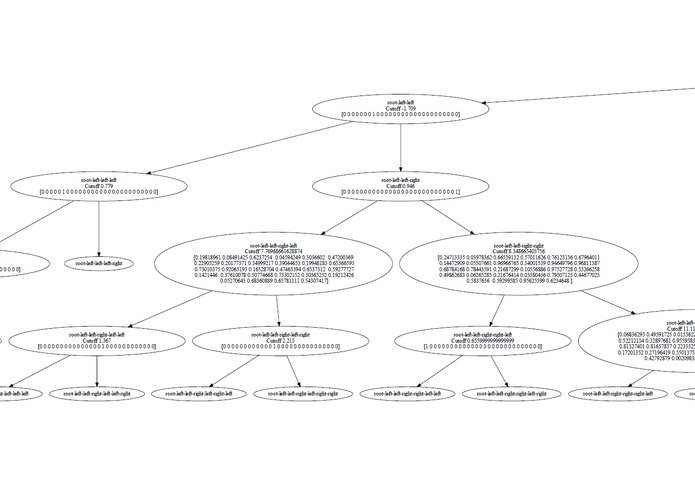
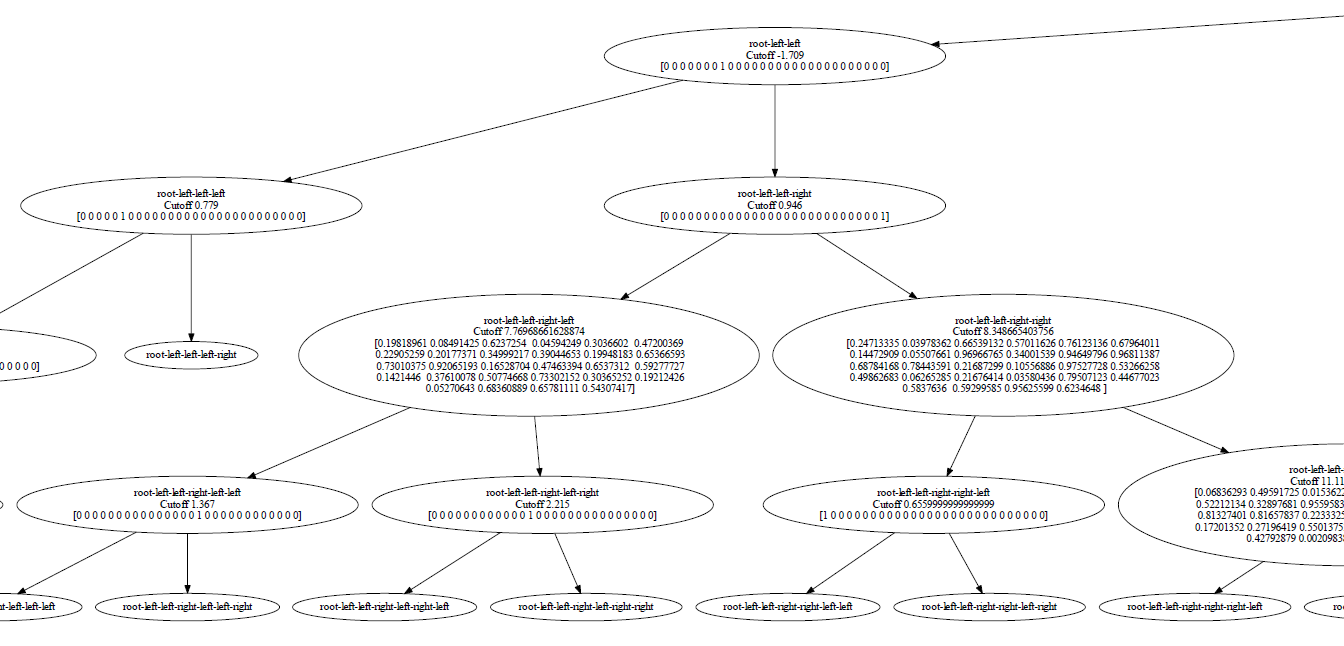
Left side of the gradient boosted random projection forest with cutoff values and linear combination coefficients.

Background
PennApps was the third or fourth hackathon for most of our team members, and we yearned to do something new, unique, and different than the web or mobile apps that we had done before. Though all of us had some experience in Machine Learning, Nathan V. in particular worked with the Army, doing statistical analysis in the summer, and enrolled in a ML-focused research project course this semester at Hopkins. From these experiences, he came up with the ambitious idea and a basic plan to not just to apply ML to a certain problem, but to create our own Machine Learning Algorithm.
What it does
Our algorithm, which we call Gradient Boosted Random Projection Forest, combines two recent developments in Machine Learning Gradient Boosted Trees and Projection Trees. Gradient Boosting, in basic terms, takes a normal decision tree, trains it, then learns from the errors to create a new, more accurate tree. This process is repeated until the errors cannot further be significantly reduced. Projection Trees are a variant of decision trees that, instead of using just one variable in its decisions, use combinations of one or more variables. For example, an algorithm might check whether a person's height is greater than 5'7" or not, and then proceed differently based on that fact. But a projection tree could instead decide based on both weight and height at the same time. In essence, our algorithm simply takes a Gradient Boosted Tree implementation and replaces its internal trees with Projection trees.
How we built it
We first drafted out a plan for how we should accomplish our goal. We based our gradient boosted projection forest algorithm on a compact implementation of decision trees in Python. Then, Dan Q. gradually added concepts slowly, first implementing a "dumb" version of a concept before implementing the actual concept. For example, while converting regular decision trees to projection trees, we implemented the new vectors in a way that produced the same results as the old implementation to check for accurate implementation. We wanted to implement the algorithm correctly on the first try to prevent wasted time on debugging, a difficult task in dense, mathematical code.
Challenges we ran into
Because the code was extremely dense, each line required careful thought and discussion. Mistakes cost a lot of time due to the time needed to debug the code and the wasted time running/testing the algorithm. Also, we tried to implement gradient descent on linear combinations instead of relying on random coefficients, but that did not end up working because we did not have the time to learn the knowledge needed for implementation.
Accomplishments that we're proud of
At first, we did not know how feasible it was to do the project. Fearing it was too difficult, our group nearly abandoned the project in pursuit of a more traditional hackathon project. However, we decided to go for the idea and ended up creating a novel algorithm which reliably surpasses the accuracy of current state-of-the-art machine learning algorithms in all of the datasets we ran. We were also proud how we worked together to solve challenges as collaboration was much-needed considering the difficulty of the project. Suvir M. especially helped by leveraging his experience to direct the overall workflow. Jason W. also created a very interesting visualization tool for our decision trees (can be seen above).
What we learned
All four of us garnered great amounts knowledge about machine learning. Some of us had no theoretical knowledge of how decision trees and gradient boosting worked, so we had to learn about the topics as we planned and worked on our project. We also learned how to practically create and implement an algorithm and how results may not come out as we intended. For example, some "optimizations" we tried to do took longer than expected, and we had to choose an alternative path to produce a viable machine learning model.
What's next for Gradient-Boosted Projection Forests
In the future, we hope to optimize the algorithm to perform faster because we made trade-offs to ensure we had enough time to complete our project. Besides optimizing the code, we can also optimize the learning itself by introducing multiprocessing support. Currently, only one core is used for computations, which take especially long on low-end computers. Next, we would like to spend more time tuning hyperparameters to allow for a lower root-mean-squared error. Essentially, we would run the algorithm with different options (e.g. learning rate) until we find an optimal combination. Last, the application needs to be extensively tested using different datasets. To consider our algorithm state-of-the-art, it should perform well on a variety of datasets.




Log in or sign up for Devpost to join the conversation.