-
-
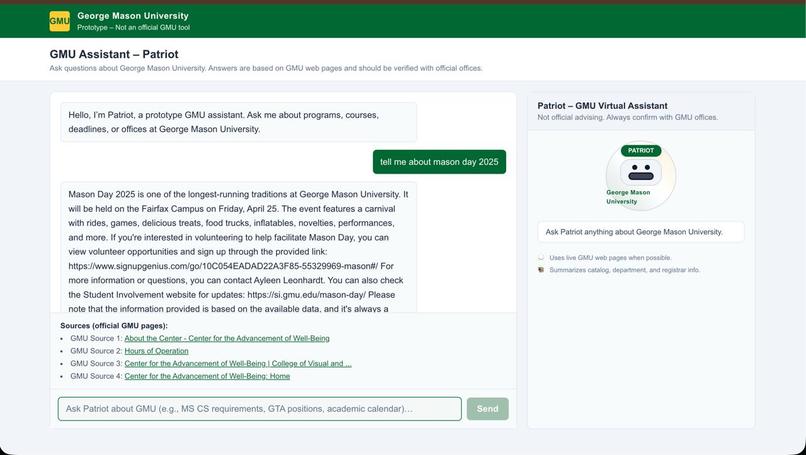
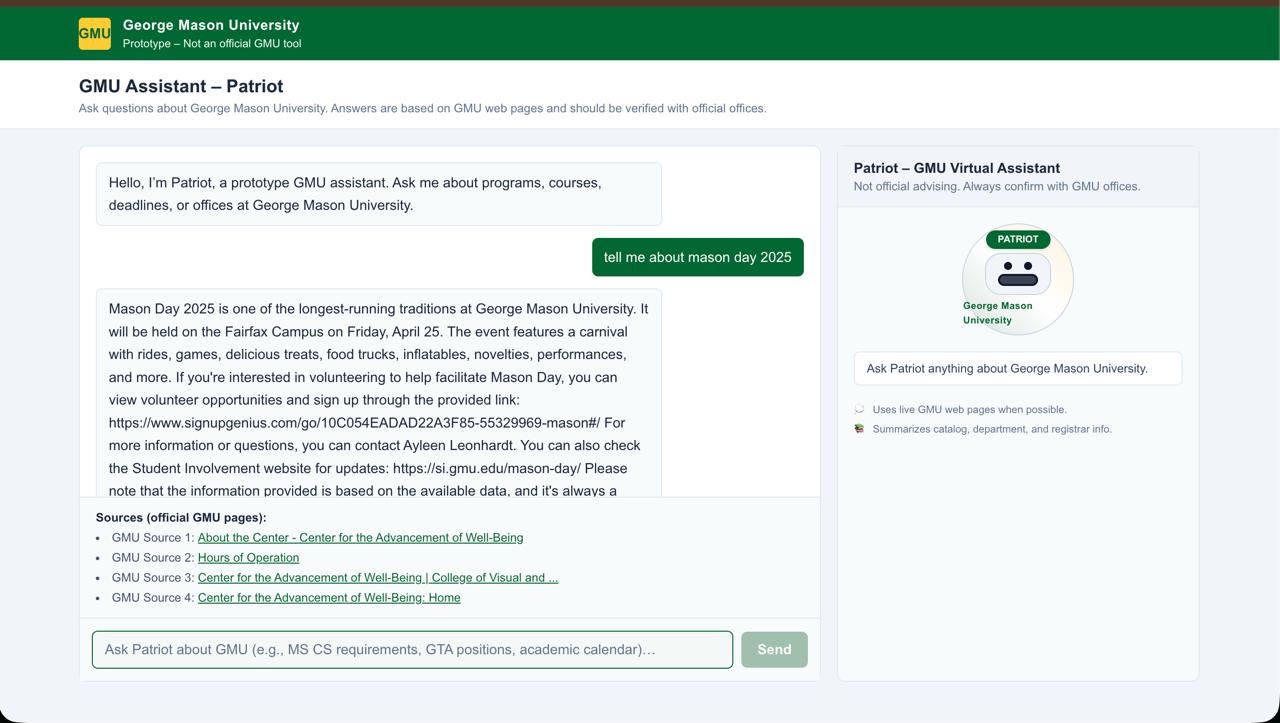
GMU SmartPatriot gives real-time, accurate answers about George Mason University using live website data.
Inspiration
As GMU students, we often navigate a complex web of information scattered across university catalogs, department pages, advising documents, PDF handbooks, forms, portals, and multiple official websites. Simple questions — like checking course prerequisites, confirming add/drop deadlines, understanding program requirements, verifying tuition details, or locating campus services — frequently turn into long searches involving multiple tabs, inconsistent layouts, outdated links, and pages hidden deep in the website structure.
While the information exists, it is fragmented, overwhelming, and not student-friendly, especially during stressful times like registration, advising, or admissions cycles. Many of us have spent hours jumping back and forth between pages, manually piecing together details that should have been easily accessible. We realized that this problem wasn’t just ours — almost every GMU student experiences the same frustration.
We wanted to rethink how academic information should be accessed. Instead of expecting students to search endlessly, we imagined a system where they could simply ask a question — in plain English — and get an instant, accurate answer grounded in real GMU resources. No hunting through PDFs. No navigating confusing menus. No guessing which page has the correct information.
This vision led us to create GMU SmartPatriot, a unified AI-powered knowledge engine built specifically for the George Mason University community. Our goal was to transform scattered university information into a single, intelligent interface that acts as a 24/7 academic companion. SmartPatriot centralizes course data, program requirements, deadlines, campus services, and university policies, giving students clear, trusted, and immediate answers within seconds.
By combining advanced AI capabilities with structured, verified GMU data, SmartPatriot aims to simplify student life, reduce stress, and make important information accessible to everyone — whether they are freshmen exploring their major or seniors preparing to graduate. It is our step toward building a more connected, supportive, and student-centered digital experience at GMU.
What it does
GMU SmartPatriot is an AI-powered knowledge engine designed to give George Mason University students instant, accurate, and reliable answers to nearly every university-related question. Instead of browsing multiple websites or digging through long PDFs, students can simply type a question and receive a clear, concise response within seconds.
SmartPatriot acts as a 24/7 academic and campus assistant, helping students with:
Academic Guidance
Explains course prerequisites, credits, and catalog descriptions
Breaks down major/minor requirements
Helps students understand program tracks and concentrations
Provides information on electives, core classes, and graduation pathways
Deadlines & Important Dates
Registration timelines
Add/drop & withdrawal deadlines
Graduation application dates
Academic calendar highlights
Campus Services & Resources
Advising offices and their roles
Financial aid & scholarship information
Housing, dining, transportation, and student support services
Contact details for key GMU departments
Admissions & Enrollment
Application requirements
Transfer credits and policies
Tuition overview and fee explanations
International student procedures
General University Information
Policies, rules, and student guidelines
Campus locations and building information
Helpful tips for navigating university systems
SmartPatriot is designed to understand natural-language questions just like a real conversation. Whether a student asks:
“When does Spring registration open?”
“What are the prerequisites for CS 310?”
“What resources does the Career Center offer?”
“How many credits do I need to graduate?”
…the assistant responds instantly with verified, structured information derived from official GMU sources.
In short, GMU SmartPatriot transforms the way students interact with university information by making it simple, fast, and accessible, eliminating the need to open countless tabs or search through complex pages.
How we built it
Building GMU SmartPatriot required combining multiple technologies, data sources, and engineering practices to create a smooth, intelligent, and reliable experience for students. We approached the project in four major phases: data collection, AI integration, search + grounding, and frontend development 1)Collecting & Organizing GMU Data
We gathered information from official GMU catalogs, department pages, PDFs, and university websites. Since each source had a different format, we cleaned and organized the data into a structured form that the AI could reference accurately. 2)AI Integration & Natural Language Understanding
We connected a conversational AI model and designed prompts so it can understand student questions in plain English. This helps the assistant interpret queries like course requirements, deadlines, or campus services and map them to the correct GMU information. 3)Search & Response Pipeline
We built a retrieval system using a mix of keyword search and semantic matching so the AI responds with real, verified GMU data instead of generic answers. This ensures accuracy and reduces hallucination 4)Frontend Interface (Next.js + React)
We developed a simple chat-style interface where students can type questions and instantly see responses. The design is responsive, clean, and easy to use on both desktop and mobile. 5)Backend Logic & Integration
Our backend manages:
API communication with the AI model
Search pipelines
Data routing
Safety and accuracy checks
This ensures that every question retrieves trusted GMU information, not random outputs. 6)hosting and github We hosted GMU SmartPatriot on Vercel, which provides fast global deployment, serverless API routes, and simple environment variable management. This allowed our frontend and backend logic to run smoothly with minimal configuration. For collaboration, version control, and issue tracking, we used GitHub, where all our code, updates, and project workflows were managed throughout the development process.
Challenges we ran into
One of the first challenges we faced was getting reliable live data from GMU websites. Since each department uses different layouts, our scraper often broke or returned incomplete information. We had to build custom fallback parsing and data-cleaning logic to ensure the assistant always received accurate snippets.
Another major issue was LLM hallucination. Early on, the model frequently invented professor names, emails, and academic policies. Because accuracy is critical, we implemented strict safety rules so the AI only answers using verified GMU snippets. When information is missing, it now clearly says so instead of guessing.
Adding conversation memory introduced new complications. The model needed to remember the last few messages, but we had to prevent memory from conflicting with new search results or causing outdated answers. We solved this by creating a short-term memory window that stores only the most recent interactions.
We also dealt with model deprecations and API failures from Groq. Several models were removed during development, causing unexpected 404 and deprecation errors. After experimenting, we migrated to a stable and fast model that consistently supports our workflow.
Deployment to Vercel brought its own challenges. Missing environment variables, failed builds, and scraper restrictions made the deployment process tricky. We fixed this by switching to proper serverless functions, adding all required environment variables, and adjusting runtime settings.
Lastly, we encountered a surprisingly big issue with Git, where nested copies of the project created embedded repositories. This caused Git to reject commits. After cleaning the folder structure and resetting the index, the repository finally stabilized.
Accomplishments that we're proud of
We’re proud that we were able to build a fully functional AI assistant that can pull real-time information directly from GMU websites, ensuring that students get accurate, up-to-date answers. The biggest accomplishment is that the system not only scrapes data live but also understands and summarizes it safely, avoiding hallucinations while providing clear guidance. We’re also proud that we successfully added conversation memory, allowing the assistant to remember recent questions and respond more naturally like a real advisor. Integrating Groq’s ultra-fast LLM with our custom scraping pipeline was another major milestone, giving the project both speed and intelligence. Finally, we managed to deploy everything on Vercel, resolve all environment and versioning issues, and create a stable platform that feels polished, reliable, and genuinely helpful for anyone wanting to know more about George Mason University.
What we learned
Working on this project taught us far more than just coding—it gave us real insights into what it takes to build a reliable, scalable, and user-friendly AI system. One of the biggest lessons was understanding the complexity of interacting with live, real-world university data. Web scraping sounds simple, but we quickly realized the importance of designing clean selectors, handling unpredictable HTML structures, and ensuring that scraped information remains accurate and up to date.
We also learned how delicate LLM prompting can be. Even powerful models need the right instructions, especially when accuracy matters. Designing prompts that minimize hallucinations, enforce safety rules, and keep the AI grounded in verified GMU data was a major breakthrough for us. We understood how combining a fast LLM backend (Groq’s inference engine) with live scraped content creates a much more trustworthy conversational experience.
Building conversation memory taught us another important skill—structuring and managing historical context so the system can maintain continuity while still staying safe and concise. This pushed us to think like system designers, not just programmers.
On the engineering side, we gained deep experience with Next.js, API routing, server-side logic, and the challenges of connecting frontend and backend cleanly. Configuring environment variables securely, handling model deprecations, fixing source-map errors, and dealing with Next.js build behaviors gave us real exposure to what production debugging feels like.
Deployment with Vercel was another major learning area. We learned how to handle environment variable propagation, deal with failing builds, optimize cold start times, and ensure the system behaves the same locally and in the cloud.
Finally, the most valuable lesson was how to collaborate, iterate quickly, and debug under pressure. Turning a raw idea into a fully working system—complete with scraping, memory, live search, and a polished interactive UI—taught us teamwork, communication, and resilience. It showed us how a real AI product is built: step by step, failure by failure, and improvement by improvement.
What's next for GMU SmartPatriot – The GMU Knowledge Engine
Our current system already delivers fast, accurate, and personalized answers using live GMU web data, but we are excited about the next phase. Moving forward, we want to transform GMU SmartPatriot into a full knowledge engine that supports not just students but anyone exploring George Mason University.
One major next step is implementing full-scale automated crawling of all major GMU domains (Registrar, CS Department, Housing, Financial Aid, Events, Dining, etc.) and creating a continuously updated structured knowledge base. This will allow the system to give deeper, more reliable answers without relying only on individual page scraping.
We also plan to introduce advanced personalization, where the assistant adapts to a student’s major, year, interests, and schedule—almost like a digital academic advisor that remembers your journey at GMU.
Another big milestone is adding multimodal capabilities, enabling the assistant to process PDFs, course syllabi, images of schedules, and campus maps. This would open the door to features like “Upload your syllabus and get weekly study plans” or “Show me where this building is on campus.”
We’re also exploring real-time campus integration, such as Mason Shuttles data, campus events, deadlines, and alerts—essentially turning SmartPatriot into a live campus companion.
On the system side, we want to enhance our backend with vector search, RAG pipelines, and better conversation memory to ensure answers stay consistent and context-aware across long interactions.
Ultimately, our goal is to evolve GMU SmartPatriot into a full-fledged digital guide for the GMU community—faster, smarter, more capable, and always up to date with real-time campus knowledge.
Built With
- custom-web-scraper-(cheerio)
- git
- github
- google/bing-search-api
- groq-api-(llama-3.1)
- next.js-14
- node.js
- tailwind-css
- typescript
- vercel


Log in or sign up for Devpost to join the conversation.