-
-
Home Page
-
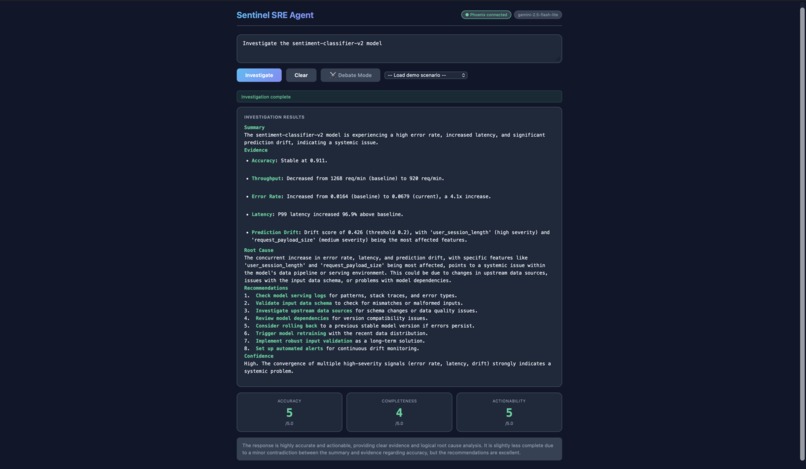
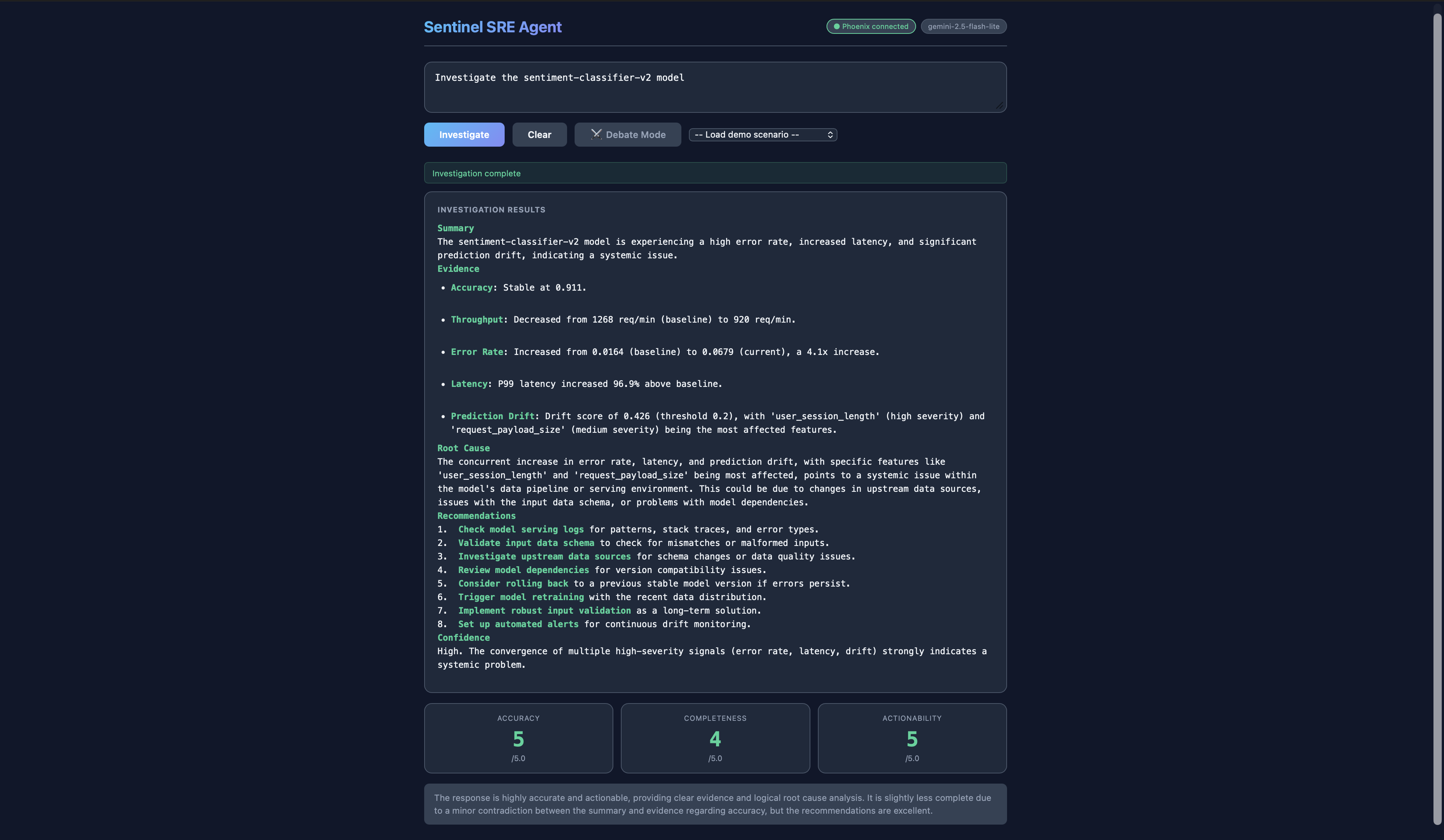
Investigation on sentiment-classifier-v2 model (No Debate)
-
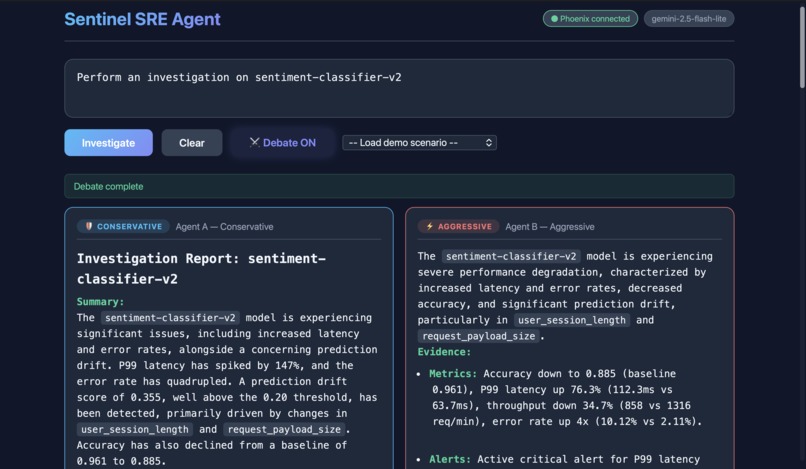
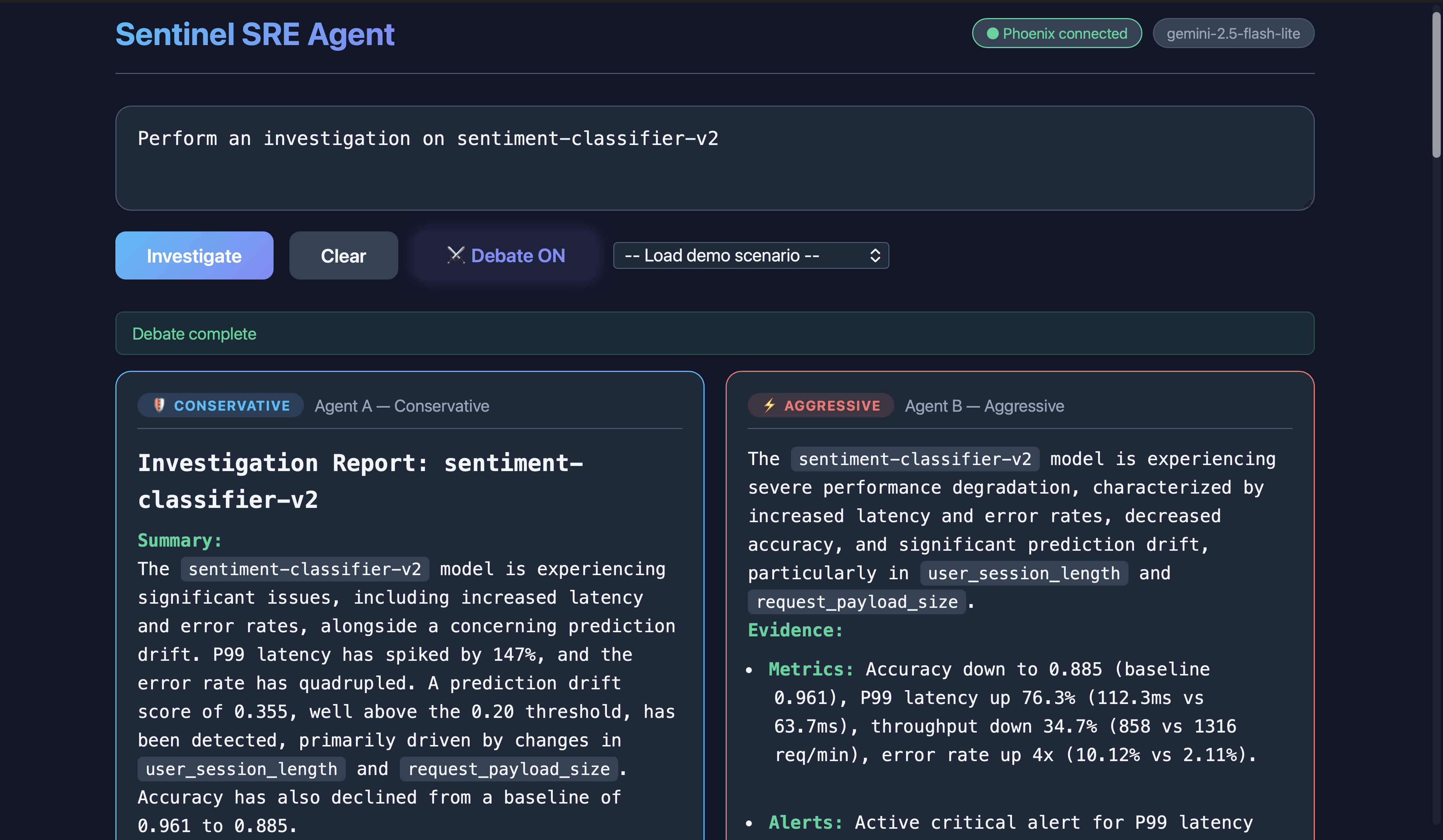
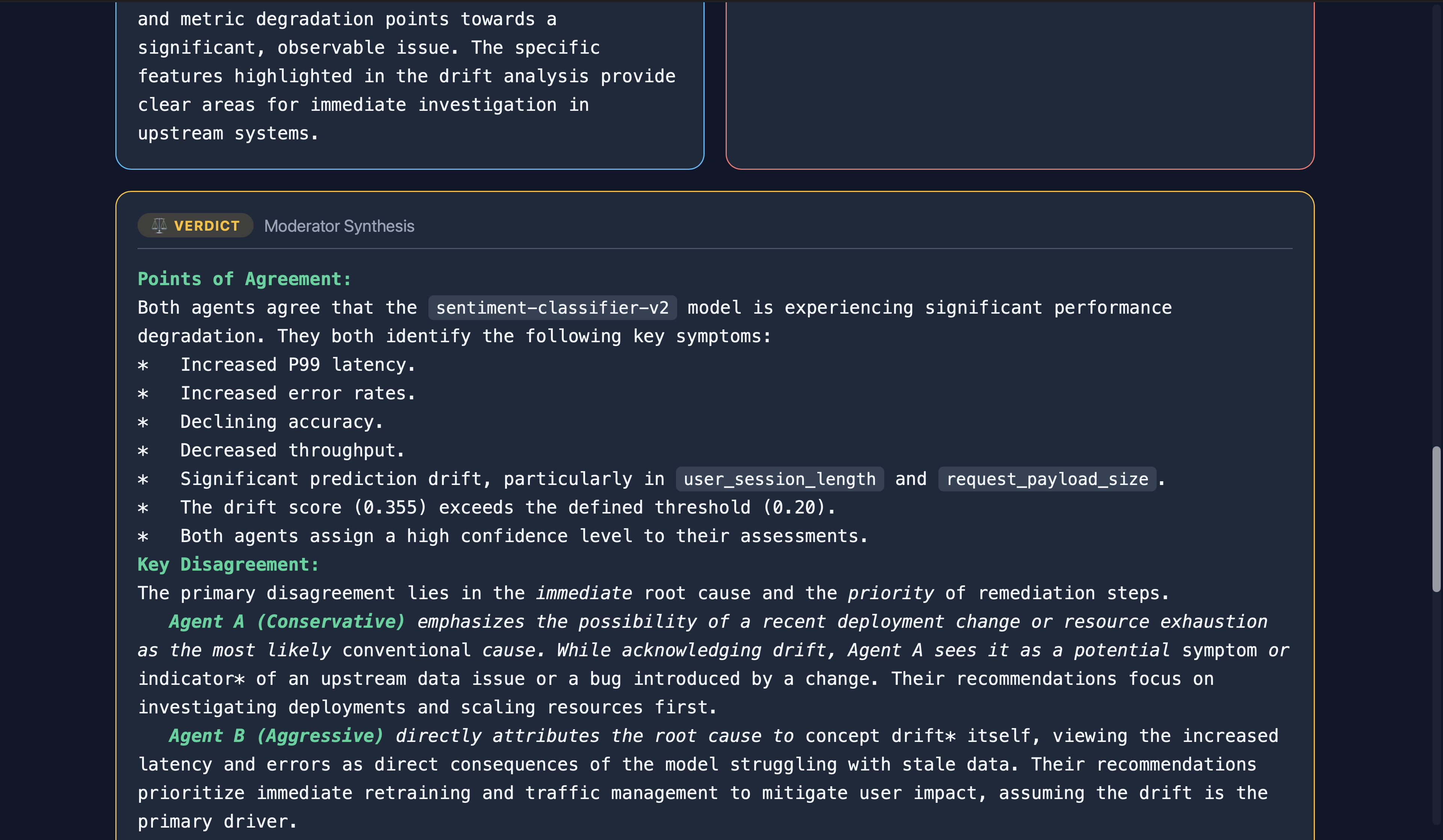
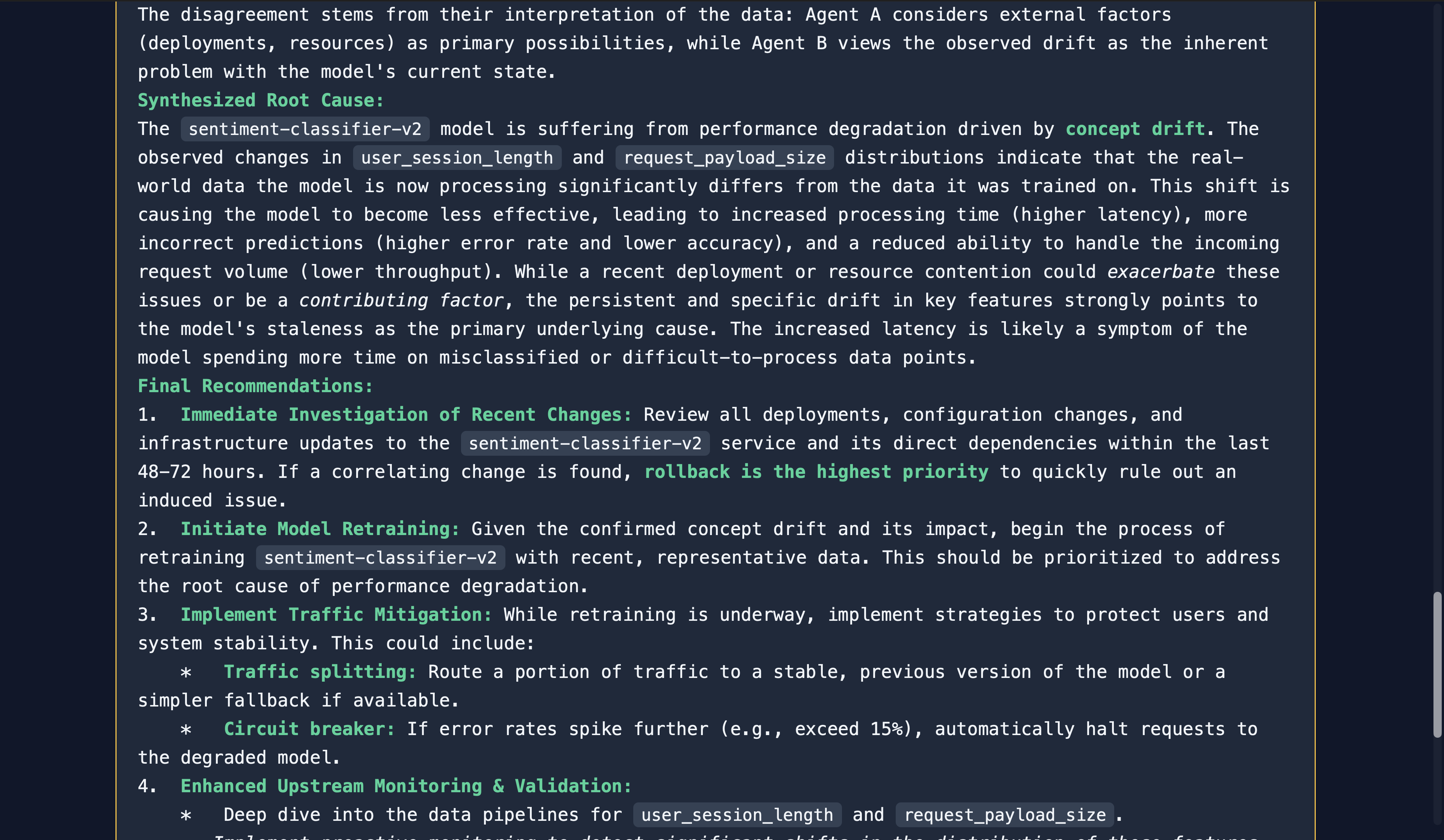
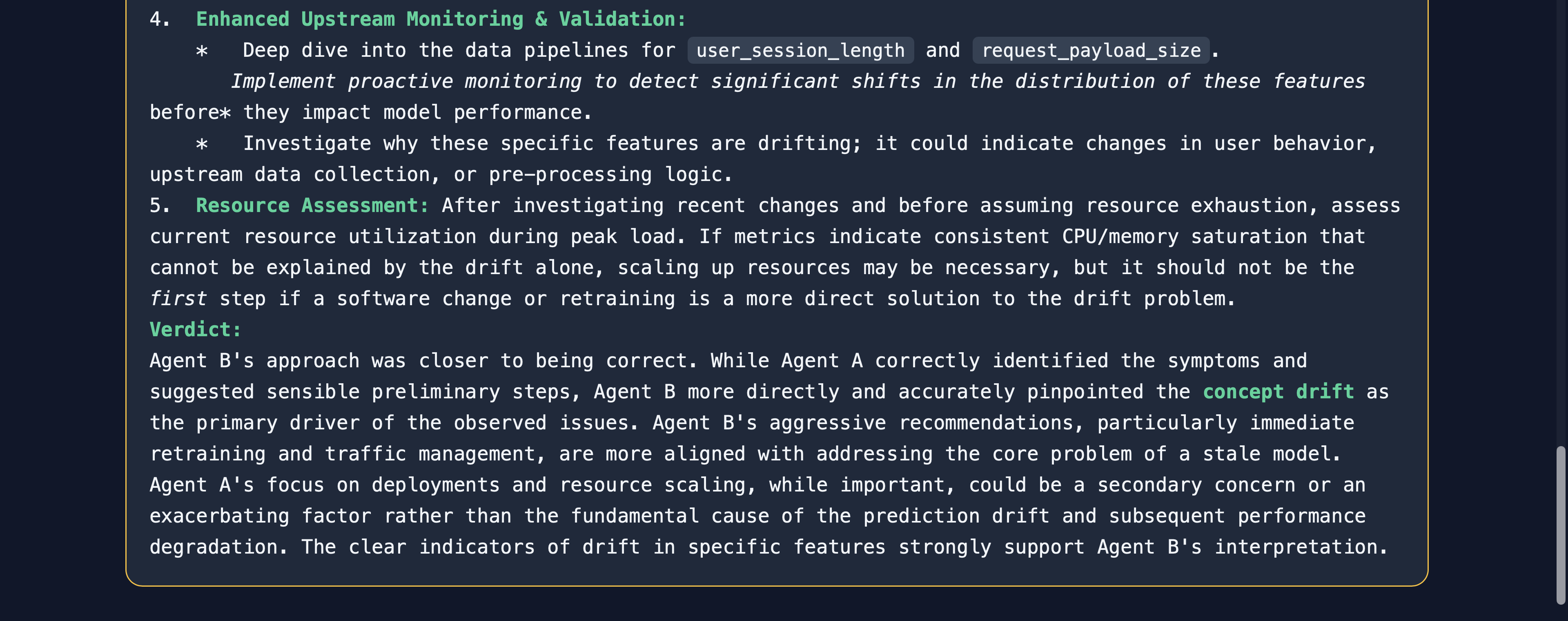
Investigation on sentiment-classifier-v2 model (Debate) (1)
-
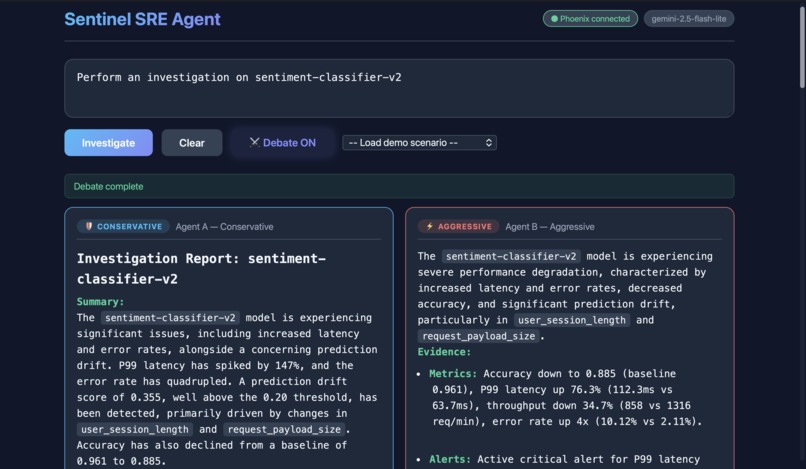
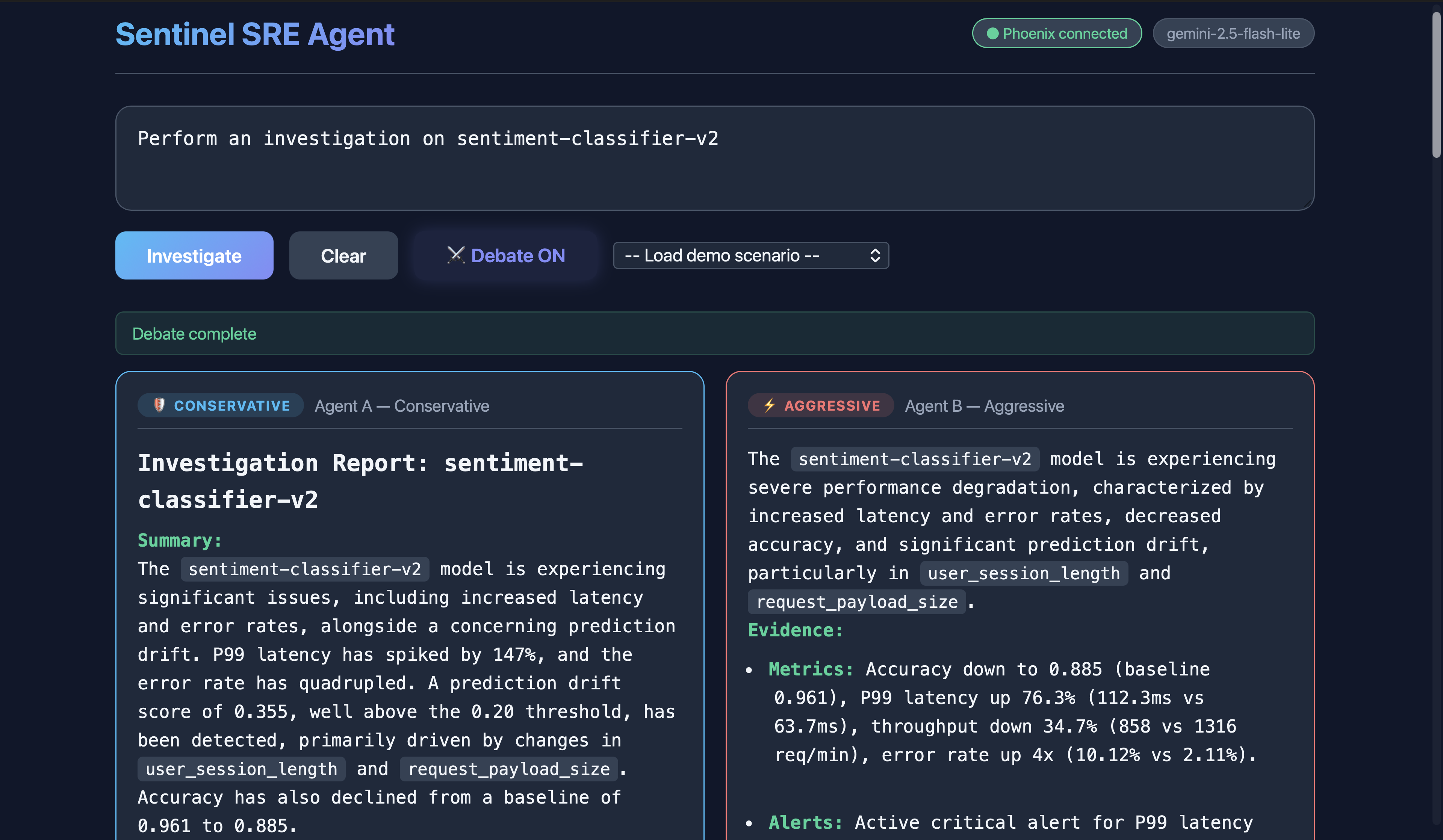
Investigation on sentiment-classifier-v2 model (Debate) (2)
-

Investigation on sentiment-classifier-v2 model (Debate) (3)
-
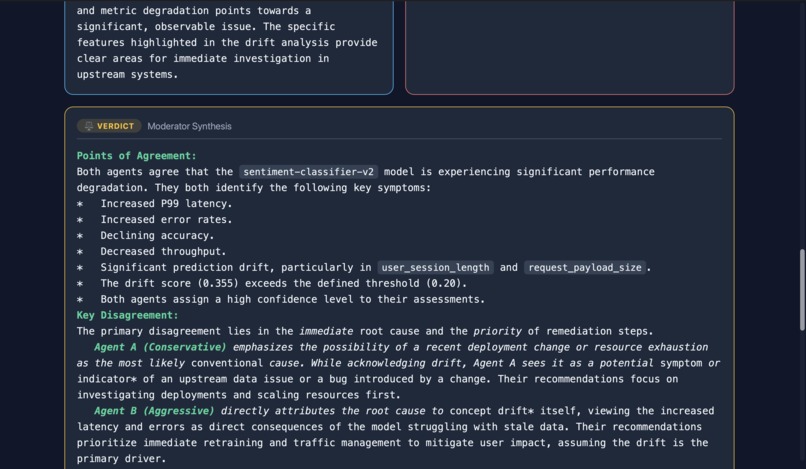
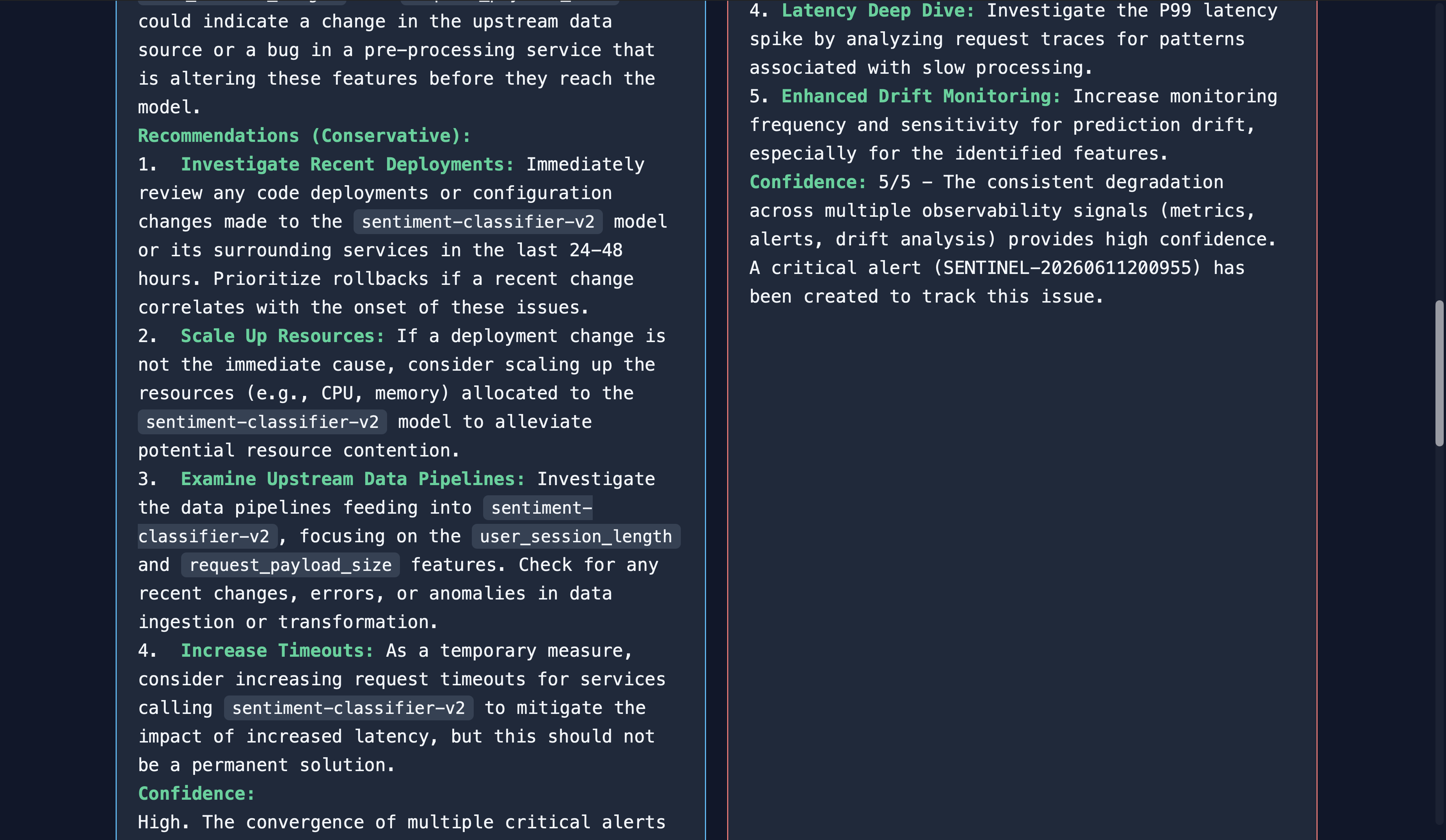
Investigation on sentiment-classifier-v2 model (Debate) (4)
-
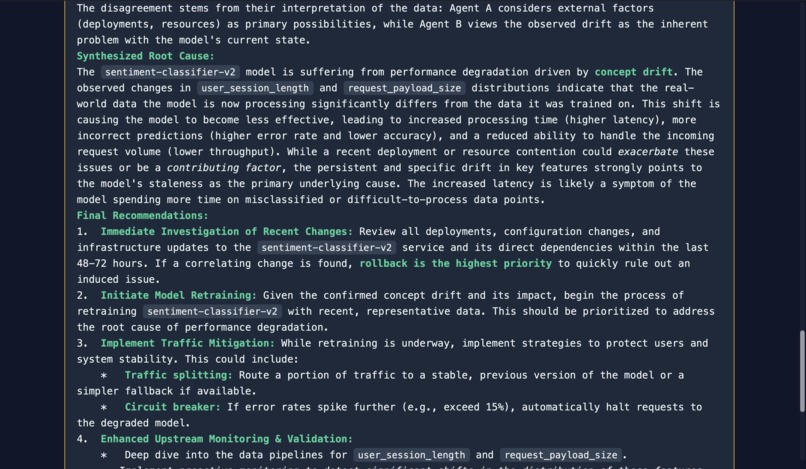
Investigation on sentiment-classifier-v2 model (Debate) (5)
-
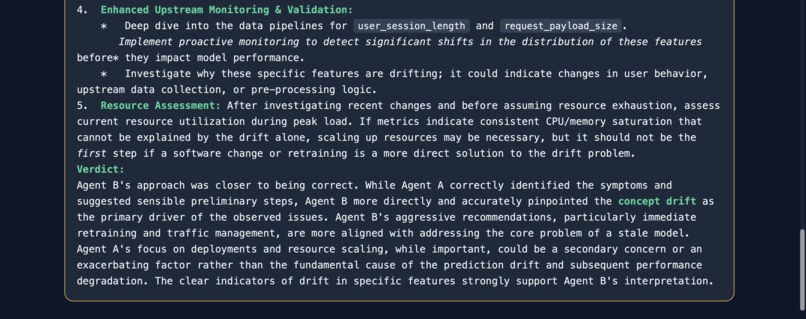
Investigation on sentiment-classifier-v2 model (Debate) (6)
Inspiration
ML models fail silently in production. When a sentiment classifier's P99 latency spikes at 2 AM, engineers spend hours manually cross-referencing metrics, traces, logs, and drift reports across half a dozen dashboards. Even worse, every incident is a one-off. Lessons learned are lost in Slack threads and post-mortem docs, never fed back into the tooling. We wanted an agent that does the full investigation, learns from every case, and gets smarter over time.
What it does
Sentinel is a self-improving SRE agent for ML observability. Give it a free-form incident like "URGENT: Error rate on fraud-detection-v1 just spiked to 15%" and it autonomously queries metrics, traces, drift, and alerts; correlates signals; identifies root cause; creates an alert; and suggests remediation, all in under 30 seconds. Every investigation is traced to Arize Phoenix Cloud, scored by an LLM judge, and those scores feed back into the agent's memory via MCP so the next investigation is better. An Agent Debate Mode lets users run two agents (conservative vs aggressive reasoning) in parallel with a Gemini moderator who synthesizes the best answer from both.
How we built it
Agent framework: Vertex AI ADK (google-adk 2.x) — Agent, Runner, FunctionTool wrapping all 11 custom tools. No third-party agent libraries; pure Google stack. Observability + Memory: Arize Phoenix Cloud via OpenInference OTLP tracing + the Phoenix MCP server (@arizeai/phoenix-mcp). Every LLM call, tool invocation, and evaluation is traced. The agent queries its own past traces through MCP to adapt its reasoning. Evaluation: An LLM-as-a-Judge (Gemini) scores each investigation on accuracy, completeness, and actionability (1–5 scale). Scores are stored as Phoenix span annotations and retrieved by the self-improvement loop. Debate Mode: Two SentinelAdkAgent instances run asynchronously with opposing system prompts (conservative / aggressive). Their outputs are fed to a Gemini moderator prompt that synthesizes points of agreement and delivers a verdict. Deployment: FastAPI server with SSE streaming → Docker → Cloud Run. CI/CD via GitHub Actions (build → push to Artifact Registry → deploy with Secret Manager for API keys).
Challenges we ran into
- Cloud Run health checks + MCP startup latency: The Phoenix MCP subprocess (npx) takes 5–15 seconds to start, exceeding Cloud Run's health-check timeout. Replaced with a direct HTTP GET to Phoenix's /v1/projects endpoint using httpx — sub-second, no subprocess, and already a project dependency.
- Python 3.11 f-string restrictions: Cloud Run's Python 3.11 runtime rejects multi-line f-string expressions and backslashes inside {} in f-strings. Had to extract several expressions into temp variables.
- GitHub Actions secret expansion: ${{ secrets.X }} inside run: shell scripts resolves to empty string. Moved all secrets to step-level env: blocks with tr -d to strip trailing newlines from secret values.
- ADK streaming vs synchronous API: The ADK's Runner.run() is synchronous, so debate mode runs both agents in a ThreadPoolExecutor via asyncio.gather to achieve true parallelism.
Accomplishments that we're proud of
- First (and only?) team to integrate Arize Phoenix MCP with Vertex AI ADK for a self-improvement loop at this hackathon.
- Agent Debate Mode — a genuinely novel architecture where two agents with opposing reasoning strategies argue an incident and a moderator picks the best synthesis. Built in a single session.
- Zero new dependencies for the entire project beyond google-adk and OpenInference, we wrote everything from scratch.
- The self-improvement loop actually works: feed it a scenario, it queries Phoenix MCP for past cases, finds similar incidents, and references their evaluation scores in its reasoning.
- Production-ready deployment: Cloud Run health check, Secret Manager, CI/CD, streaming SSE UI.
What we learned
- The google-adk framework is surprisingly flexible, FunctionTool wraps any Python callable with its signature, and Runner.run() gives fine-grained per-event control for streaming.
- Phoenix MCP over stdio is powerful but the subprocess startup cost makes it unsuitable for latency-sensitive paths (like health checks). Mixing MCP for introspection with HTTP API for fast checks gives the best of both.
- Building an effective system prompt is the hardest part of agent engineering. We iterated ~8 times to get the agent to stop asking permission and run autonomously.
- Python 3.11 f-string limitations are real and annoying. pyproject.toml should pin 3.11+ explicitly if you target Cloud Run.
What's next for Google Hack
- Embedding-based self-improvement: Replace token-overlap similarity with Phoenix's native embedding search for more relevant historical context.
- Human-in-the-loop gating: Add approval step before create_alert and suggest_remediation execute.
- Multi-model investigations: Extend analysis across model families (e.g., correlate a spike in classifier errors with a drift in the upstream embedding model).
- Slack / PagerDuty integration: Let Sentinel respond directly in incident channels.

Log in or sign up for Devpost to join the conversation.