-
-
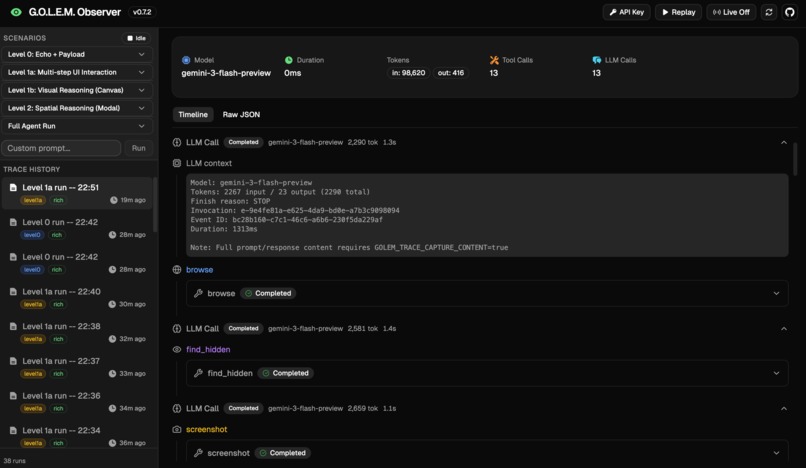
Observability platform
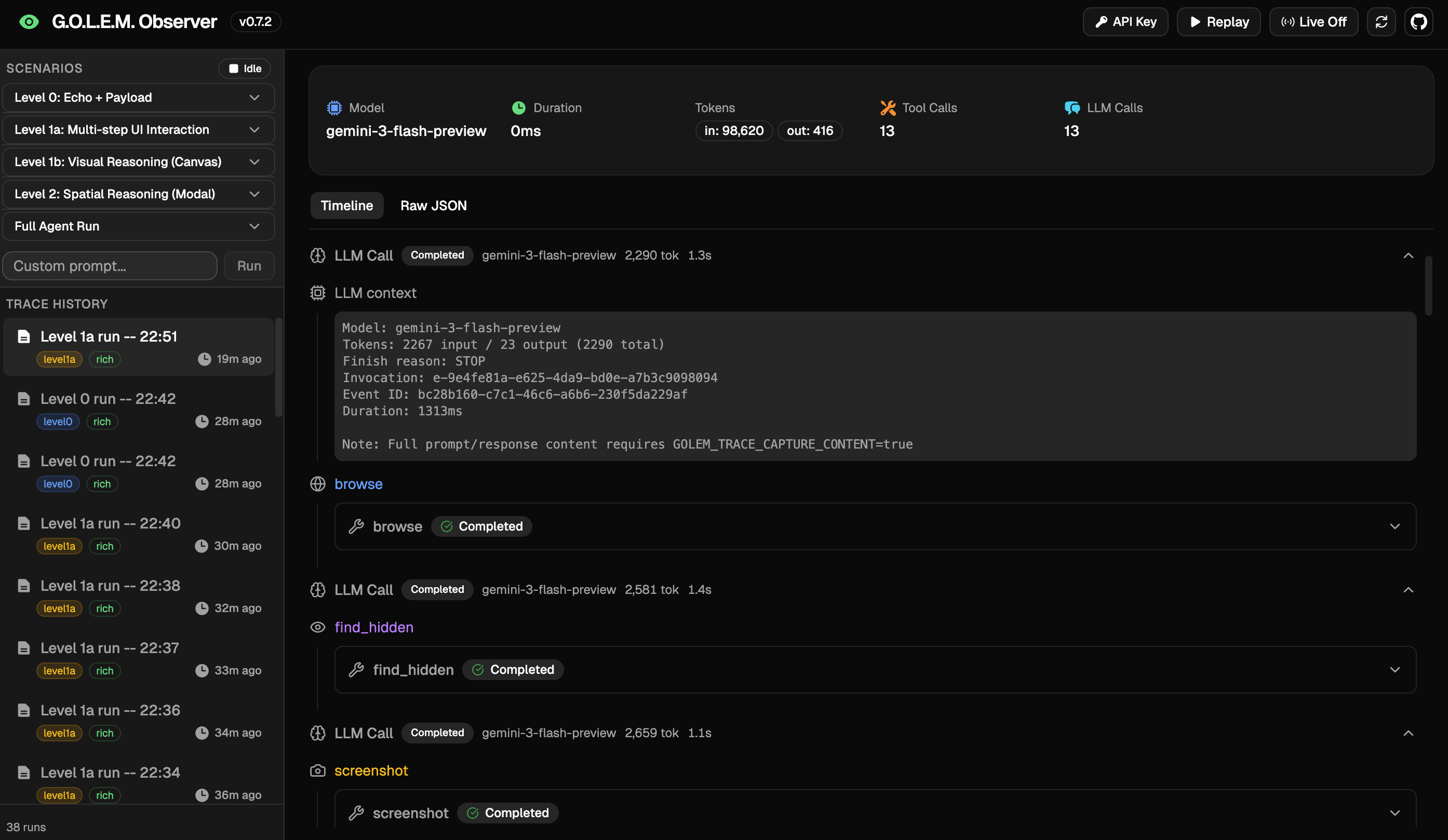
Inspiration
Most security scanners are very good at finding technical bugs like SQL injection or XSS. However, many real breaches come from business logic flaws, problems in how the application behaves rather than how it is coded.
These issues usually require human testers because they depend on understanding user flows, UI behavior, and multi step interactions.
This project started from a simple question:
Can an AI agent behave like a human security tester instead of just scanning like a tool?
G.O.L.E.M. explores whether a multimodal agent can navigate applications, form hypotheses, and test exploit paths on its own.
What it does
G.O.L.E.M. is an autonomous AI security engineer that discovers business logic vulnerabilities by navigating web applications like a human attacker.
Instead of scanning code, the system works through three stages:
- Perceive, Gemini analyzes screenshots and UI structure to understand workflows
- Reason, the agent forms hypotheses about logic flaws such as privilege bypass or price manipulation
- Execute, the agent interacts with the UI and verifies exploit results visually
This shifts security testing from pattern matching toward reasoning driven exploration.
How we built it
G.O.L.E.M. follows a layered agent architecture.
Gemini provides reasoning and multimodal understanding. Google ADK handles planning and tool execution. Supacrawl provides browser perception and UI interaction.
The agent operates in a continuous loop:
Observe, reason, act, verify.
The Observer dashboard streams the agent actions and reasoning in real time so the process is transparent and easy to inspect.
Key architectural components:
- Gemini for reasoning and multimodal understanding
- ADK for planning and execution loops
- Supacrawl for browser automation and perception
Challenges we ran into
One challenge was getting the agent to reason instead of behaving like a scripted crawler. This required designing tools around hypothesis testing rather than navigation.
The biggest challenge was on the rate limits. Engineering solutions such as spinning up new projects to rotate the keys and the models are the limit but it will still always run into the quota.
Another challenge was visual grounding. Models sometimes assume UI state incorrectly. We solved this by requiring visual confirmation before concluding success.
Reliability was also difficult. Autonomous agents fail often without constraints, so we added timeouts, retries, and structured traces.
Main engineering challenges:
- Preventing scripted behavior instead of real reasoning
- Verifying UI state visually to reduce hallucination
- Making tool execution reliable
What we learned
Building G.O.L.E.M. highlighted several lessons about real agent systems.
Agents need structured environments more than better prompts. Multimodal perception greatly improves autonomy. Transparency improves trust in agent decisions.
Key takeaways:
- Tool design matters more than prompt design
- Visual context improves reasoning quality
- Execution reliability is harder than intelligence
What is next
Future work would focus on turning this into a continuous security agent instead of a one time tester.
Possible next directions:
- Continuous monitoring agents
- CI security integration
- Multi agent testing workflows
The long term vision is AI security engineers that continuously test applications the way real attackers do.
Built With
- adk
- go
- playwright
- redis
- typescript

Log in or sign up for Devpost to join the conversation.