Good Eye
Inspiration
Human vision is foveated — we only see sharply in a tiny 2° window and make 3–4 eye movements per second to build our understanding of the world. Recent work has started bringing this to robotics:
"Look, Focus, Act" (GIAVA, Chuang et al., 2025) introduced foveated Vision Transformers for robot manipulation, achieving 94% token reduction and 7× training speedup by mimicking human gaze patterns. But their approach requires expensive human eye-tracking data to train the gaze policy.
"Active Vision RL under Limited Visual Observability" (SUGARL, Shang & Ryoo, NeurIPS 2023) proposed learning separate motor and sensory policies through reinforcement learning, training agents to actively control what they observe. But this requires millions of environment steps and produces a black-box gaze policy you can't interpret.
We asked: what if you don't need training data OR reinforcement learning? What if a foundation model can reason about where to look, what's uncertain, and what to do, all zero-shot, all interpretable, all in natural language?
What It Does
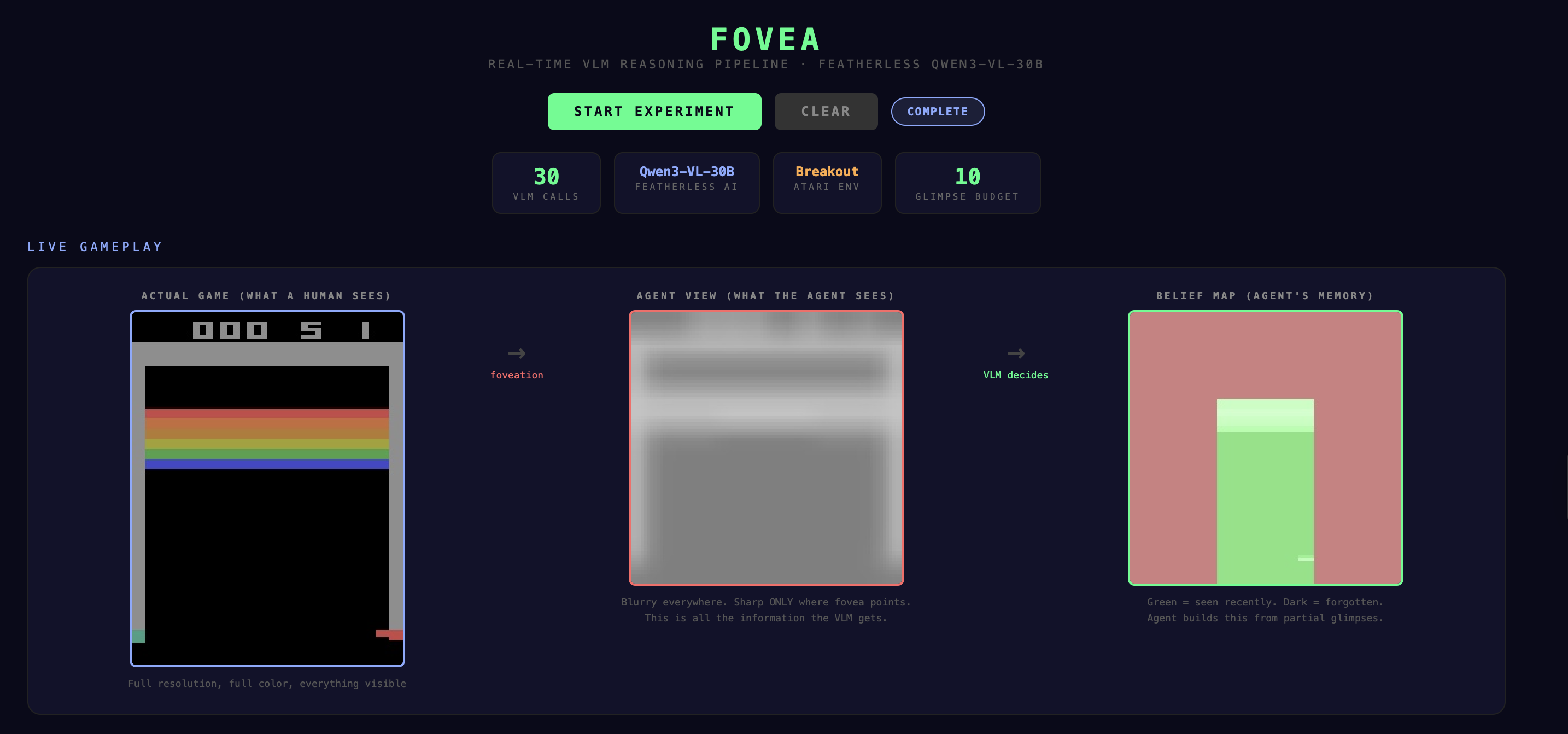
Good Eye is a foveated Vision-Language-Action agent that plays Atari Breakout while only seeing a blurry, degraded version of the screen. It gets a strict budget of 10 sharp "glimpses" per episode, small 30×30 pixel windows of clarity in an 84×84 blurry world.
On each glimpse, the agent:
- Receives the blurry peripheral view (everything downsampled to 20×20 then scaled back up)
- Consults its spatial world model (what it's seen before, how stale that information is, uncertainty per region)
- Sends the blurry image + memory state to Featherless AI's Qwen3-VL-30B vision-language model
- The VLM reasons in natural language: "The ball is likely moving downward, bot_center was seen 9 steps ago with uncertainty 0.33, I should re-check there"
- Outputs two decisions: WHERE to look (sensory action) and HOW to move the paddle (motor action)
- The fovea moves to the chosen region, capturing a sharp crop — new knowledge enters the world model
- Between glimpses, the agent acts blind, repeating its last motor decision while confidence decays
A real-time web dashboard lets you watch the entire process: the clear game (what a human sees), the degraded agent view (what the VLM gets), the belief map evolving over time, and the VLM's actual reasoning text for each decision.
How We Built It
Environment layer: We forked active-gym (the NeurIPS 2023 SUGARL environment library) and patched it for compatibility with modern ale-py and gymnasium. We built a GlimpseBudgetWrapper on top that enforces a strict N-glimpse limit per episode — between glimpses, the agent only sees the blurry peripheral view.
World model: A WorldModelMemory module maintains a spatial belief map of the 84×84 screen. It tracks per-region confidence that decays 5% per step, records when each region was last observed, and computes uncertainty scores. This gives the VLM temporal context — it knows that "bot_center was seen 9 steps ago and may be outdated."
VLM gaze + action policy: On each glimpse step, we send the blurry peripheral image + the full memory state to Featherless AI's Qwen3-VL-30B-A3B-Instruct. The VLM receives a structured prompt describing the 3×3 region grid, uncertainty per region, game-specific hints (ball bounces, paddle at bottom), and remaining glimpse budget. It returns both a gaze decision (which region to look at) and a motor action (move paddle left/right/stay).
Baseline strategies: We implemented 4 baselines for comparison — random gaze, center-fixed gaze, recency-based gaze (look where you haven't looked longest), and saliency-based gaze (look where there's the most visual motion).
Real-time visualization: A Flask web dashboard streams the VLM's reasoning process live. It shows three synchronized panels (clear game / blurry agent view / belief map) updating every 1.2 seconds, plus detailed reasoning cards for each VLM call showing the input image, uncertainty grid, reasoning text, decision, and resulting sharp foveal crop.
Tech stack: Python, active-gym (Atari foveated RL environments), Featherless AI Qwen3-VL-30B (vision-language reasoning), Flask + vanilla JS (real-time dashboard), PyTorch (CNN baselines), OpenCV (image processing), ale-py (Atari emulation).
Challenges We Ran Into
- active-gym compatibility: Built for older gymnasium/atari-py. We had to patch the codebase for modern ale-py — fixing attribute propagation across wrapper chains, int/float type mismatches, and ROM loading paths.
- Python 3.14 broke everything. ale-py, mujoco, and several dependencies don't have wheels for 3.14 yet. We had to create a parallel Python 3.12 venv.
- MuJoCo on macOS: Wouldn't install, blocking robosuite 3D environments. We pivoted from robot manipulation to Atari, which turned out to be a better testbed for the glimpse budget concept.
- VLM response parsing: Qwen3-VL doesn't always follow the exact output format. We built robust regex parsing with fallbacks to extract both region numbers and action keywords from free-form reasoning text.
- Disk I/O race conditions between the VLM writing reasoning data and the result capture writing foveal images. Solved by moving to an in-memory shared list with periodic disk flushes.
Accomplishments We're Proud Of
- The VLM genuinely reasons. It's not pattern matching — it tracks temporal uncertainty ("bot_center was seen 9 steps ago, may be outdated"), predicts ball trajectories ("the ball is moving downward, will soon be in the lower half"), and balances exploration vs. exploitation ("high uncertainty regions are unexplored, but the ball is more likely near the paddle").
- Zero-shot active perception works. No training, no demonstrations, no reward engineering. The VLM achieves functional gaze allocation and paddle control from just a text prompt and a blurry image.
- The visualization makes AI cognition observable. You can watch the agent think in real-time — see what it sees (blurry), read why it chose to look somewhere, see what it discovered (sharp crop), and watch its mental model evolve.
- Built on real research infrastructure. This isn't a demo wrapper — it's built on the actual NeurIPS 2023 active-gym codebase with novel additions (glimpse budget, world model, VLM gaze policy).
What We Learned
- Attention allocation IS intelligence. The difference between a random agent and an intelligent one isn't what they do — it's where they look. A random gaze policy wastes every glimpse. The VLM spends its budget where it matters.
- Foundation models have implicit gaze priors. Qwen3-VL already "knows" that in Breakout, the ball and paddle are at the bottom of the screen, and that tracking the ball is critical. This world knowledge is free — no training required.
- Foveated vision is a compute multiplier. Processing 20 tokens (foveated) instead of 324 tokens (full resolution) is not just faster — it forces the system to be intelligent about information gathering, which leads to more robust behavior.
- Interpretability comes free with VLM reasoning. Unlike RL policies where you need post-hoc saliency maps to understand decisions, the VLM literally tells you why it looked somewhere. This is invaluable for debugging and trust.
What's Next for Good Eye
- Train an RL motor policy with VLM gaze. Currently both gaze and motor come from the VLM. Next step: use the VLM for gaze only and train a fast RL motor policy that acts on the foveated observations — combining VLM reasoning with RL reaction speed.
- Robosuite robot manipulation. Port the glimpse budget + VLM gaze to 3D robot tasks (the active-gym robosuite integration is ready). A robot that reasons about where to look before grasping.
- Hardware deployment on Cyberwave SO101. The physical arm control code is already written. At the next robot station session, connect the VLM gaze to the real gripper camera — the arm physically points where Qwen3-VL says to look.
- Foveated ViT integration. Replace our blur+crop foveation with GIAVA-style foveated patch tokenization for true 94% token reduction in the vision encoder.
- Multi-agent active perception. Multiple agents with separate foveas cooperating to cover a scene, each agent looks where others haven't, coordinated by a VLM.
Built With
- featherlessai
- python

Log in or sign up for Devpost to join the conversation.