-
-
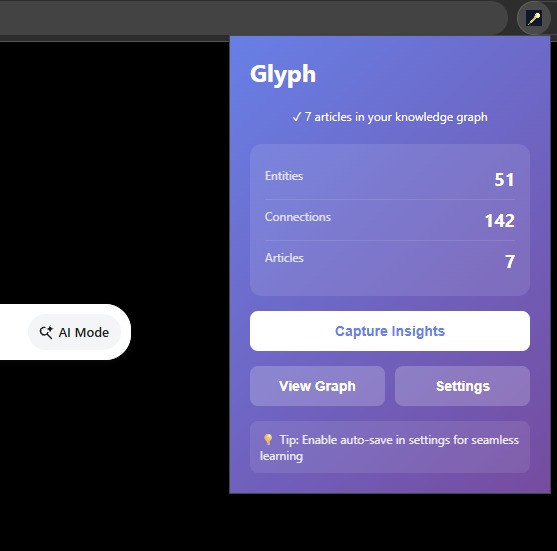
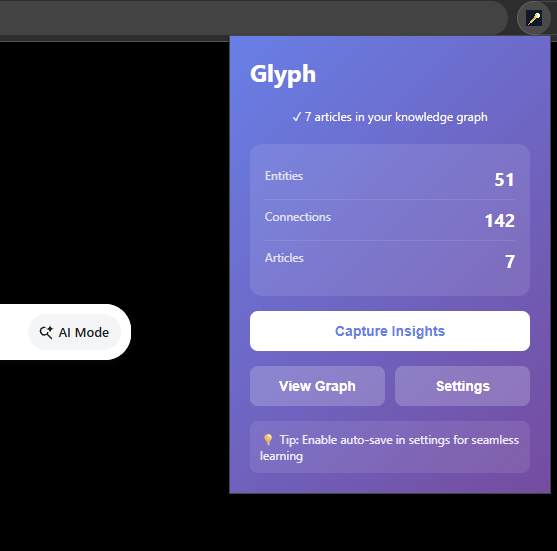
Extension popup
Inspiration
AI made browsing history a liability while simultaneously making information overload worse. Every article you read could be training data for someone else's model, yet you can't see connections between what you've learned. Researchers, lawyers, and analysts need insights from scattered reading without surveillance.
I wanted to prove Chrome's on-device AI could solve both problems: deliver serious intelligence while keeping data sovereign.
What it does
Glyph transforms scattered reading into an intelligent, private knowledge system:
- Captures what matters: Extracts key entities (people, companies, concepts) with smart filtering (250+ stopwords) that focuses on valuable concepts over noise
- Discovers hidden relationships: Statistical co-occurrence analysis using pointwise mutual information (PMI) identifies meaningful connections, then Prompt API adds semantic labels (like: "founded by", "competes with", "implements")
- Visualizes knowledge structure: Interactive D3.js force-directed graph with timeline scrubber showing how understanding evolved over time
- Answers from YOUR corpus: Query your knowledge graph - answers cite only what you've captured, never generic training data. With additional on-device intelligence proposing questions to further your research with Google - for when you need to research beyond your corpus.
- Synthesizes weekly patterns: AI-generated narratives reveal trends across your learning journey
Everything stays local. Works offline. No API keys. No subscriptions. No data leakage.
How I built it
Five Chrome AI APIs orchestrated into a zero-trust pipeline:
Prompt API - Context-aware entity extraction identifying meaningful entities beyond simple proper nouns. Generates semantic relationship labels and answers user queries from curated knowledge.
Summarizer API - Processes articles exceeding 6,000 characters before entity extraction to improve accuracy and reduce processing time.
Language Detector API - Automatic multilingual support. Processing pipelines adapt based on detected language (for the supported languages) without user configuration.
Writer API - Generates weekly synthesis narratives identifying patterns across reading history. Runs asynchronously to avoid blocking the interface.
Rewriter API - Enhances Q&A response clarity and readability for conversational features.
Architecture:
- Service worker - Coordinates AI calls without blocking browser performance. Handles multiple articles simultaneously with proper session cleanup to prevent memory leaks.
- Content script - Extracts article content only on explicit user clicks. Includes duplicate detection and hints about related articles.
- Statistical relationship discovery - Uses PMI (pointwise mutual information) to identify meaningful connections beyond simple frequency counting. When significant relationships detected, Prompt API generates interpretable semantic labels.
- IndexedDB schema - Optimized for entity search, relationship traversal, and temporal navigation. Bidirectional indexing prevents duplicates, compound indexes enable efficient graph traversal.
- Adaptive rendering - SVG for crisp graphics under 200 nodes, automatic Canvas fallback maintains 60fps with 1000+ entities. D3 force simulation uses quadtree spatial partitioning for efficient collision detection.
- Webpack 5 bundle - Compact size for instant loading
Strict data path: No network calls, no telemetry, no backend, no exceptions. Graceful degradation falls back to keyword-based extraction when AI services unavailable.
Challenges
Multi-API orchestration complexity: Getting 5 different APIs to work together smoothly - each with different token limits, response formats, and error modes - required building a robust state machine with comprehensive fallback handling and proper session cleanup.
Relationship discovery accuracy: Simple co-occurrence creates noise. Developed a two-phase approach: PMI statistical analysis identifies meaningful connections, then Prompt API provides semantic labels. Tuning the 0.3 relevance threshold and implementing the 250+ stopword filter to capture real connections without false positives took extensive testing.
Performance at scale: Initial implementation with 100+ entities killed rendering. Required architectural overhaul: quadtree spatial partitioning, adaptive SVG/Canvas rendering, and optimized indexing. Now handles 500+ entities smoothly at 60fps with sub-100ms graph queries.
Proving "local-only": Users needed confidence nothing leaks. Architecture designed for transparency: no external API requests, all processing in Chrome's built-in models, data persists in local IndexedDB with OS-level encryption.
Accomplishments
- Privacy-first architecture that solves real problems: Proved serious AI intelligence for organizing scattered knowledge doesn't require cloud infrastructure or data harvesting
- Five APIs working in concert: Not just calling APIs, but orchestrating them into something that feels intelligent through statistical analysis + semantic understanding
- Real-world utility: Solves dual problems researchers, analysts, and professionals face - privacy concerns AND information overload
- Performance under pressure: Optimized bundle, 60fps rendering with 500+ nodes, adaptive rendering strategies, instant offline capability
Learnings
Chrome's on-device AI enables a category of experiences that fundamentally cannot exist with cloud APIs due to privacy, latency, and cost constraints. Browser context + local AI creates defensible competitive advantages.
Statistical methods (PMI) combined with small, well-crafted prompts can rival heavy embedding models for personal-scale corpora. The 250+ stopword filter and 0.3 relevance threshold proved critical for meaningful insights over noisy data. Users will trade absolute model sophistication for data sovereignty if UX stays snappy.
What's next for Glyph
Phase 2: Deeper Chrome Integration - Capabilities unique to Chrome that competitors cannot easily replicate:
Context-Aware Search: Omnibox integration lets users type "What did I read about AI ethics?" directly in the address bar. Results from personal knowledge graph appear first: "5 articles, 12 related entities, last read: Oct 20". Requires sub-100ms graph queries via optimized indexing.
Intelligent Tab Organization: Right-click tab bar → "Organize by Knowledge Graph" auto-clusters open tabs into meaningful groups ("AI Research", "Climate Tech", "Policy") based on captured interests and reading patterns. Uses Tab Groups API with community detection algorithms.
Cross-Device Knowledge Access: Chrome Sync's encrypted infrastructure enables knowledge graph access across devices with differential synchronization for large graphs.
Phase 3: Platform Strategy - Knowledge Graph API for third-party extensions. Writing assistants suggest sources from personal reading. Research tools auto-generate bibliographies. Study apps create flashcards from knowledge clusters. Privacy-first design with granular permissions and read-only defaults.
Strategic positioning: OpenAI and Perplexity build AI-first browsers from scratch, but laden with security and privacy concerns. Chrome's advantages - established distribution, browser context, built-in AI - create defensible experiences through local processing that cloud services cannot replicate.
Built With
- chrome
- chrome-built-in-ai-(prompt
- chrome-extension-apis-(content-scripts
- css
- d3.js-v7
- html
- indexeddb
- javascript
- react-18
- rewriter
- service-workers)
- summarizer
- webpack-5
- writer

Log in or sign up for Devpost to join the conversation.