Inspiration
Every tabletop RPG player knows the magic of a great Game Master — the voice that drops to a whisper before a reveal, the dramatic pause after a dice roll, the world that feels alive because someone is performing it for you. But finding a GM is hard. Scheduling is harder. And playing solo? That's just reading a book with extra steps.
I asked: what if the GM was always available, always in character, and always cinematic?
GM-Genie was born from the collision of two obsessions: tabletop RPGs and the Gemini Live API's native audio capabilities. The moment I heard Gemini could hold a real-time voice conversation, I knew — this wasn't a chatbot. This was a Game Master.
What it does
GM-Genie is a voice-first, multimodal RPG narrator that runs cinematic tabletop sessions entirely through conversation. You talk to your GM. It talks back. You see the world it describes. You hear the ambience shift around you.
- 7 handcrafted worlds — The Char, Neon Ghosts, The Sundered Skies, The Drowning Sea, The Verdant Maw, The Crimson Siege, The Starbound Frontier
- Real-time voice conversation via Gemini Live API — no text, no typing, just talking
- Dynamic scene generation — AI-generated images appear as the story unfolds
- Adaptive soundscapes — ambient audio and SFX shift with the narrative (tavern -> combat -> forest)
- Pre-rolled dice system — no tool calls, no latency spikes, just seamless storytelling
- Session continuity — your character, inventory, and world state persist between sessions
- Combat with battle ambience — "Roll for initiative" triggers battle music automatically
- Story Loom — two-layer story generation: campaign arcs shape the overarching narrative, session beats drive each encounter moment-to-moment
How I built it
The Zero-Tool Architecture
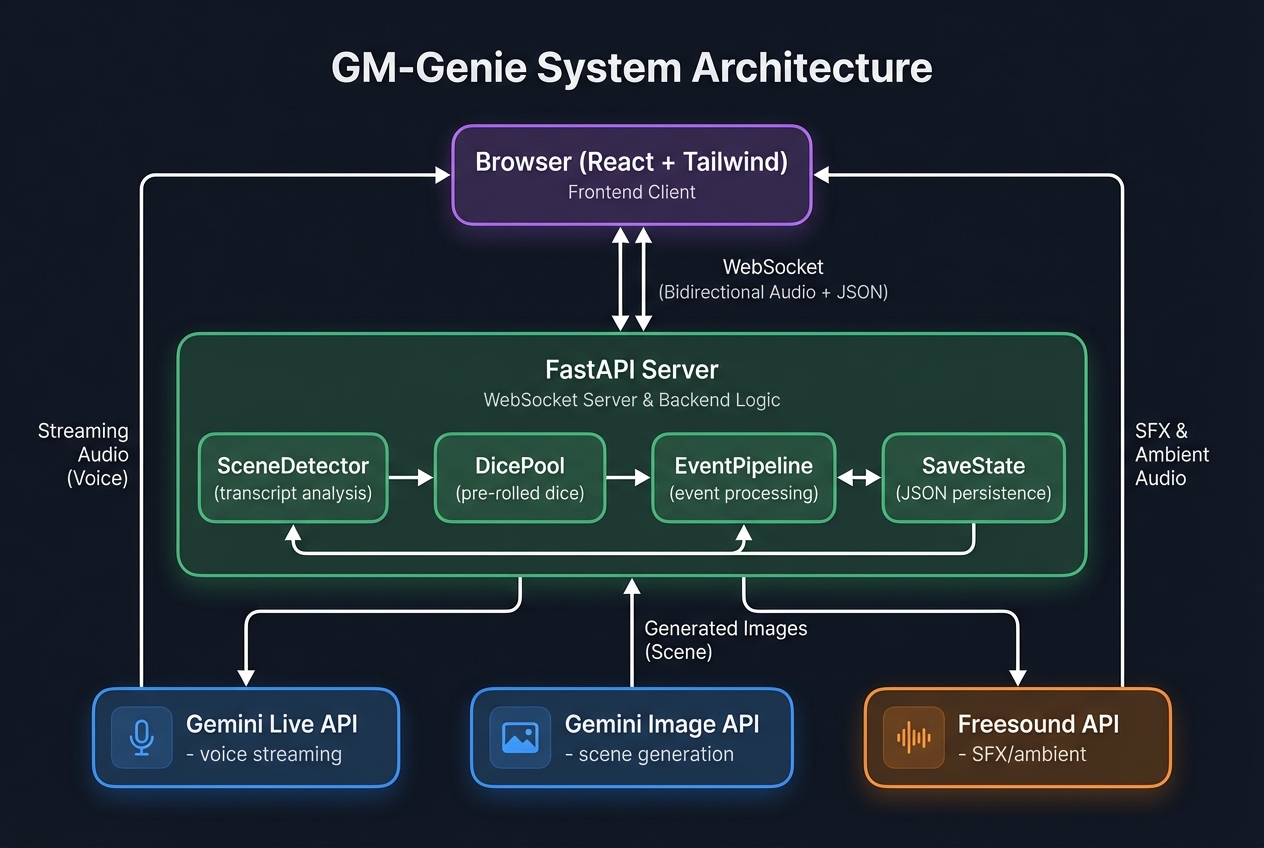
My biggest breakthrough was eliminating all tool calls from the voice session. Early prototypes used Gemini's function calling for dice rolls, scene generation, and sound effects — but native audio + tool calls caused ~70% connection crashes (WebSocket 1008/1011 errors).
The solution: zero tools in the voice pipeline. Everything is handled server-side:
Player speaks -> Gemini responds (audio only) -> Server transcribes GM speech
-> SceneDetector analyzes transcript -> Triggers scenes/SFX/ambient in parallel
- Dice: Pre-rolled server-side with real randomness and injected into the system prompt — the GM cannot hallucinate a dice result. The GM says "you roll to dodge..." and the frontend shows the animation — no API call needed.
- Scenes: A keyword detector watches GM transcripts for visual cues ("you see...", "before you stands...") and fires image generation in the background.
- Audio: Combat triggers ("roll for initiative") swap ambient to battle music. Scene changes trigger new soundscapes. All from transcript analysis.
Tech Stack
- Agent Framework: Google ADK (Agent Development Kit) for agent orchestration, session state management, and tool routing
- Voice:
gemini-2.5-flash-native-audio-latestvia Gemini Live API (WebSocket bidirectional audio streaming) - Text:
gemini-2.5-flashvia Google GenAI SDK with 9 tools for interleaved text + image + audio output - Images: Imagen 4 (
imagen-4.0-generate-001) for scene generation, with Gemini image fallback on quota limits - Audio: Freesound API (third-party, used under their API terms) for dynamic SFX and ambient sounds, with server-side disk caching
- Deployment: Google Cloud Run with Terraform IaC (
infra/main.tf), Secret Manager for API keys, Artifact Registry for container images - Backend: FastAPI with WebSocket support, async event pipeline
- Frontend: React + Vite + Tailwind, AudioWorklet processors for mic capture (16kHz) and playback (24kHz)
- State: Per-world JSON save files for character stats, inventory, world state, and session continuity
The DM Framework
I didn't just connect an LLM to a microphone. I engineered a Game Master personality using techniques from professional dungeon masters:
- E.A.S.E. (Environment -> Atmosphere -> Senses -> Events) for scene descriptions
- The Rule of Three — highlight 2-3 interactable things, end on the most dramatic
- Warm Opens — lore monologues that ground the player before asking "what does your character look like?"
- Voice Lock — consistent GM voice throughout, distinct NPC voices with verbal tics
- Paper Shuffle — performative hesitation ("let me check...") before reveals
- Awareness Gates — GM-initiated perception checks that scale information to the roll
Challenges I ran into
Audio is unforgiving. Unlike text, you can't hide latency behind a loading spinner. Every gap in the conversation, every repeated phrase, every awkward silence breaks immersion. I spent more time on timing than on features:
- A client-side noise gate broke Gemini's VAD completely — zero player detection. Solution: continuous audio stream, let Gemini handle its own voice activity detection.
- 84-byte AudioWorklet chunks were too granular for the API. Solution: batch to ~3200 bytes (~100ms) before sending.
- Filler sounds ("Hmm...", "Let me think...") originally used separate TTS API calls that burned through rate limits. Solution: inject filler prompts directly into the live session queue.
Resilience took iteration. Voice sessions auto-reconnect on WebSocket drops (up to 3 retries). Scene generation falls back from Imagen 4 to Gemini image generation when quota is hit. Image generation quota was a constant battle — I cycled through multiple models as rate limits hit during testing.
The 5-minute session window forced me to design for density. Every second counts — the GM has 15 seconds to set the world, ask the player to describe their character, and launch into adventure. Session endings are timed so the GM naturally wraps the story at the boundary.
Accomplishments that I'm proud of
- Zero-tool voice architecture — solved the ~70% crash rate by moving all game mechanics server-side, achieving stable multi-minute voice sessions with no disconnects
- Grounded dice rolls — pre-rolled server-side randomness means the GM never hallucinates a result. Every "you rolled a 17" is a real roll
- Seamless multimodal interleaving — scene images, ambient audio, SFX, and dice animations all trigger automatically from the GM's spoken narration, with no player action required
- DM personality engineering — the GM uses professional dungeon master techniques (E.A.S.E., Rule of Three, Voice Lock) that make sessions feel like playing with a skilled human GM, not talking to a bot
- 7 original worlds with distinct lore, factions, story tables, and ambient soundscapes — all built from scratch with no licensed IP
What I learned
- Zero-tool architectures beat reliable-tool architectures for real-time audio. The model's native voice is far more stable when it doesn't have to context-switch to function calls.
- Server-side intelligence > client-side complexity. Moving scene detection, dice, and audio triggers to the server simplified everything and eliminated round-trip latency.
- The GM's personality IS the product. Technical architecture matters, but the difference between "neat demo" and "I want to play again" is entirely in the prompt engineering — the voice direction, the pacing rules, the improv techniques.
What's next for GM-Genie
- Multi-session campaigns — persistent world state and story arcs across multiple play sessions (Story Loom foundation is live)
- NPC voice portraits — show who's speaking with character labels and distinct voices
- Mobile UI — responsive layout for phone play
Built With
- audioworklet
- fastapi
- freesound
- google-adk
- google-artifact-registry
- google-cloud-run
- google-gemini-live-api
- google-genai-sdk
- google-secret-manager
- imagen-4
- javascript
- python
- react
- tailwind-css
- terraform
- typescript
- vite
- web-audio-api
- websocket


Log in or sign up for Devpost to join the conversation.