-
-
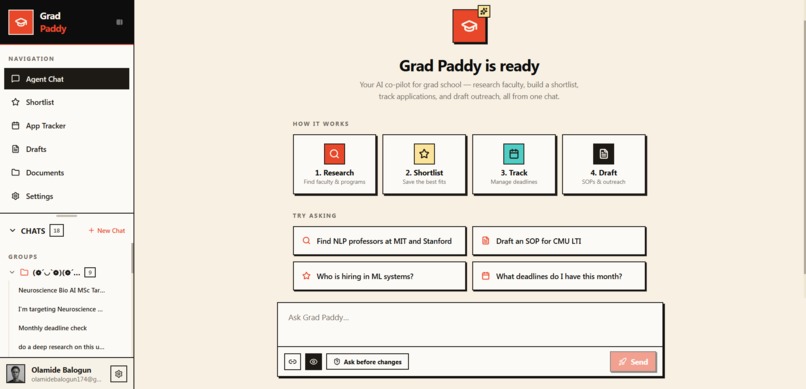
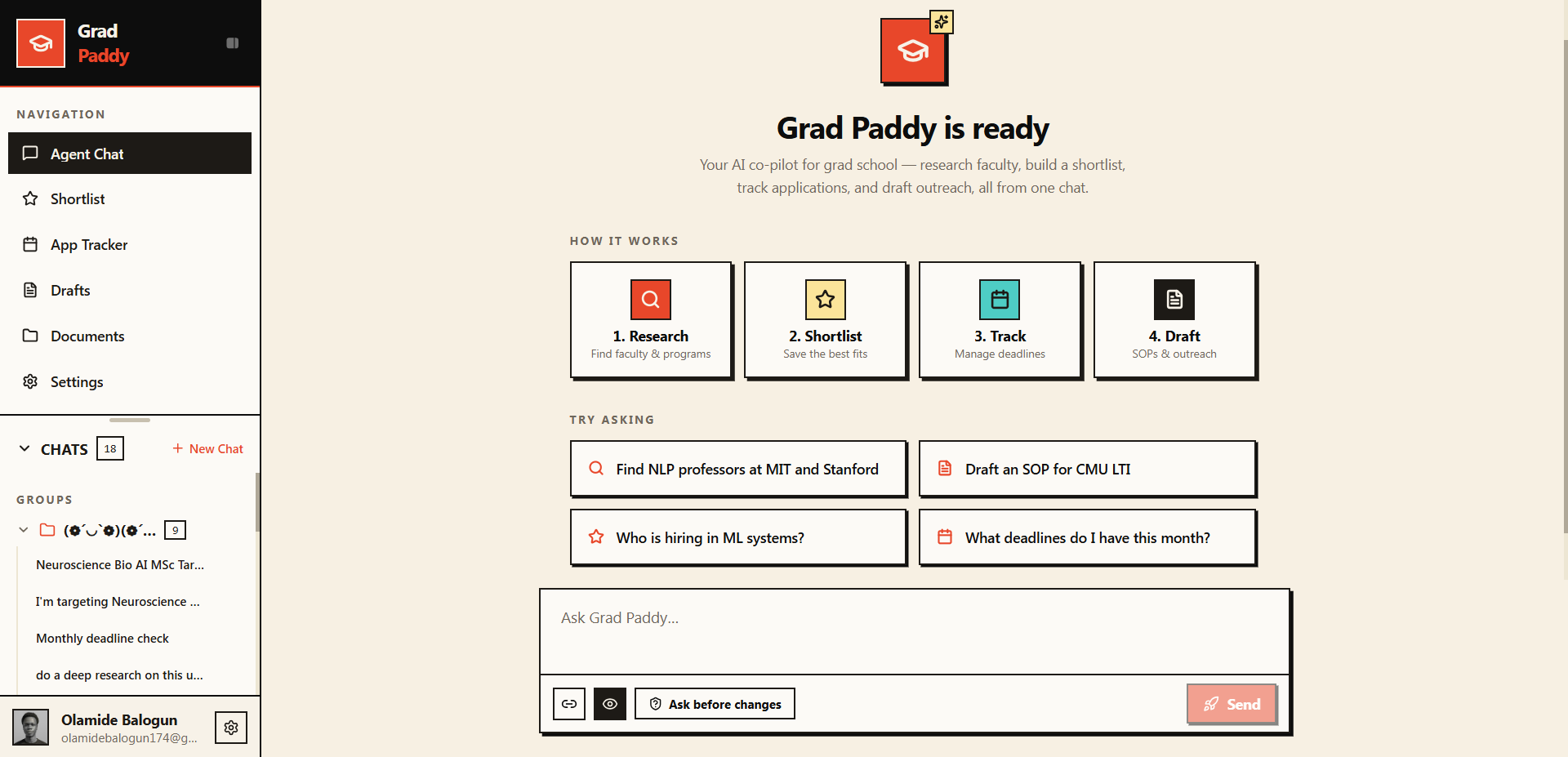
One chat: research faculty, build a shortlist, track deadlines, draft outreach. A multi-step agent, not a chatbot.
-
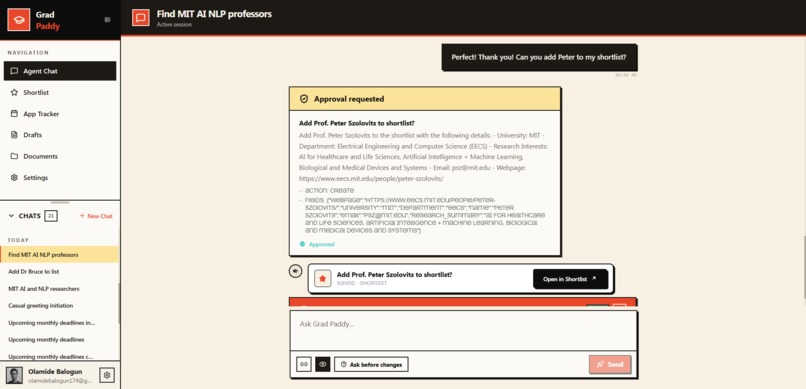
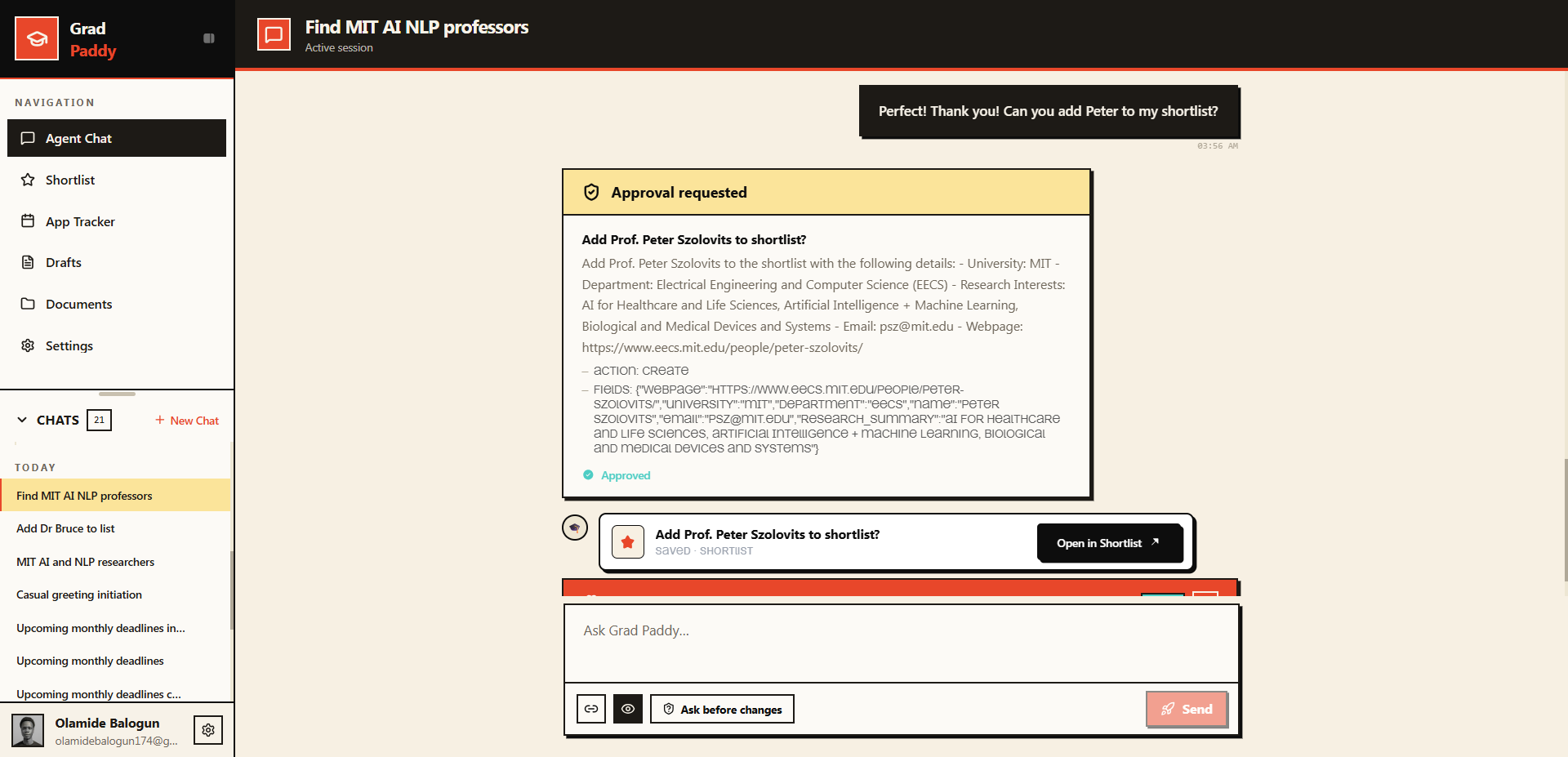
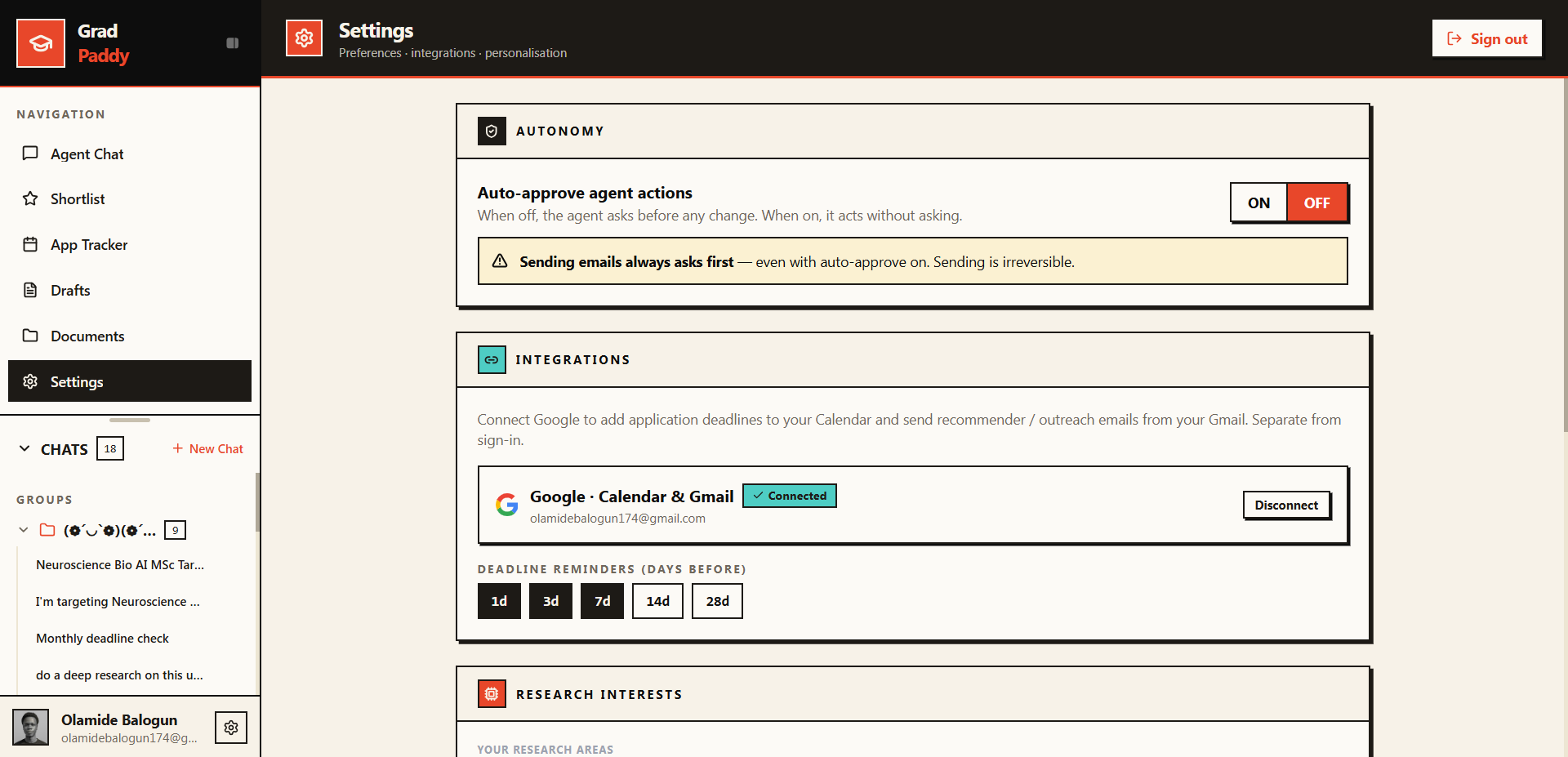
Beyond chat: the agent proposes an action and waits for your approval before writing anything. You stay in control.
-
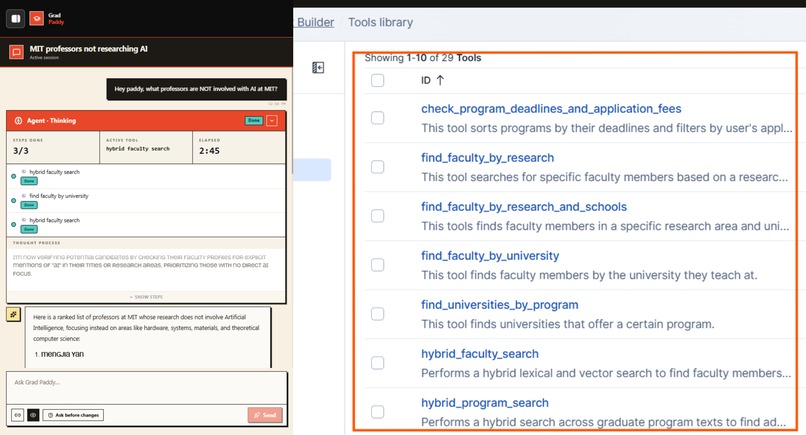
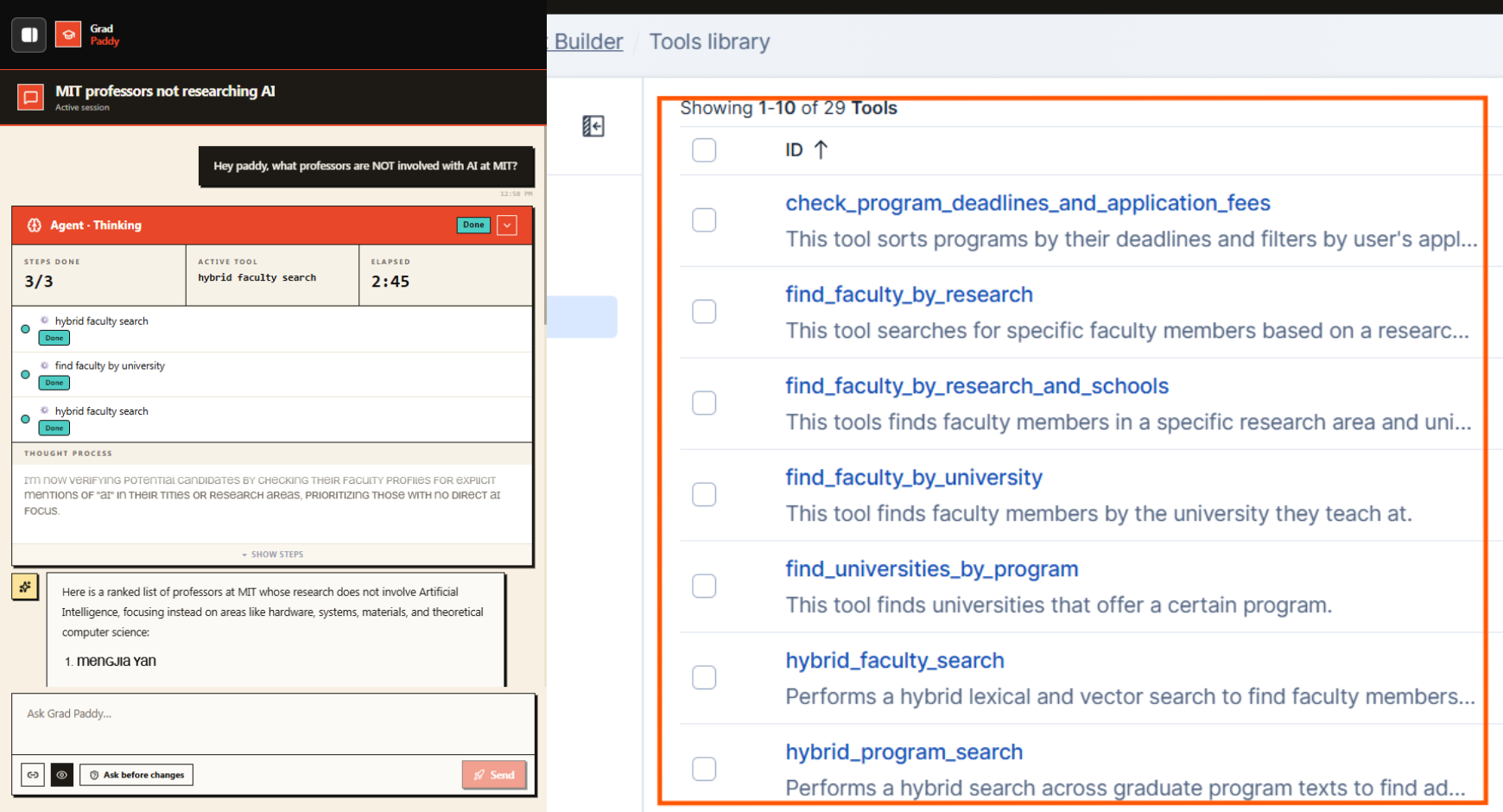
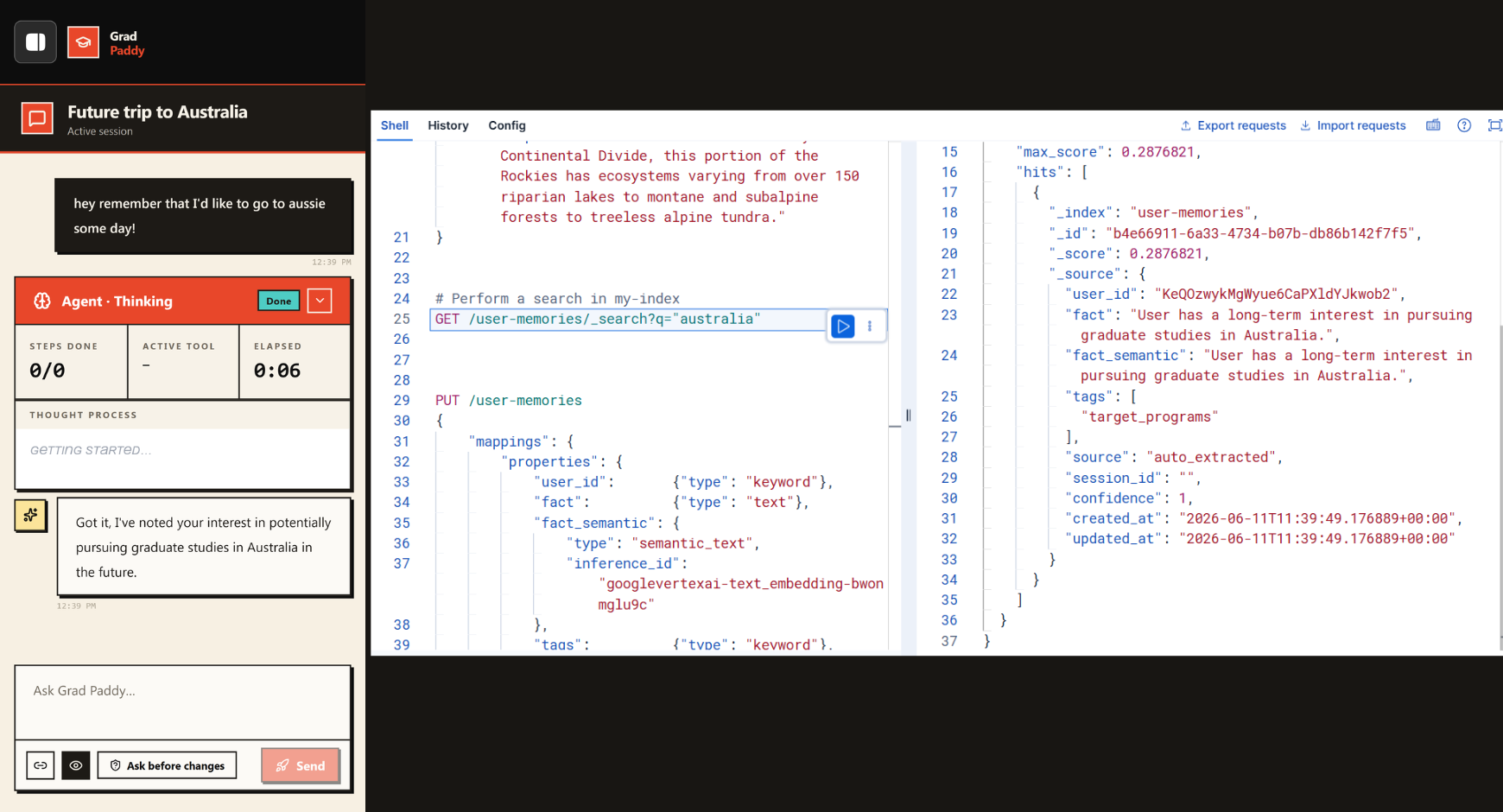
The discovery agent drives the Elastic MCP server, composing two hybrid search calls to find matching faculty
-
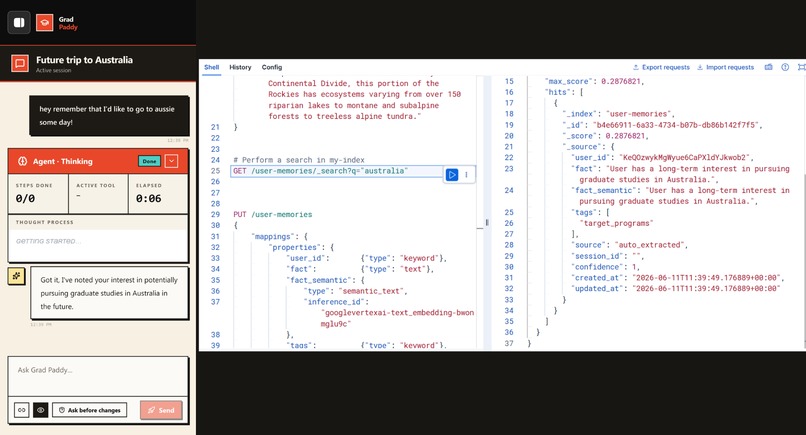
Durable user memory, saved natively to an Elastic semantic index embeddings generated inside Elasticsearch.
-
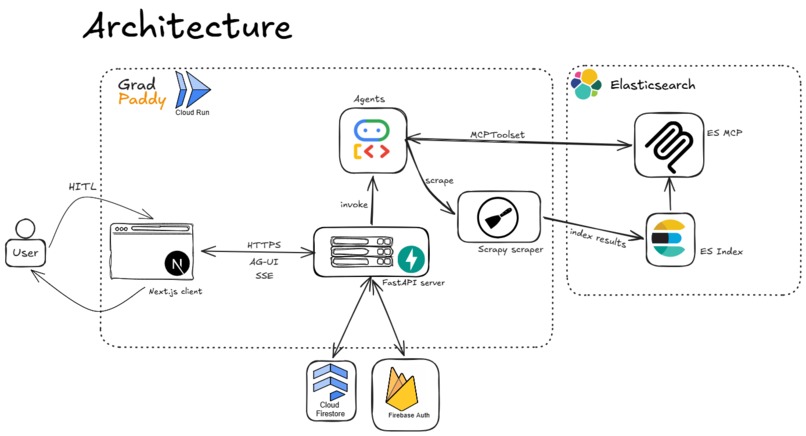
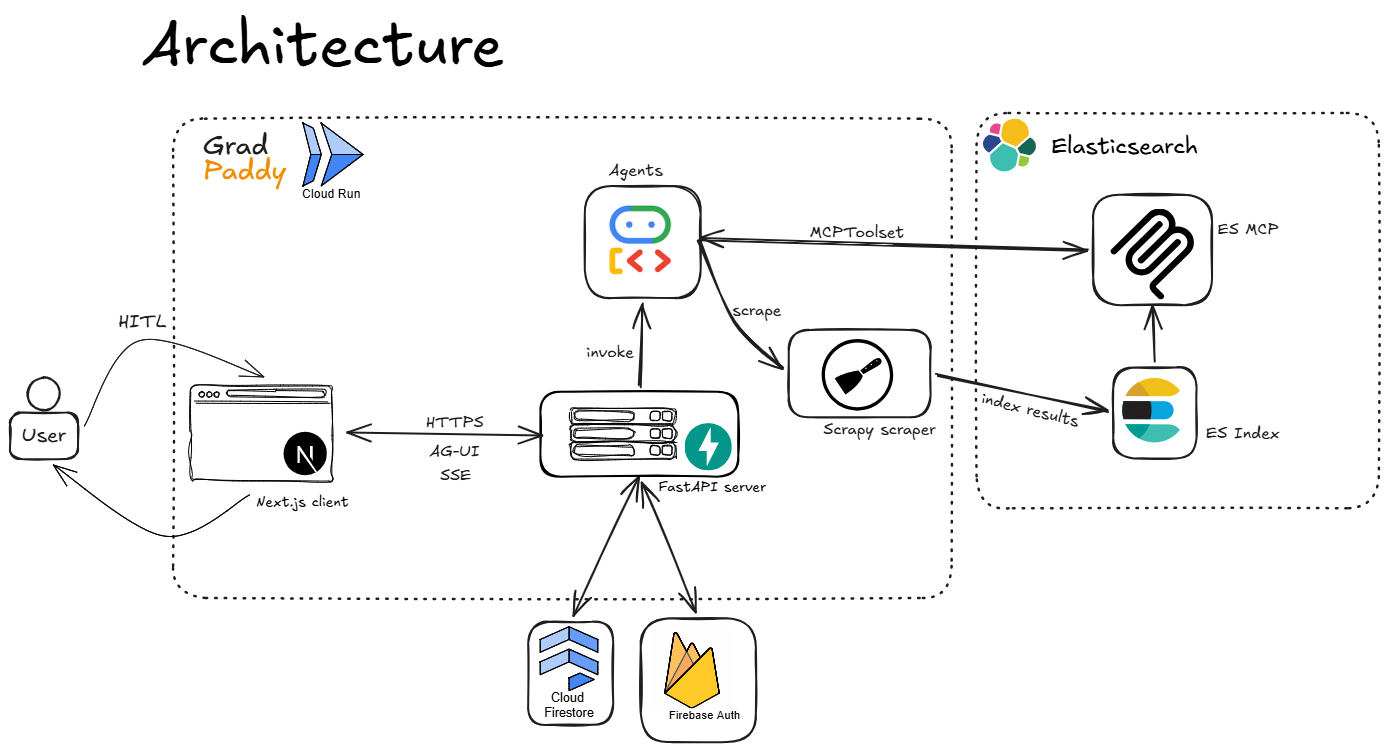
System architecture: Gemini 3 reasoning, a multi-agent router, Elastic retrieval, HITL and grounding enforced in code.
-
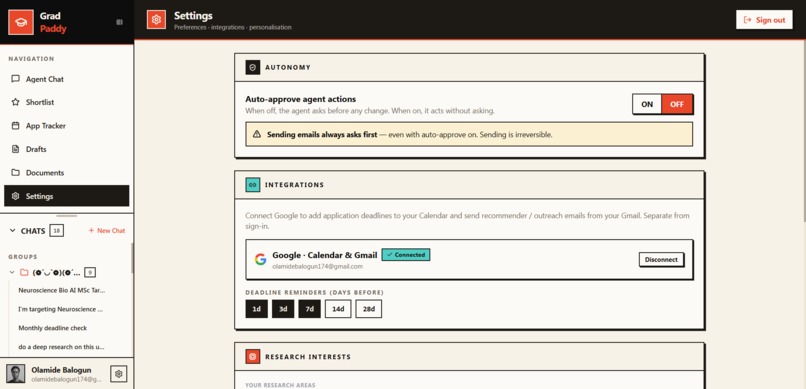
Autonomy on your terms: toggle auto-approve, set deadline reminders, connect Google Calendar and Gmail.
-
Escape application gravity. Your AI co-pilot for grad school — research, shortlist, track, and draft.
-
One-tap Google sign-in. Every shortlist, draft, and memory is scoped to your authenticated account.
-
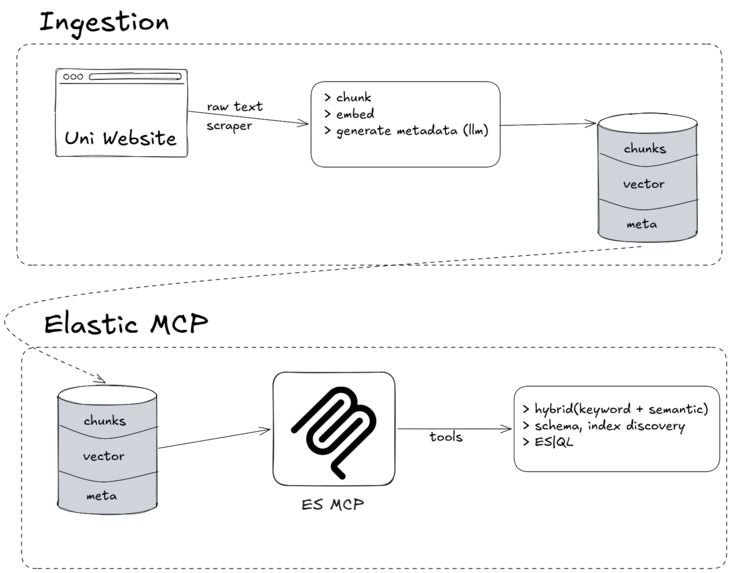
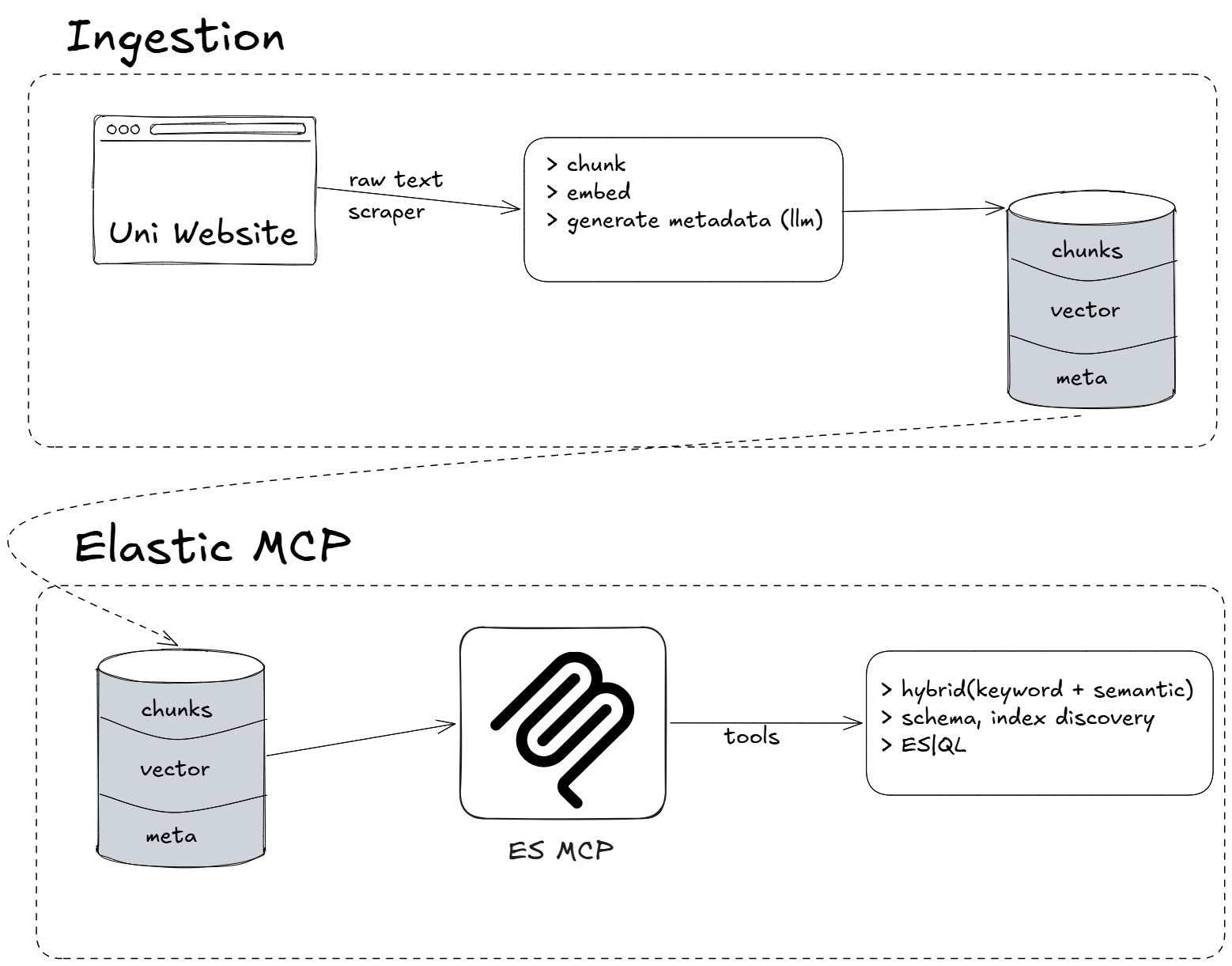
Indexing data flow: user URLs are scraped, chunked, and indexed into Elastic for the agent's hybrid search.
Inspiration
We hit this wall ourselves, applying to grad school early in our careers from product and industry backgrounds. The application process is a full-time job stacked on top of the one you already have, no matter how qualified you are going in.
Most of that job is grunt-work that shouldn't need a human: verifying requirements and deadlines across a dozen portals, then sifting hundreds of faculty pages to find the handful of professors actually working in your niche, who also have funding and take students. The information is everywhere and nowhere, program rules on one site, research on a departmental page, recent papers on Google Scholar / OpenAlex, funding buried in a forum thread.
Coming from industry, there's a second wall: translating real product experience into the research-oriented narrative a statement of purpose demands, with no template for how.
And the obvious shortcut betrays you. A generic chatbot doesn't reason about time, it won't check today's date against a deadline, so it can't tell you what's still open, what's closed, or what's next. In a process where one wrong date costs a year, that's a liability.
The hard part is synthesis: turning fragmented, stale, contradictory information into decisions, over months, while the rest of your life keeps running, and dropping nothing.
What it does
Grad Paddy walks an applicant through the real application flow. Each capability is a multi-step agentic task with a clear trigger, a visible execution trace, and, where it matters, a human approval gate.
| Capability | What the agent does | Grounding / HITL |
|---|---|---|
| Program & Faculty Discovery | Ingests user-provided program/faculty URLs, indexes them into Elasticsearch, runs hybrid semantic + keyword search against the user's stated research interest, returns a ranked list of faculty with research area, recency signal, and source URL + date scraped | RAG only, no answers from LLM memory. User approves before a shortlist is saved |
| Faculty Profile Deep-Dive | Pulls recent papers (OpenAlex), summarizes research themes, computes a fit score labeled "indexed-content match," not an admissions probability, and proposes conversation angles drawn from the professor's actual work | Citations grounded in retrieved content; fit score explicitly non-predictive |
| SOP / Research Statement translation | Takes a structured description of an applied/industry project and runs a prompt chain: extract technical concepts → map to research primitives → frame as a research contribution tied to a specific target lab | Output labeled a draft, never "submission-ready"; will not fabricate project details the user didn't provide |
| Outreach Prep | Produces a prep card: one-line paper summary, 2–3 specific questions, a connection to the user's background, so the user writes their own email | Preps, does not ghostwrite. The agent draws its line at the email |
| Application Tracker (CRM) | Stores programs, deadlines, required documents, recommender status, and outreach log; answers "what's due this week?" and "have I followed up with Prof X?" | Every CRUD write requires explicit confirmation. Never infers or auto-updates a status |
| Funding & Requirement Flags | Scans indexed program pages for funding / stipend / GRE-waiver / IELTS signals and returns a structured flag summary with the source snippet each flag came from | Missing data is labeled "Not found in indexed content," never guessed |
| Memory | Captures durable facts about the applicant (interests, constraints, profile) automatically in the background after each turn, and surfaces them across sessions when relevant | Scoped to the authenticated user, retrieved by semantic relevance |
The whole interaction streams over the AG-UI protocol, so the frontend renders the agent's reasoning live, which sub-agent is active, which tool it called, what it retrieved, instead of a loading spinner. Approval gates appear inline in that stream as blocking cards.
How we built it
Brain / Logic / Superpower split: Gemini 3 is the brain, our backend owns the logic, and Elastic is the superpower. The deterministic plumbing (auth scoping, HITL persistence, cancellation, indexing, dedup) lives in code; the judgement lives in the agents.
Agent architecture (Google Cloud Agent Builder → exported to ADK)
The root agent classifies intent first (casual / ambiguous / actionable; it answers small talk itself instead of waking an expensive sub-agent), then routes down one of two deliberately separated branches: internal app-state work on one side, domain reasoning on the other. That split is the backbone, it keeps cheap CRUD cheap and saves the expensive reasoning models for work that needs them.
grad_paddy(root),gemini-3.1-flash-lite-preview. Intent classification, direct answers for casual turns, and routing. A date-awarebefore_agent_callbackinjects the current date so it reasons about deadlines correctly; abefore_model_callbackloads the user's context.
Branch 1, internal_app_agent (gemini-3.1-flash-lite-preview): the application layer. Owns all internal app-state operations, profile, preferences, shortlist, tracker, drafts, and HITL state, so they never go through an expensive model. It fans out to three specialists:
account_agent, user profile and preferences.application_agent, shortlist, tracker, and draft workflows.governance_agent, human-in-the-loop approval requests and their resolution.
Branch 2, domain_orchestrator_agent (gemini-3.1-pro-preview): the reasoning layer. Plans and delegates the multi-step domain work:
faculty_discovery_agentandfaculty_profile_deep_dive_agentongemini-3.1-pro-preview, the hard reasoning (research fit, paper synthesis, conversation angles).application_tracker_agent,funding_requirement_flag_detection_agent, andingestion_pipeline_agentongemini-3.1-flash-lite-preview, structured, lower-stakes work.- Plus a deep-research path (
planner/researcher) backed by Google Search and URL-context tools for verification.
Write actions funnel through a programmatic HITL chokepoint:
enforce_hitl_policy_callbackruns as abefore_tool_callbackon the write-capable agents (account_agent,application_agent,operations_agent, and theinternal_app_agentrouter), blocking anySENSITIVE_TOOLScall until a human approves it. We attach it to the leaf agents that hold the write tools because ADKbefore_tool_callbacks don't propagate from a router to its children. A prompt-level no-leak rule keeps internal agent and tool names out of user-facing text, so it reads as one assistant.
Three deliberate, complementary uses of Elastic
This is the core of our partner integration. We use each capability where it fits instead of forcing everything through one interface:
1. Agent Builder (MCP) for agentic discovery. The discovery agents drive the Elastic MCP server to run hybrid semantic + keyword retrieval over a corpus we index at runtime from user-provided URLs and queries. We expose it as a single shared-singleton McpToolset, so every agent reuses one client instead of spawning its own.
2. The grounded knowledge store, faculty-profiles and grad-programs. Ingested page content is chunked and indexed here. This is what makes "no answers from LLM memory" real: every result is retrieved, carries a source URL and date, and labels missing data rather than guessing.
3. A native semantic memory store, user-memories. The fact field is a semantic_text field whose embeddings are generated natively inside Elasticsearch by a Google Vertex AI inference endpoint, so we make zero embedding calls from our own code. Retrieval is hybrid semantic + BM25 with a recency boost. semantic_text erased almost all the custom vector code we'd otherwise have written.
Why memory is not an MCP tool
We first tried making save/search/delete-memory native MCP tools too, the tidy, symmetric choice. We pulled them back out for two reasons:
- An MCP search tool does one thing. Saving a memory well is multi-step: embed → find the nearest existing fact → conditionally update-in-place and merge tags, else insert. That branching can't live in a single Index/Search or ES|QL tool; forcing it onto MCP meant either a pointless webhook round-trip into our own backend or splitting it across tools and hoping the LLM sequences them right.
- MCP puts
user_idin the model's hands. As a tool argument,user_idis filled by the model, one hallucination or injection away from another user's memories. Elastic has no concept of our Firebase identity, so safe scoping would need per-user document-security keys: heavy plumbing for a hackathon.
Ingestion, the scraper that feeds Elastic
Discovery is only as good as what's indexed, so we built a Scrapy + Playwright spider (grad_program_spider) that crawls a university's program page through to its faculty listings, extracting deadlines, funding, faculty, and research focus; Playwright handles the JS-rendered pages a plain HTTP fetch would miss. Pages are chunked with LangChain's RecursiveCharacterTextSplitter, embedded, and indexed into Elasticsearch for the same hybrid search the agents use. The runtime ingestion_pipeline_agent reuses this path for user-provided URLs, so on-demand indexing and bulk crawling share one pipeline.
Production-grade Human-in-the-Loop
The default ADK/MCP pattern is a blocking ask_for_confirmation that holds a request thread open while a human decides, which times out and exhausts resources in a real backend. We treat HITL as an architectural pillar instead:
- A
LongRunningFunctionTool(request_hitl) writes a record to Firestore underusers/{user_id}/hitl/{hitl_id}. The backend stays stateless: the "pause" lives in a durable database, not an open thread. - The backend emits a structured
HITLRequiredEventover AG-UI, the frontend renders an Approval Gate card, and the run resumes when the user responds. - The root agent's instructions encode an explicit approval rule that forces the HITL tool to act as a security chokepoint before any create/update/delete.
The rest of the production plumbing
- Custom
FirestoreSessionServicebuilt on ADK'sBaseSessionService, because we persist sessions to Firestore, not a relational DB, as natively supported by ADK. - A multi-layer stop button: a queue decouples the Gemini stream producer from the event consumer, so cancellation has a clean landing point. A
/stopendpoint sets a stop event, cancels the drain and background ADK tasks, drops a sentinel on the queue, and deregisters the run. - Cost engineering:
flash-litefor high-volume and structured agents,proreserved for genuinely hard reasoning;include_thoughtsdisabled on low-stakes agents to avoid paying for thought tokens; ADK context compaction to summarize old session events, and context caching of large stable instructions on the discovery agents.
Design, neo-brutalism, on purpose
The frontend is a Next.js single-page app in a neo-brutalist design language: raw structure, high contrast, visible borders, bold type.
Access is gated behind Google sign-in; every memory, shortlist, and tracker record is scoped to the authenticated user, so a real identity has to exist before any per-user data does.
Challenges we ran into
Where memory should live was our hardest design call, and the one we're proudest of getting right. The full reasoning is in the Elastic section above; the upshot was pulling memory out of MCP into an in-process orchestration layer where user_id is read strictly from trusted session state (populated by our Firebase Auth middleware), so the agent is sandboxed to the current user by construction, not by prompt discipline.
Keeping a stateless backend honest under HITL. Holding a request open for minutes while a human approves doesn't survive a serverless runtime. We moved the pause into Firestore and the signal into AG-UI events, so the backend can forget the open thread and resume from durable state when the user responds.
Cancelling a live Gemini stream cleanly. A stop signal mid-stream can leave a zombie session, the UI shows "active" but the agent has stopped. Decoupling the producer from the consumer with a queue gave cancellation one deterministic landing point.
Calibrating deduplication honestly. Eyeballing the similarity threshold risked silently collapsing distinct facts, so we built a small harness, measured a real paraphrase pair (0.905) against unrelated facts, and set 0.88 from the data, documented to be re-measured if the embedding model changes.
Accomplishments that we're proud of
- A transparent agent via AG-UI over SSE. The whole multi-step run streams to the frontend as structured events, so the user watches the agent think instead of staring at a spinner, with approval gates rendered inline as blocking cards. Making multi-step reasoning legible to a non-technical applicant is a real UX win, not just a backend one.
- Cost engineering baked into the architecture.
proreserved for genuine reasoning,flash-litefor structured work, the root handling casual turns itself, with thought tokens disabled on low-stakes agents and ADK context compaction plus context caching on top. - A clean, intentional design language: neo-brutalism, chosen on purpose to make a dense, multi-panel agent app feel structured rather than overwhelming.
- A real multi-agent system, not one prompt in a trench coat. A root router, two purpose-separated branches (app-state vs. reasoning), and specialists underneath, with the trust boundary, HITL, and grounding all enforced in code via callbacks.
- Grounded by construction. Every factual output carries a source URL and date, fit scores are explicitly non-predictive, and missing data is labeled "not found" rather than invented.
What we learned
- Use each partner capability where it fits. The win wasn't routing everything through MCP, it was Agent Builder MCP for agentic discovery and Elastic as a semantic store, each doing what it's best at.
semantic_textmoved embedding into Elastic and deleted most of our vector code; branching orchestration that genuinely needs logic stayed in the backend. - The trust boundary belongs in code, not the prompt. Anything a hallucination or injection could weaponize, like whose data you read, must come from trusted state, not a model-filled parameter.
- Latency and statelessness are design materials. HITL only works in production if the pause is durable and the backend can forget about it.
- Augment, don't automate. Drawing hard boundaries (prep not ghostwrite, draft not submission-ready, match score not admissions probability) is what makes the agent trustworthy on a high-stakes, emotionally loaded task.
What this is NOT
We were deliberate about scope, because overclaiming on a high-stakes process destroys trust:
- Not an admissions oracle. Fit scores are indexed-content matches, never probability of getting in.
- Not a ghostwriter. It preps outreach; the user writes the email.
- Not autonomous. Every write and every real-world-facing output passes a human approval gate.
- Not a source of facts from memory. If it isn't in the indexed content, the agent says so.
- Out of scope by design: immigration/visa guidance, application-fee handling, GPA conversion, and recommender nudges to third parties, real problems, but ones that carry liability or require consent management beyond this MVP.
What's next for Grad Paddy
- Broaden the ingestion corpus and onboard more program/faculty sources, served faster as they're warehoused.
- Richer funding detection (fellowships, assistantships) with stronger source attribution.
- A weekly briefing agent that proactively surfaces what's due and what's gone stale.
- A counsellor/mentor-in-the-loop mode to validate draft outputs in a real application cycle.
Built With
- ag-ui
- cloud-storage
- elastic
- elastic-mcp
- fastapi
- firebase
- firestore
- gemini-3
- google-adk
- google-cloud-run
- google-oauth
- langchain
- next.js
- playwright
- scrapy



Log in or sign up for Devpost to join the conversation.