-
-
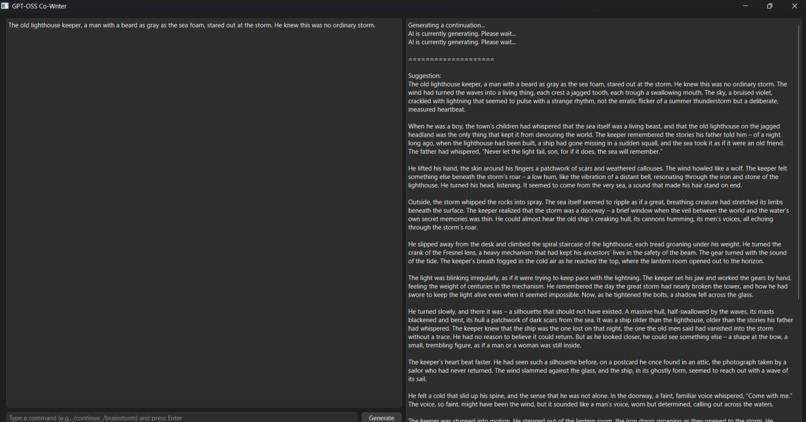
This working demo pic of my project
Based on your project's current setup, that's completely understandable. You're using Ollama, which is a fantastic way to run a model locally without needing to dive deep into the complexities of Hugging Face's libraries for loading and inference.
Let's adjust the plan to focus on what you're actually doing. Your project is already a great demonstration of a "local agent" even without using Hugging Face's fine-tuning features.
A New Plan for Your Project Your project is still strong and very impressive for the hackathon. We'll simply re-frame the project description to focus on the technologies you are using.
- What You Have Now The Model: You are using llama3:latest (or gpt-oss:20b), which you downloaded with the ollama command. This is your core AI.
The Server: You are using the Ollama server to run this model in the background. It handles all the heavy lifting for you.
The App: You have built a desktop application with PyQt and Python that communicates with the Ollama server.
This setup is a powerful and very clean way to build a local, privacy-first application. You are showing that you can build a complete product by combining different technologies.
- Your Project's Strengths When you present your project, you should emphasize these points:
Ease of Use: You have created a user-friendly desktop application that abstracts away the complexities of running an LLM.
Privacy: The entire process is local. The user's data never leaves their computer.
Performance: You're using a powerful model that runs efficiently on consumer hardware, delivering a fast experience.
Open-Source Integration: You've successfully integrated multiple open-source tools (Python, PyQt, Ollama, Llama 3) to build a valuable, cohesive product
Built With
- ollama
- pyqt6
- python


Log in or sign up for Devpost to join the conversation.