-
-
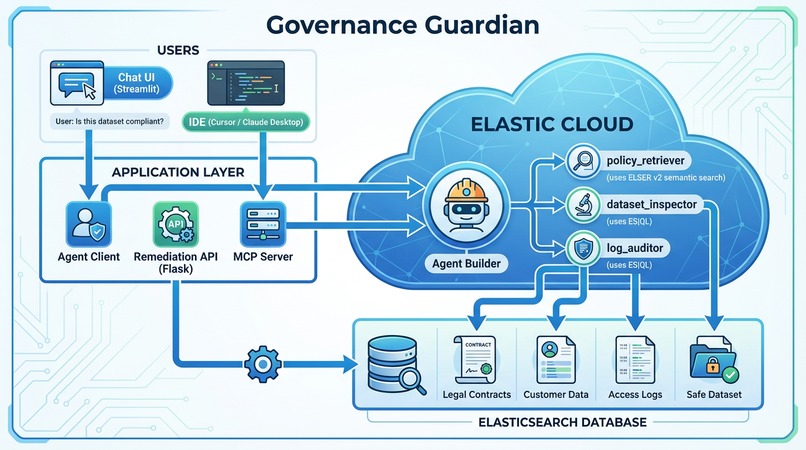
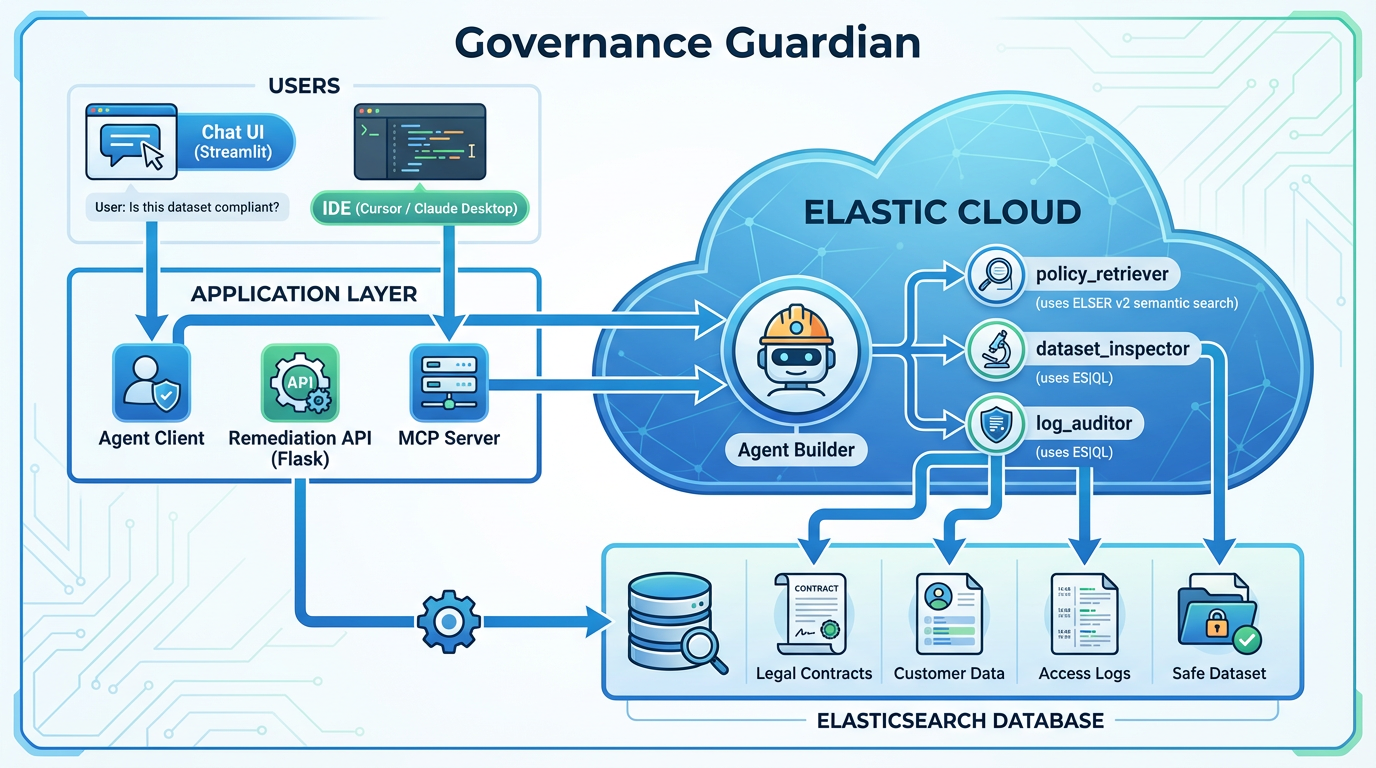
Governance Guardian: High level Architecture
Brief Description (~400 words)
In modern data-driven organizations, there is massive friction between data teams and legal/compliance. A data scientist wanting to use a dataset (e.g., for an email campaign) must wait days for a compliance officer to manually review complex regulatory policies (GDPR) or client contracts (NDAs) to ensure the dataset is safe to use. This bottleneck kills agility. Governance Guardian solves this by acting as an automated "Level 1 Compliance Officer," turning a multi-day legal review into a 30-second automated check.
Governance Guardian is a multi-step AI agent built on Elastic Agent Builder. It leverages the power of Elasticsearch for both unstructured and structured data analysis:
- Semantic Search with ELSER v2: We use Elastic's Learned Sparse EncodeR (ELSER v2) to semantically index and search through dense legal PDF contracts and compliance policies (
legal-knowledge-base). - Structured Data Inspection with ES|QL: We use Elastic's pipelined query language (ES|QL) to dynamically query and aggregate the actual production datasets (
customer_leads_prod) in real-time. - Tool Orchestration: The Agent Builder is configured with custom tools. The reasoning model autonomously decides when to read the rules, inspect the data, run remediation, or audit logs.
- Action-Taker (Webhook + ES|QL): A remediation API (triggered via the Streamlit UI) executes a safe ES|QL query and reindexes compliant records into a new index (
customer_leads_safe). The agent doesn't just advise—it creates the safe dataset with a preview of filtered rows. - Time-Series Auditor: A
log_auditorES|QL tool queries the access logs with time bucketing to detect compliance breaches. - IDE Compliance Copilot: We expose the agent as an MCP server with a
check_compliancetool, so data engineers can ask compliance questions from Cursor/Claude Desktop.
Features we liked: The seamless integration of ES|QL within Agent Builder. Giving an LLM the ability to execute pipelined aggregations against live data is incredibly powerful—it bridges the gap between hallucinated answers and grounded reality. We also loved how easy ELSER v2 was for out-of-the-box semantic search.
Challenges: Our main challenge was tuning the agent's system prompt to ensure it reliably executed both tools for complex queries rather than relying on general knowledge. We overcame this by strictly instructing the agent to always use dataset_inspector before approving data usage. We also worked around Kibana API limits (no Webhook tool creation) by building the remediation trigger directly into our Streamlit UI.
Inspiration
In most companies, there’s a huge friction point between data teams and legal/compliance. A data scientist or marketing manager wants to use a dataset (e.g., for an email campaign), but they have to wait days for a compliance officer to manually review contracts (NDAs, MSAs, GDPR, CCPA) and check the actual data. That bottleneck kills speed and agility. We wanted to turn that multi-day legal review into a single chat: one agent that reads the rules, inspects the data, and either approves, denies, or creates a safe dataset—all in under a minute.
What it does
Governance Guardian is an AI compliance officer that acts as an automated “Level 1” check before anyone uses a dataset. You ask in plain language: “Can I use customer_leads_prod for email marketing?” or “What’s our policy on emailing minors?” The agent:
- Retrieves policy from your legal knowledge base using semantic search (ELSER v2) and cites the exact clause.
- Inspects the data in real time with ES|QL—counting minors, restricted regions, or other risk factors—and approves or denies with actual numbers.
- Remediates by generating a safe ES|QL query and, at the click of “Run remediation now,” creating a new index (
customer_leads_safe) with only compliant rows, plus a preview table in the UI. - Audits access logs over time (“Have there been any compliance breaches in the last 7 days?”) using time-series ES|QL.
- Lives in your IDE via an MCP server: data engineers can ask “Is this query compliant?” from Cursor or Claude Desktop without leaving the editor.
One agent, policy plus data plus action plus audit—in one chat.
How we built it
We built Governance Guardian on Elastic Agent Builder and Elasticsearch:
- ELSER v2 (Elastic Learned Sparse EncodeR) for semantic search over legal contracts and policies in a
legal-knowledge-baseindex. - ES|QL for structured data: custom tools
dataset_inspector(live risk counts oncustomer_leads_prod) andlog_auditor(time bucketing and aggregations ondata_access_logs_prod). - Agent Builder for tool orchestration: the reasoning model chooses when to call
policy_retriever,dataset_inspector, and optionally remediation or audit tools. - Remediation API (Flask): our Streamlit app calls it when you click “Run remediation now”; it runs a safe ES|QL query and bulk-indexes compliant records into
customer_leads_safe, and we show a “Preview: filtered safe dataset” table. - MCP server (FastMCP): exposes a
check_compliancetool that forwards queries to the same Agent Builder agent, so Cursor/Claude Desktop users get the same compliance checks inside the IDE. - Streamlit for the chat UI, Python for ingestion scripts, pytest for unit, integration, and E2E tests.
Challenges we ran into
- Getting the agent to use both policy and data: Initially it sometimes relied on general knowledge instead of inspecting the dataset. We fixed this by tightening the system prompt and tool descriptions so the agent always uses
dataset_inspectorbefore approving data usage and always citespolicy_retriever. - No Webhook tool type in the Kibana API: The Agent Builder API supports
esql,index_search,workflow, andmcp—but not Webhook. We couldn’t create a Webhook tool via API for remediation. We worked around it by adding a “Run remediation now” button in Streamlit that calls our remediation API directly and displays the safe-dataset preview, so the demo still shows “we didn’t just suggest—we created the safe dataset.”
Accomplishments that we're proud of
- One agent, end-to-end: Policy retrieval (ELSER v2), live data inspection (ES|QL), remediation (ES|QL + API + preview), and time-series audit (ES|QL) in a single conversational flow.
- Grounded answers: The agent denies or approves using real counts from the cluster, not generic advice—bridging the gap between LLM answers and actual data.
- Action, not just advice: Clicking “Run remediation now” creates
customer_leads_safeand shows a preview table of compliant rows. - Compliance in the IDE: MCP server so developers can run the same compliance checks from Cursor or Claude Desktop without switching context.
What we learned
- ES|QL inside Agent Builder is powerful: giving the LLM the ability to execute pipelined queries against live data turns “maybe” into “here are the exact numbers.”
- ELSER v2 was straightforward to set up for semantic search over legal text without managing a separate vector store.
- Tool orchestration is as much about prompt and tool descriptions as it is about the tools themselves—small wording changes made the agent much more reliable.
- Platform limits (e.g., no Webhook in the API) can be worked around in the app layer (Streamlit button + remediation API) without losing the demo story.
What's next for Governance Guardian
- More data sources: Connect to CRM, data catalogs, or PII scanners so the agent can reason over a broader set of assets.
- Embed where work happens: Deploy the same agent via Slack, email, or ticketing so compliance checks happen in existing workflows.
- Multi-step remediation workflows: Trigger approval chains or data-masking pipelines when the agent flags high-risk usage.
- Stronger MCP integration: Richer code-context passing so “Is this query compliant?” uses the actual query or pipeline the developer is writing.
Links for submission
- Demo video (~3 min): https://youtu.be/vwjl4Ws4UGo
- Source code (public, MIT): https://github.com/prkshverma09/GovernanceGuardian

Log in or sign up for Devpost to join the conversation.