-
-

Try the huggingface- hosted version now!
-
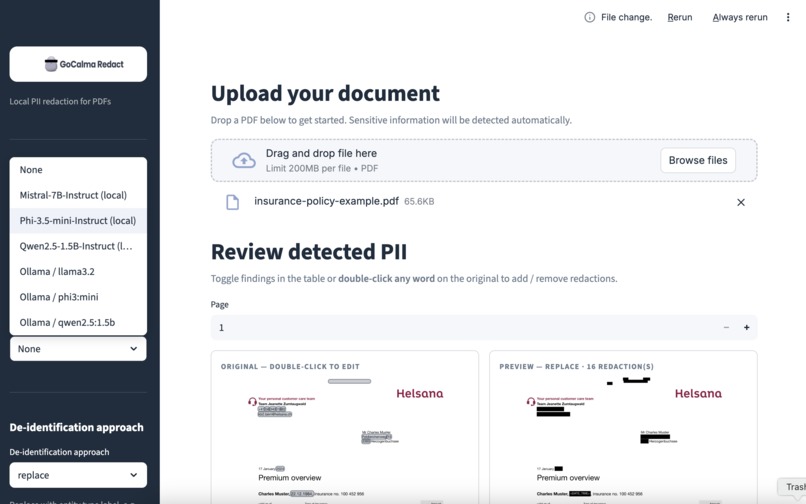
The web app interface of GoCalma Redact
-

hit the code team

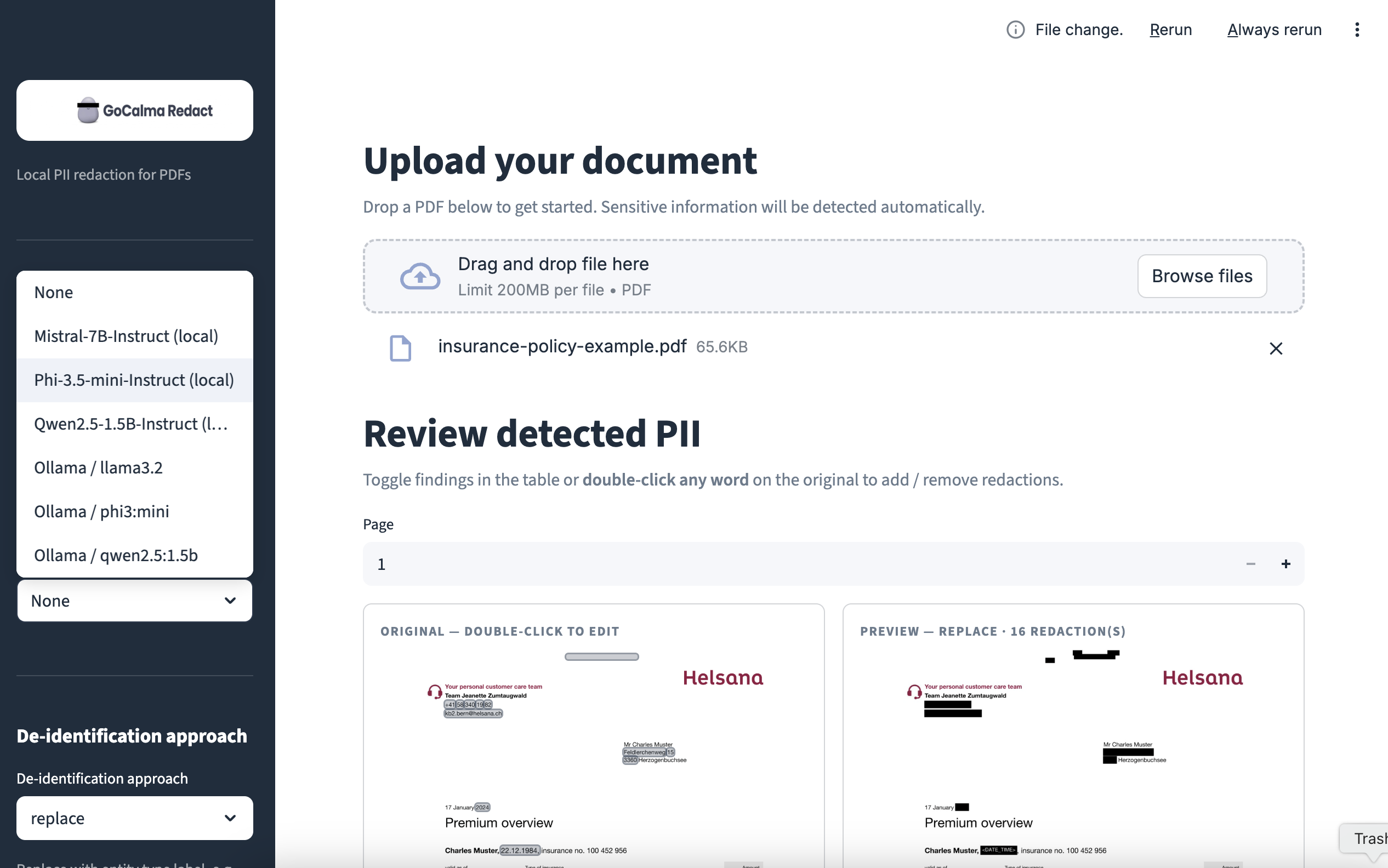

Inspiration
Do you happily share sensitive documents - contracts, tax forms, insurance papers - with OpenAi and Anthropic and Google?
Reclaim control over your data with GoCalma Redact: easily hide sensitive data before your documents are sent to AI servers.
What it does
GoCalma Redact allows you to:
- Upload PDFs, scans, and photos.
- Automatically detect personal data (PII) using GenAI.
- Review and adjust redactions interactively.
- Generate a fully redacted version.
All processing happens locally, no data ever leaves your machine.
Deployment Options
- desktop app for fully fledged version, 100% local.
- demo hosted on huggingface: https://huggingface.co/spaces/al-allaqi/gocalma-redact
- POC for iOS app, 100% local
Key Features:
- 100% local processing (zero external APIs)
- Interactive PDF editor (click-to-fix redactions)
- Dual detection pipeline (NER + LLM verification)
- Swiss & EU-specific PII detection (AHV, IBAN, CH IDs, etc.)
- Multilingual OCR (90+ languages)
- 7 redaction methods (mask, hash, encrypt, etc.)
Bonus Features:
- GoCalma Redact handles scanned documents reliably
- POC for iOS app: the approach works with Apple Intelligence shipped on latest iPhones.
- Reversible redactions with an encrypted key file
Technical Details
GitHub Repos:
Main product: https://github.com/alallaqi/go-calma-redact
Desktop App: https://github.com/alallaqi/gocalma-redact-desktop-app
POC for iOS App: https://github.com/Ben-Zahler/go-calma-redact-ios
How we built it
- Modular pipeline: OCR → NER → optional LLM → review → redaction
- Realistic dataset: Swiss documents (real, synthetic, dummy)
- Coverage: tax, insurance, contracts, invoices, letters
- Formats: scans, photos, PDFs
- Languages: EN, DE, FR, IT
Security:
- PBKDF2-HMAC-SHA256 encrypted key files (480k iterations)
- Salted HMAC hashing (immune to rainbow table attacks)
- Scanned PDF pixel flattening (forensic recovery prevention)
- LLM prompt injection guards
- 130 automated tests, including security regression tests
- Zero external network calls — verified, no CDN/fonts/analytics
Challenges we ran into
- Reliable detection on low-quality scans
- Balancing recall vs false positives
- Supporting multilingual + Swiss-specific formats
- Performance of local models
Accomplishments that we're proud of
- Strong performance on real Swiss documents for 11 Swiss-specific entity types
- Seamless integration of OCR, LLMs, and 9 NER backends
- Interactive redaction that works even on scanned PDFs, with 7 redaction approaches
- Two redaction modes: flattened PDFs (permanent) and reversible redactions
- Reliability demonstrated through 130 tests
What we learned
- Real-world documents are messy — synthetic data is not enough
- Combining models (NER + LLM) significantly improves recall
- UX matters: users must trust and verify the system
- Performance constraints shape design decisions
What's next for GoCalma Redact
- Faster, lighter LLM verification (<3s per page)
- Batch processing for multiple documents
- Smarter filtering to reduce false positives
- Broader European document support
Built With
- bert-base
- huggingface
- mistral
- ocr
- ollama
- phi
- presidio
- python
- qwen
- spacy
- streamlit
- surya
- swissbert






Log in or sign up for Devpost to join the conversation.