-
-
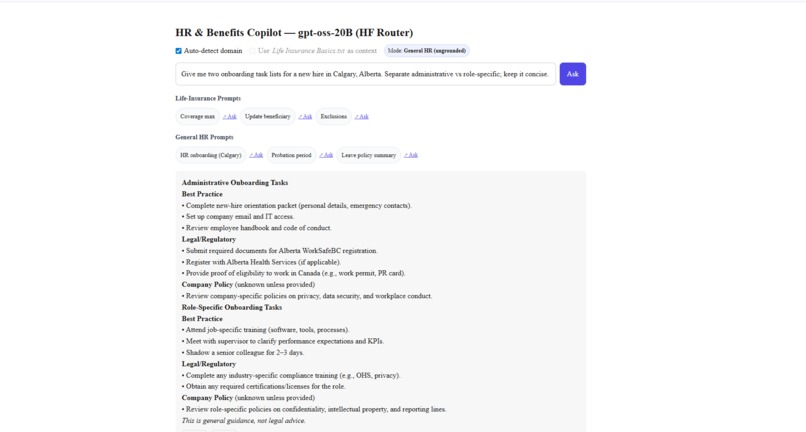
gptoss-demo image 1
-
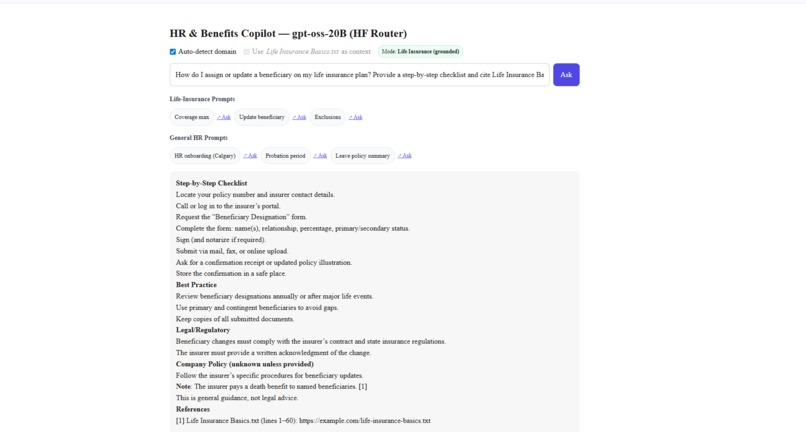
gptoss-demo image 2
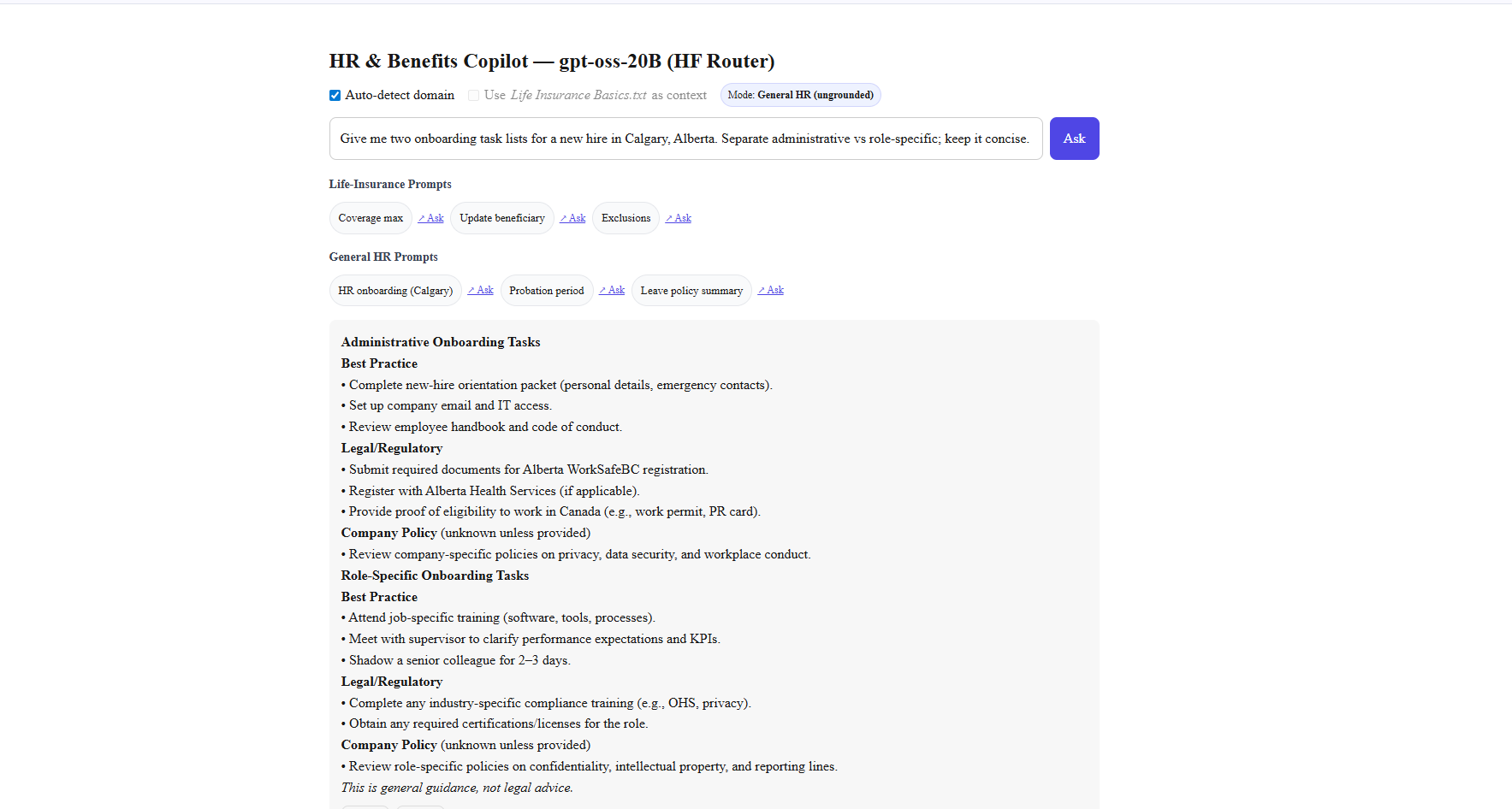
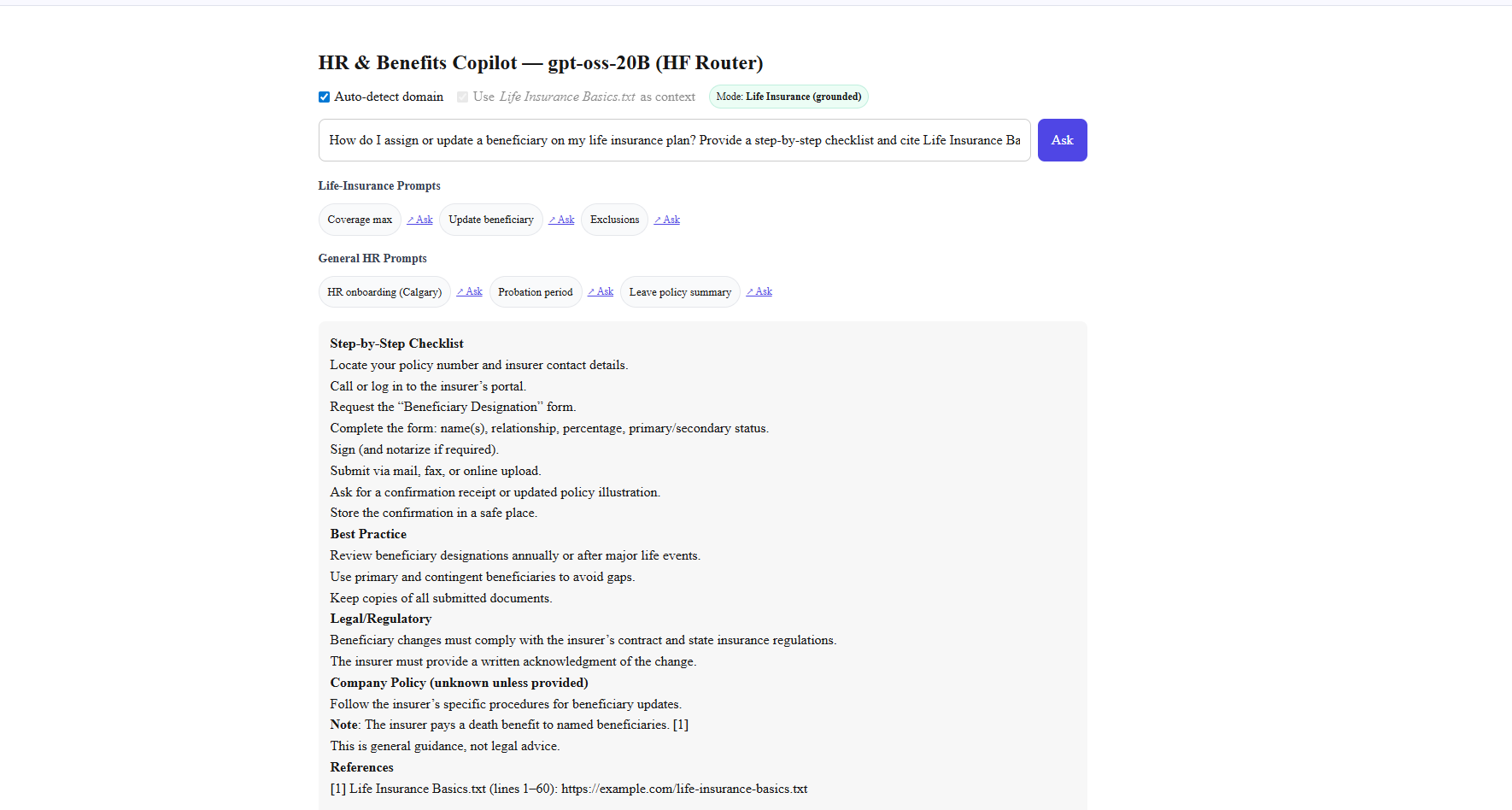
Inspiration
Enterprises struggle with fragmented knowledge sources (HR policies, compliance docs, regulations). Employees often waste time or make mistakes because AI tools are either closed-source, cloud-only, or lack governance. We wanted to show that open-source models like gpt-oss-20B can power enterprise-grade copilots that are private, compliant, and extendable.
What it does
gptoss-demo is a minimal copilot that: Answers HR, Occupational Health & Safety (OHS), and Human Rights questions. Switches automatically between general HR mode and Life Insurance–grounded mode. Uses a Hugging Face–hosted text file (Life Insurance Basics.txt) to provide referenced, cited answers. Runs on open-source GPT-OSS-20B via Hugging Face Router — no vendor lock-in. Provides a clean Next.js UI with sample prompts, auto-detected domain badges, and citation rendering.
How we built it
Frontend: Next.js (App Router) + React + ReactMarkdown for clean, markdown-rendered answers. Backend: Next.js API route (route.ts) that: Detects domain (HR vs Life Insurance). Fetches and chunks text from Hugging Face dataset. Builds context-aware prompts with citations. Calls Hugging Face Router (openai/gpt-oss-20b) for completions. Retries gracefully if responses are cut off. Deployment: Vercel for the web app + Hugging Face for dataset hosting.
Challenges we ran into
Handling long context and token cut-offs with 20B — solved with retry logic and excerpt clipping. Making responses cite excerpts correctly without leaking internal reasoning. Keeping responses under Vercel’s serverless timeouts (15s). Debugging Hugging Face provider suffixes (:fireworks-ai vs router auto-pick).
Accomplishments that we're proud of
Built a working multi-domain copilot demo in under hackathon time. Integrated open-source 20B model into a Next.js app without OpenAI’s closed stack. Automatic domain switching (HR ↔ Life Insurance) with context-based grounding. Clear UI with sample prompts and reference citations for transparency.
What we learned
Hugging Face Router sometimes returns only “reasoning_content” — you need retry logic and token caps to get stable answers. Chunking + scoring + clipping are essential for grounding large models with external files. Users/judges really appreciate transparency (references, disclaimers, mode badges).
What's next for gptoss-demo
Add multi-file ingestion (HR handbooks, safety manuals, contracts). Use a vector database (e.g., Supabase/pgvector) instead of naive chunk-scoring. Extend to Finance & Legal copilots under the same FluxCore architecture. Fine-tune GPT-OSS models with Canadian labor law corpora for SME compliance. Add enterprise features: SSO, audit logs, dashboards.

Log in or sign up for Devpost to join the conversation.