-
-
Slide 1 - Intro
-
Slide 2 - What's CI/CD
-
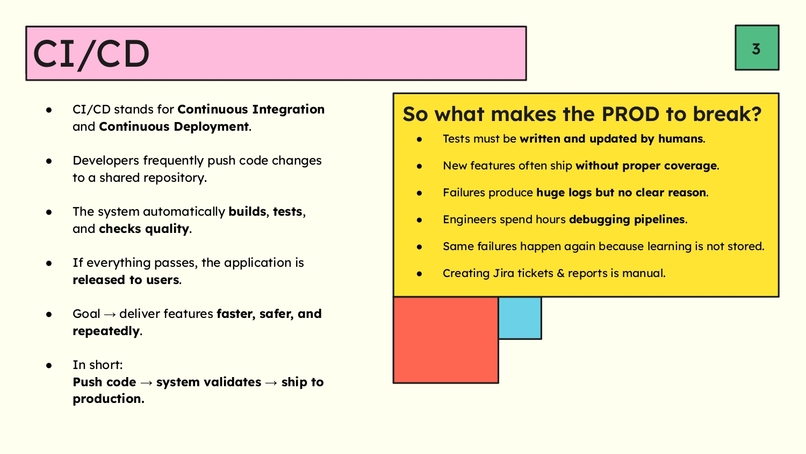
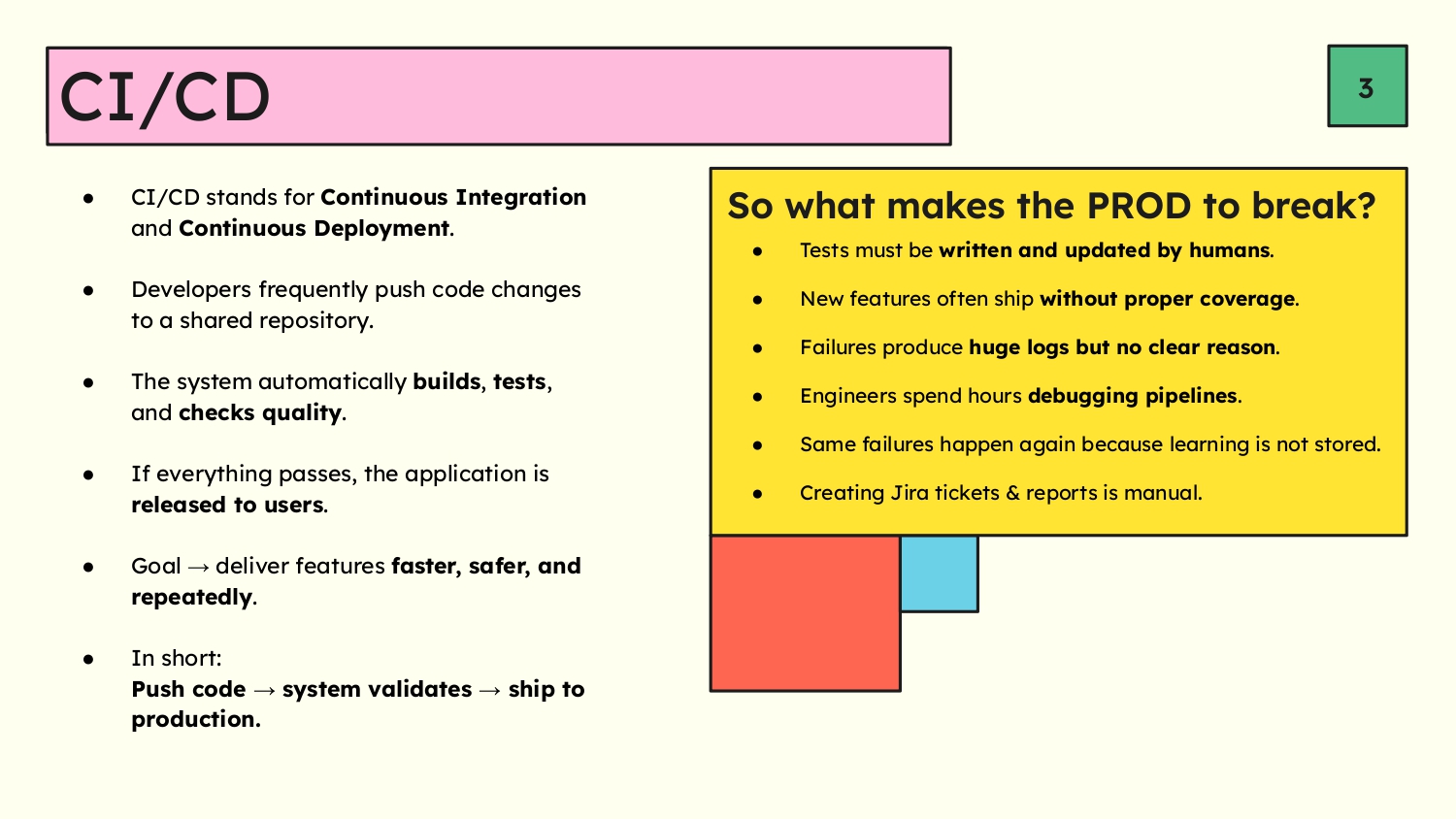
Slide 3 - CI/CD and Current Problems
-

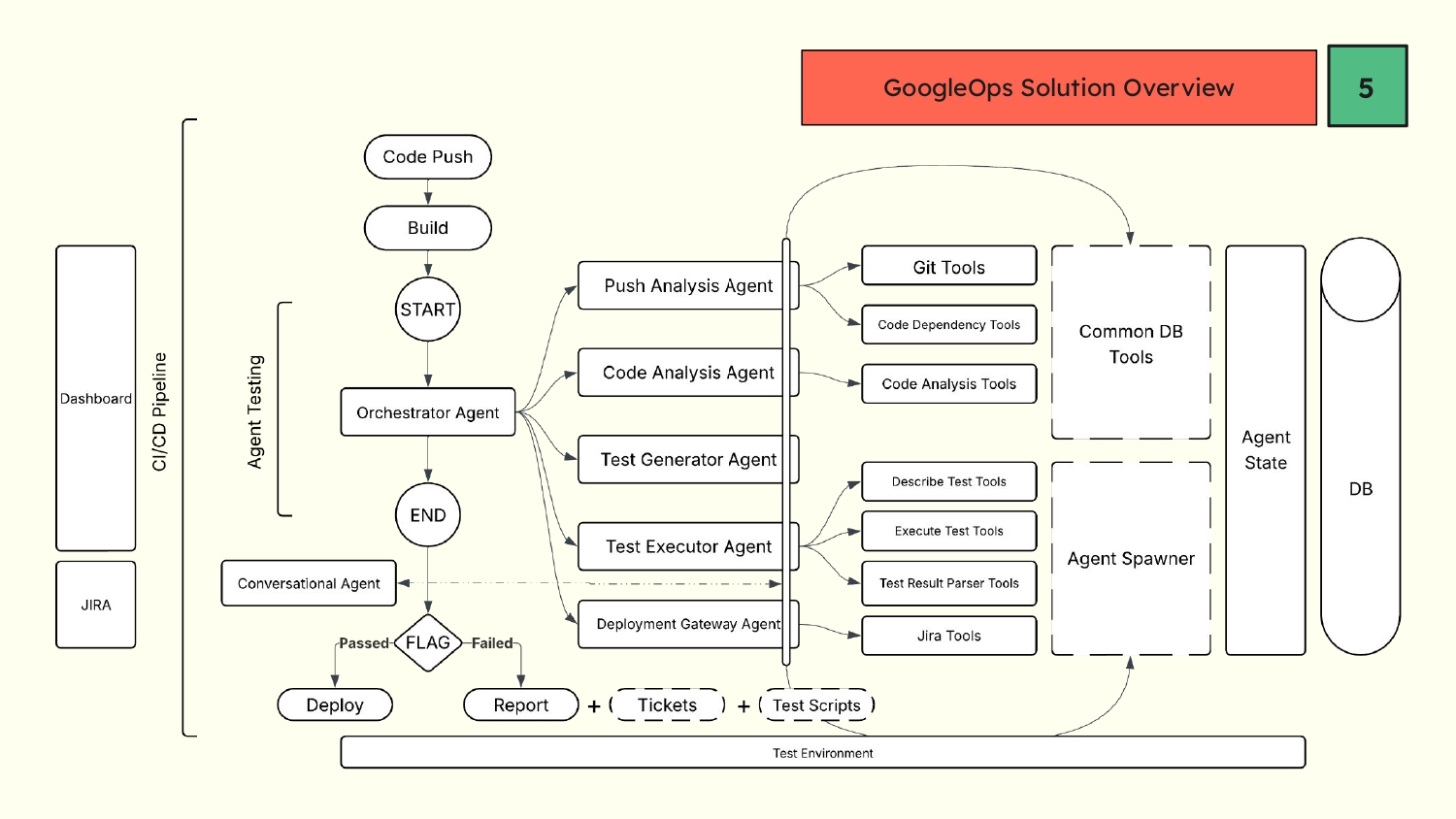
Slide 4 - My Solution
-
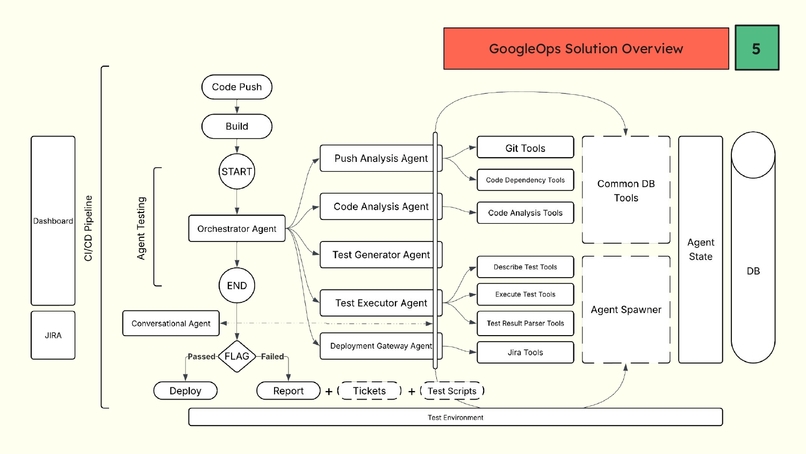
Slide 4- Architecture Overview
-
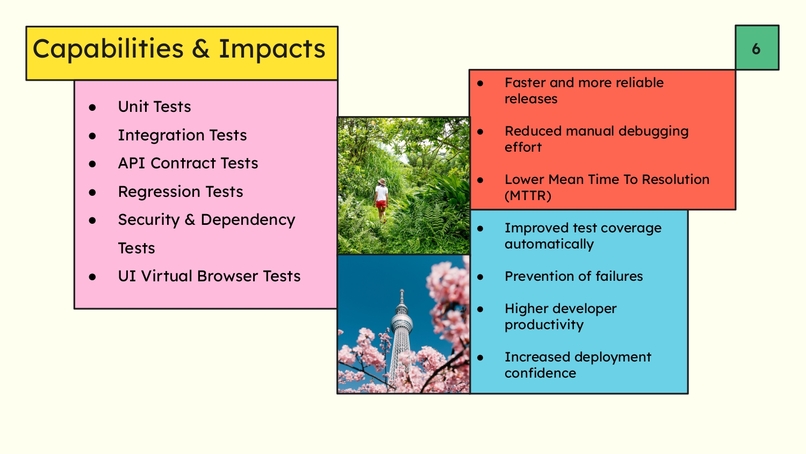
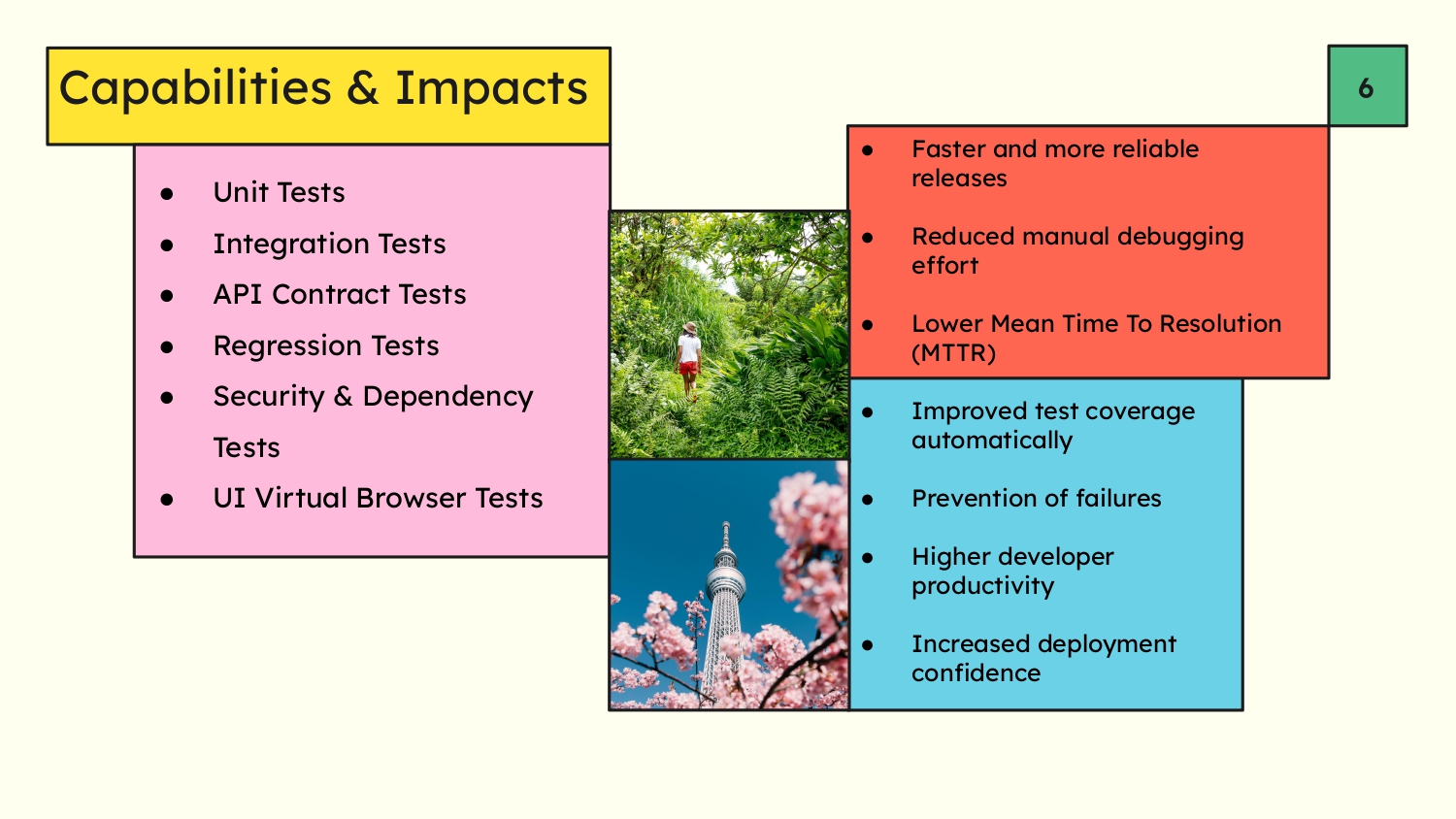
Slide 5 - Capabilites & Impacts
-
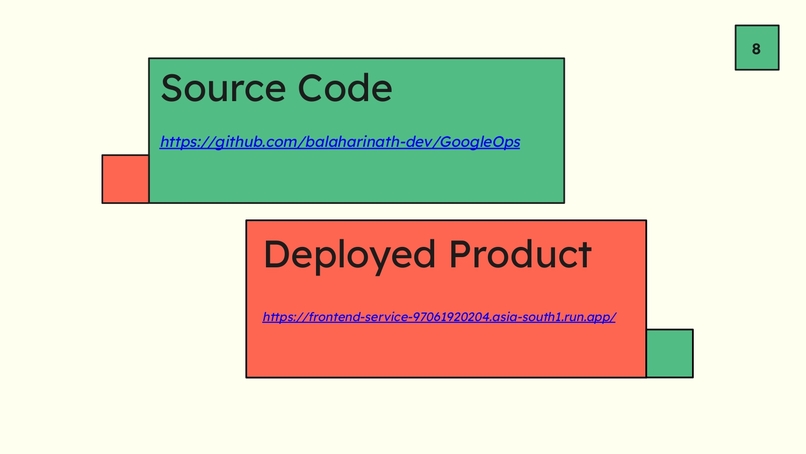
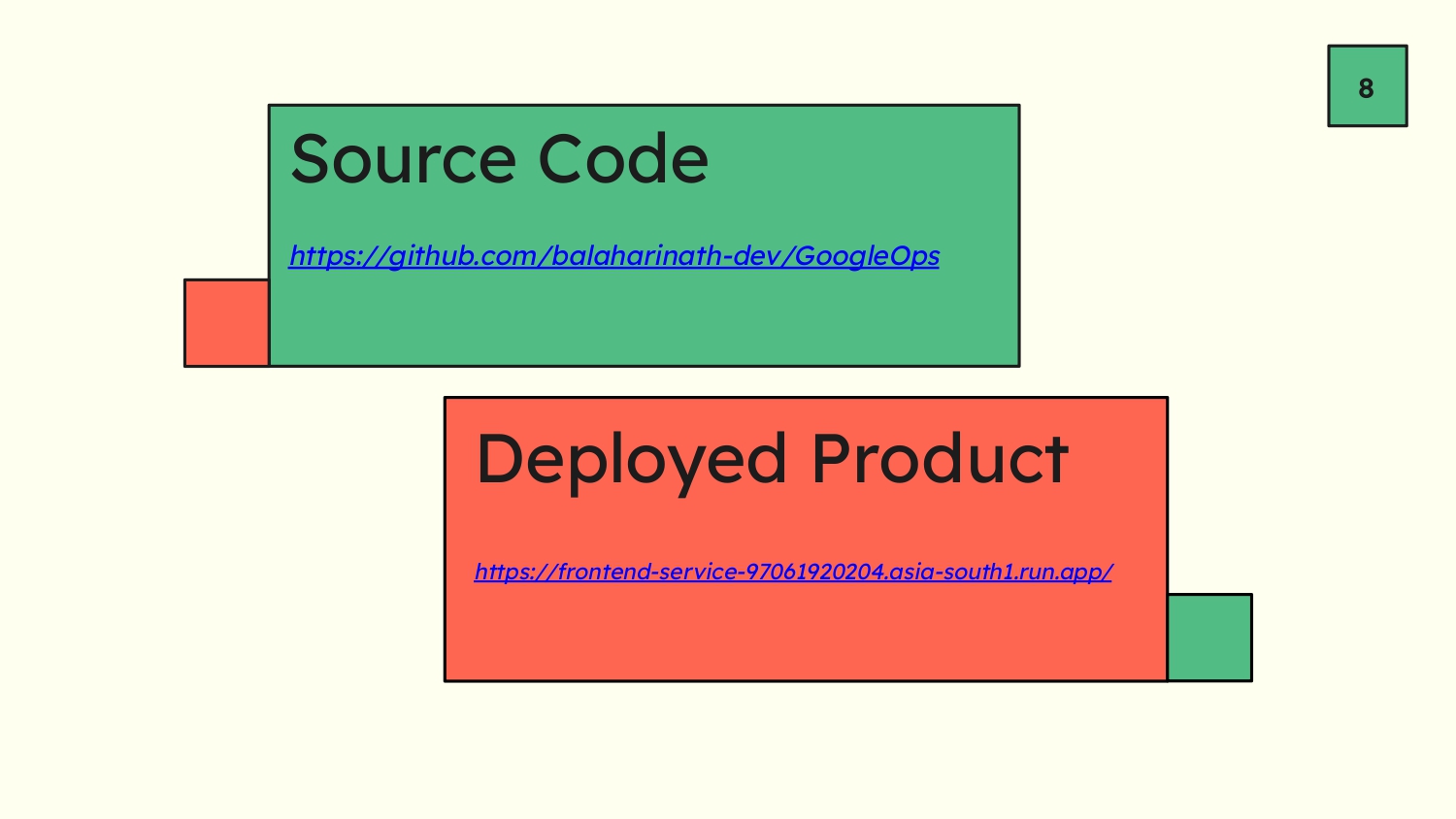
Slide 6 - Source Code & Deployed Product Links
-

Slide 7 - Future Implementation
-

Slide 8 - Outro
-
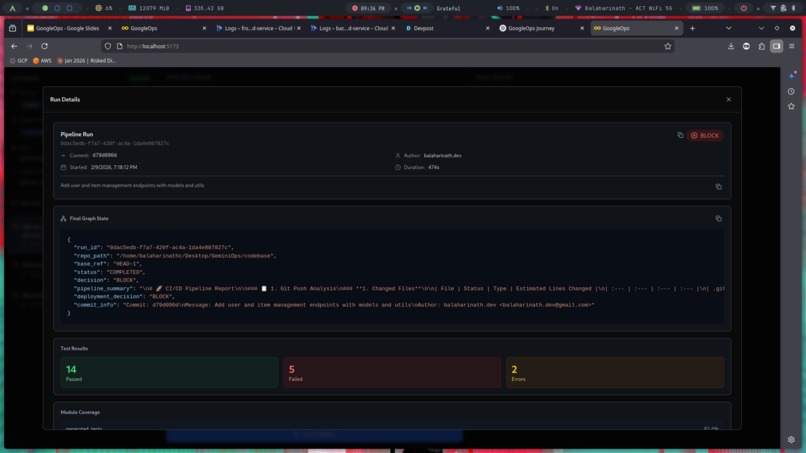
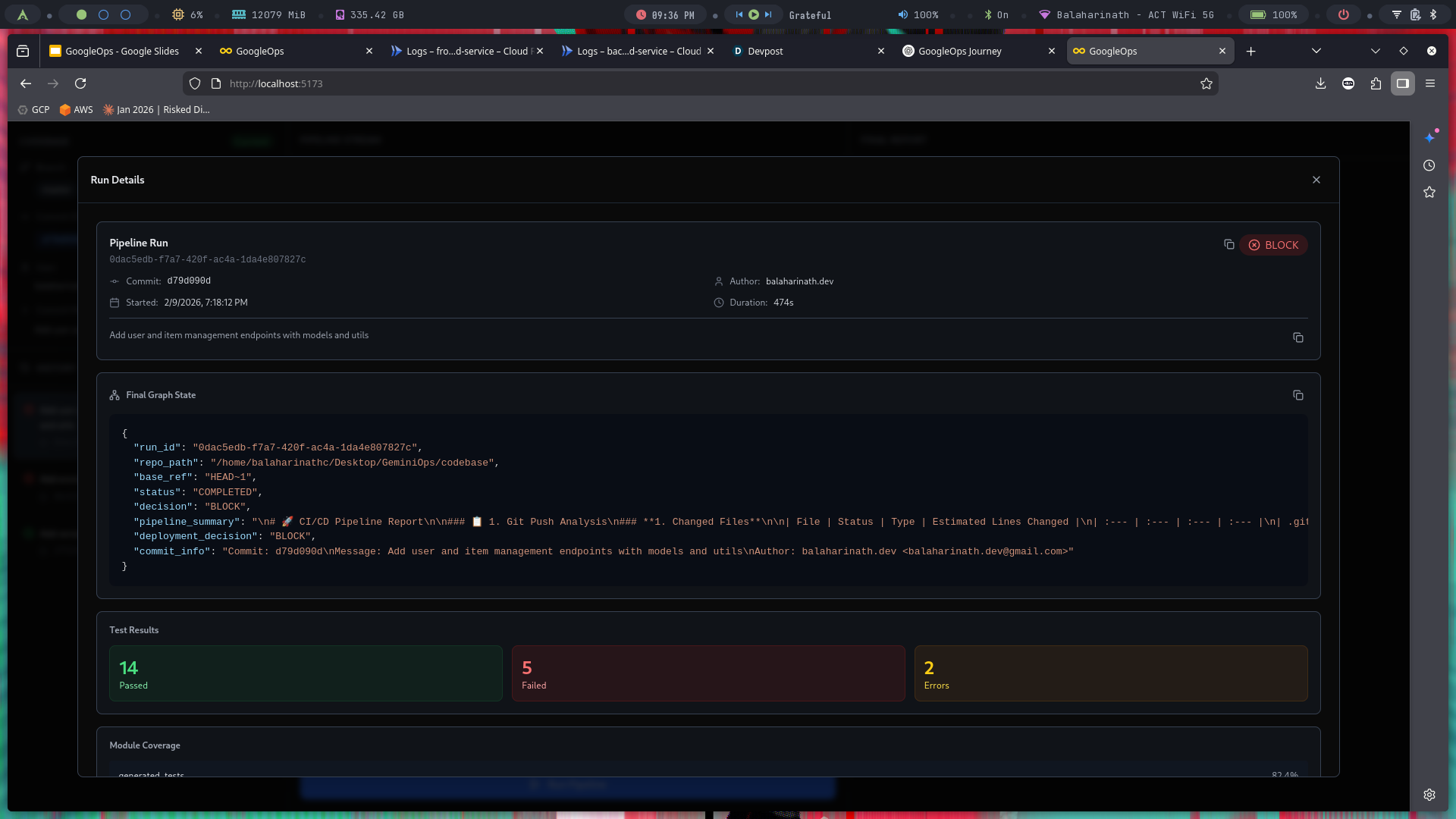
Final Agent Pipeline Result
-
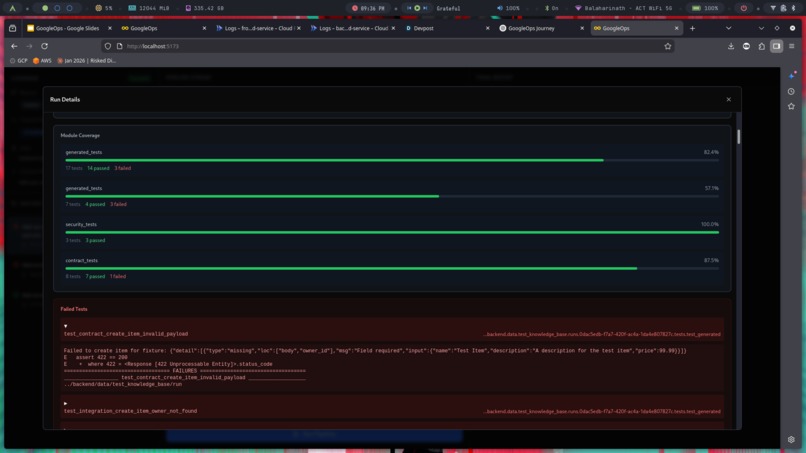
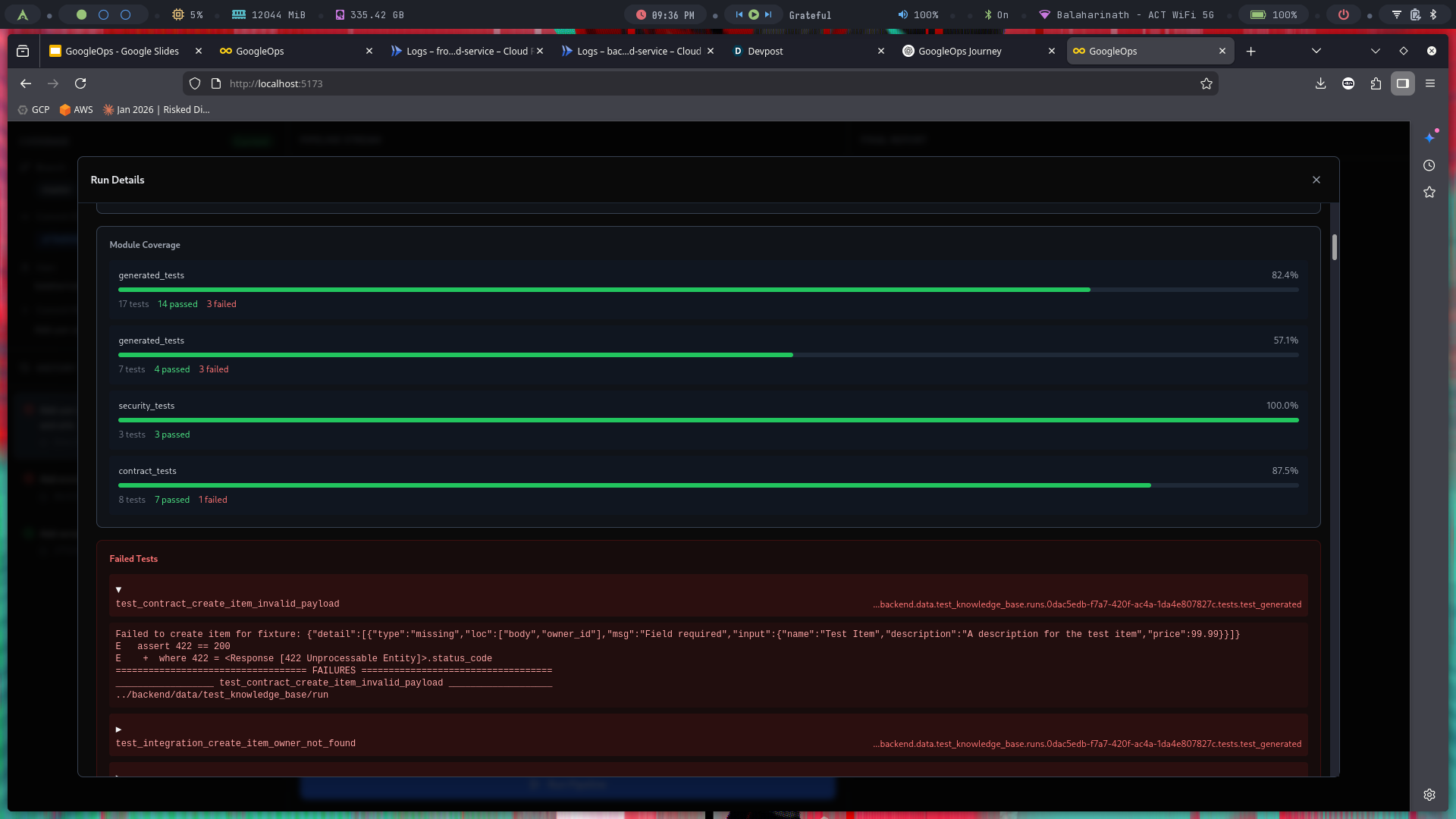
Tests Conducted
-
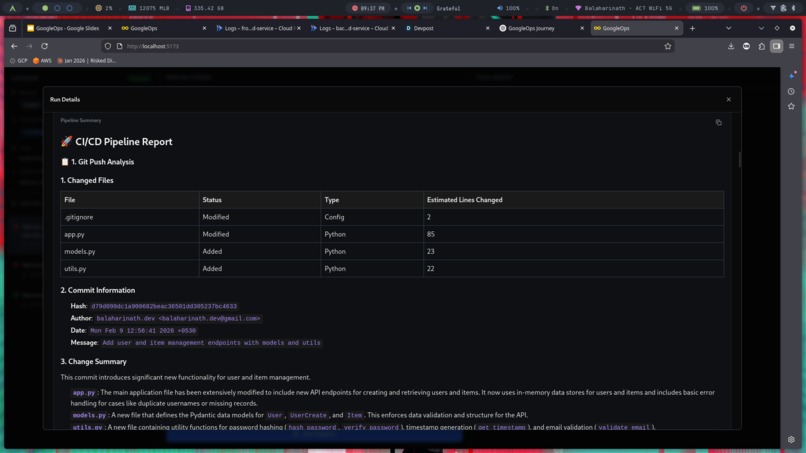
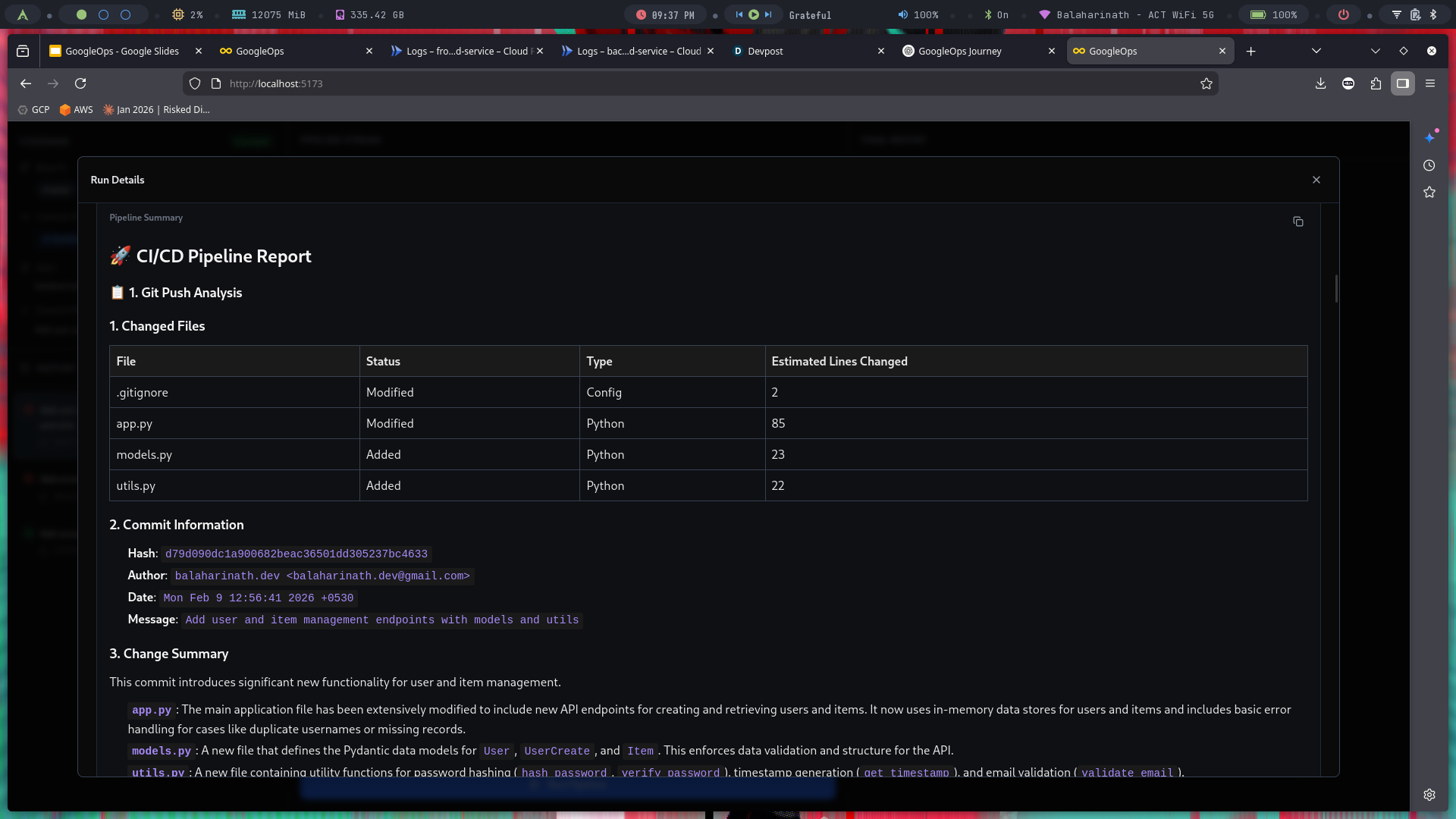
Generated Report
-
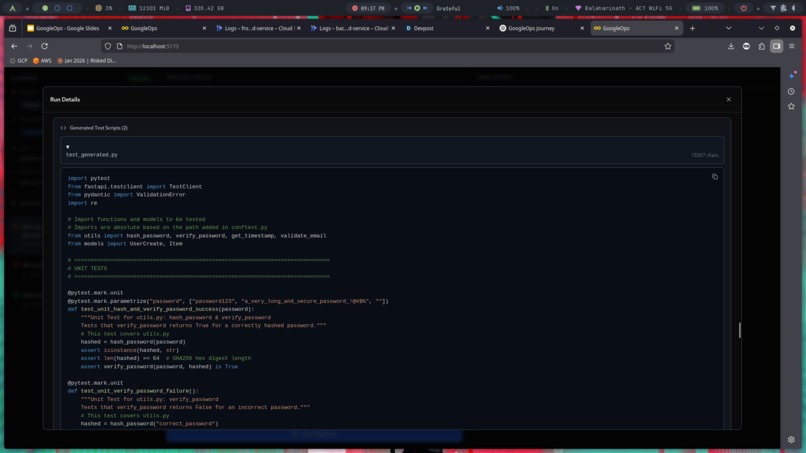
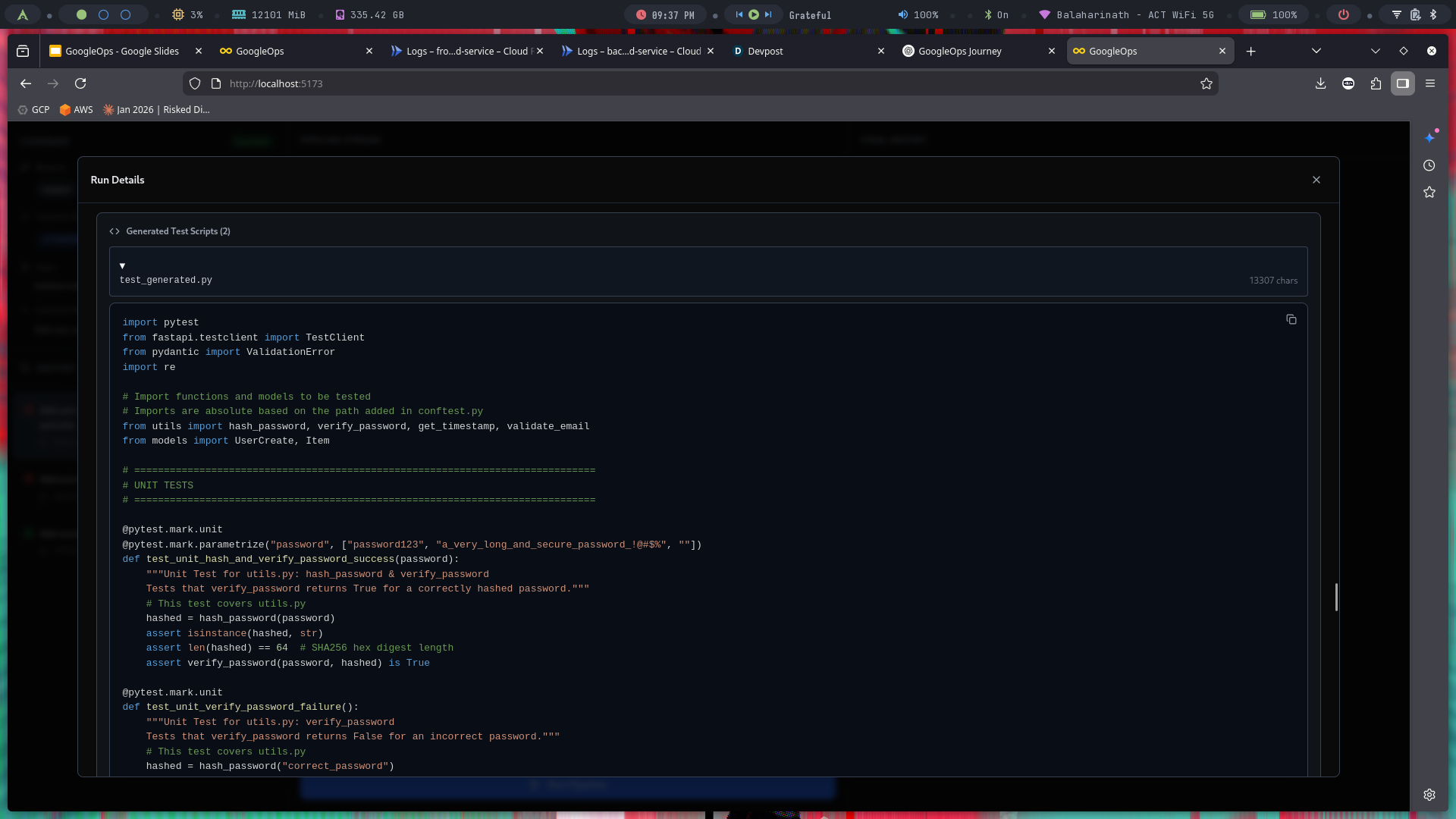
Generated Test Scripts



My GoogleOps Journey: From Manual Reviews to Autonomous Quality Assurance
Inspiration
In the fast-paced world of modern software development, speed is currency. But speed often comes at the cost of quality.
I noticed a recurring bottleneck in workflows: the time gap between pushing code and verifying its correctness. Traditional CI/CD pipelines run pre-defined tests, but they are static. They don't understand the code — they just execute it.
I asked:
What if I could embed a senior QA engineer directly into the pipeline? An entity that reads the code, understands the intent, and writes targeted tests on the fly?
That was the genesis of GoogleOps.
What it does
GoogleOps is an autonomous AI agent that integrates into the CI/CD pipeline. It:
- Analyzes Code Changes – Reads Git diffs to understand the context and scope of modifications.
- Generates Tests – Uses LLMs to write targeted unit & integration tests.
- Executes & Validates – Runs generated tests inside a sandbox.
- Enforces Quality Gates – Makes a data-driven GO / NO-GO deployment decision.
How I built it
I built GoogleOps using a modular, agentic architecture.
Backend → Python + FastAPI Agent Orchestration → LangChain + LangGraph Frontend → React (real-time streaming) Database → SQLite
1) The Brain (LangGraph)
I modeled the CI/CD workflow as a directed execution graph. Each node is a specialized agent.
- Push Analyzer → Extracts commit metadata & changed files
- Code Analyzer → Performs static reasoning on logic updates
- Test Generator → Prompts the LLM to produce pytest-compatible tests
- Test Runner → Executes tests & captures logs
- Deployment Gate → Final approval authority
2) The Frontend (React)
To make AI decisions transparent, I built a live dashboard.
It streams:
- agent steps
- reasoning
- retries
- pass/fail outcomes
via Server-Sent Events (SSE).
Users can literally watch the brain think.
3) Persistence (SQLite)
I store:
- pipeline runs
- generated tests
- execution logs
- approval history
This ensures auditability and allows long-term quality tracking.
Challenges I ran into
Hallucinations in Code Generation
Early versions wrote plausible but non-executable code (for example, importing libraries that don’t exist).
Solution: I built a feedback loop. Execution errors are returned to the Test Generator, allowing the agent to retry with corrections.
State Management
Passing diffs, logs, and code between agents became heavy.
Solution: I passed summaries and references, while storing large artifacts externally.
Determinism
I needed consistent GO/NO-GO decisions.
Solution: Structured prompts combined with rule-based evaluation criteria.
Accomplishments I'm proud of
- True End-to-End Autonomy – Commit → analysis → tests → decision, without human intervention.
- Real-Time Brain Visualization – The execution graph runs live on screen.
- Self-Healing Capabilities – Detects broken tests and retries automatically.
What I learned
Context is King
Raw diffs are not enough. Structured, summarized inputs dramatically improve accuracy.
Agentic Workflows are better than single prompts
Divide-and-conquer strategies outperform monolithic instructions.
Feedback Loops enable autonomy
Letting the agent observe results, retry, and improve is essential.
What's next for GoogleOps
I plan to:
- Integrate with GitHub Actions
- Support languages beyond Python
- Build a Fix-It Agent that automatically proposes patches

Log in or sign up for Devpost to join the conversation.