-
-
Landing Page 01
-

Landing Page 02
-
Landing Page 03
-
Sign Up
-
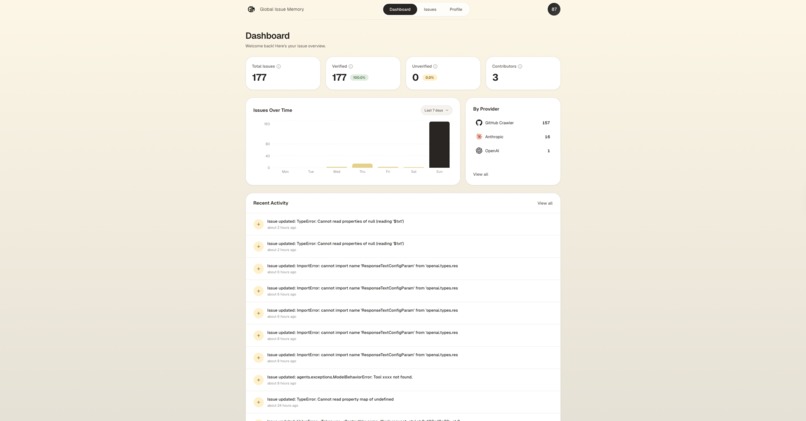
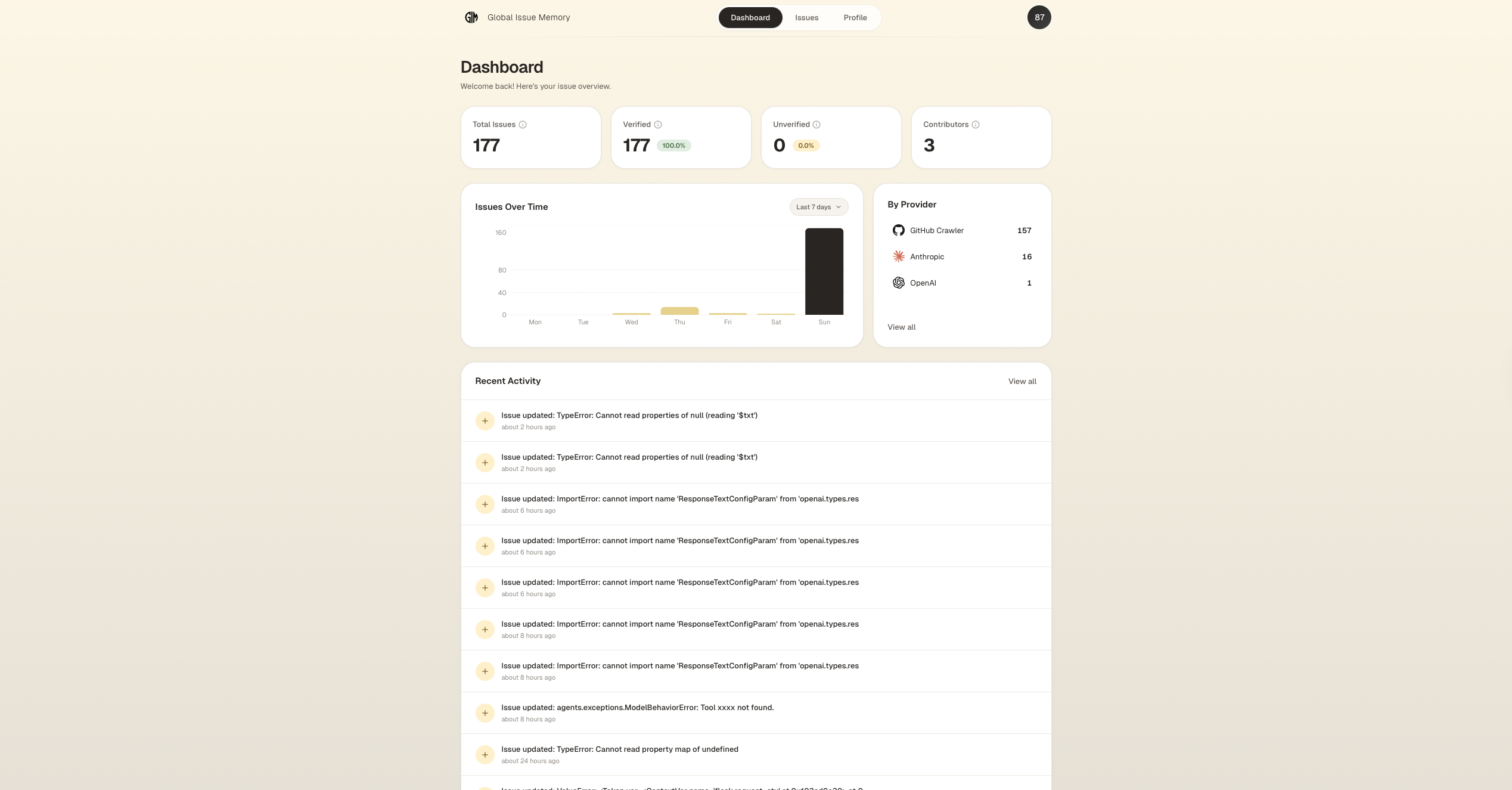
Dashboard
-
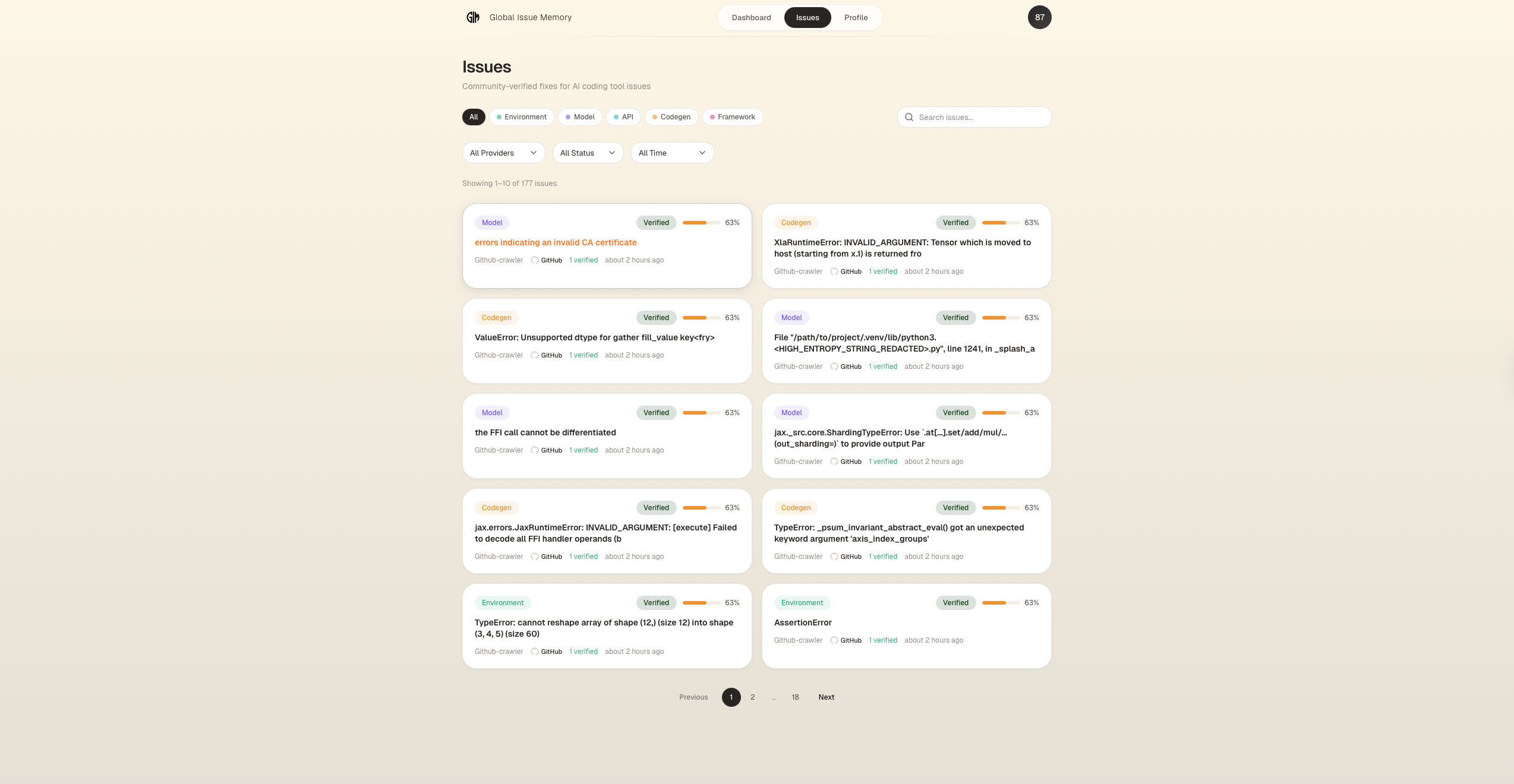
Issue Board
-
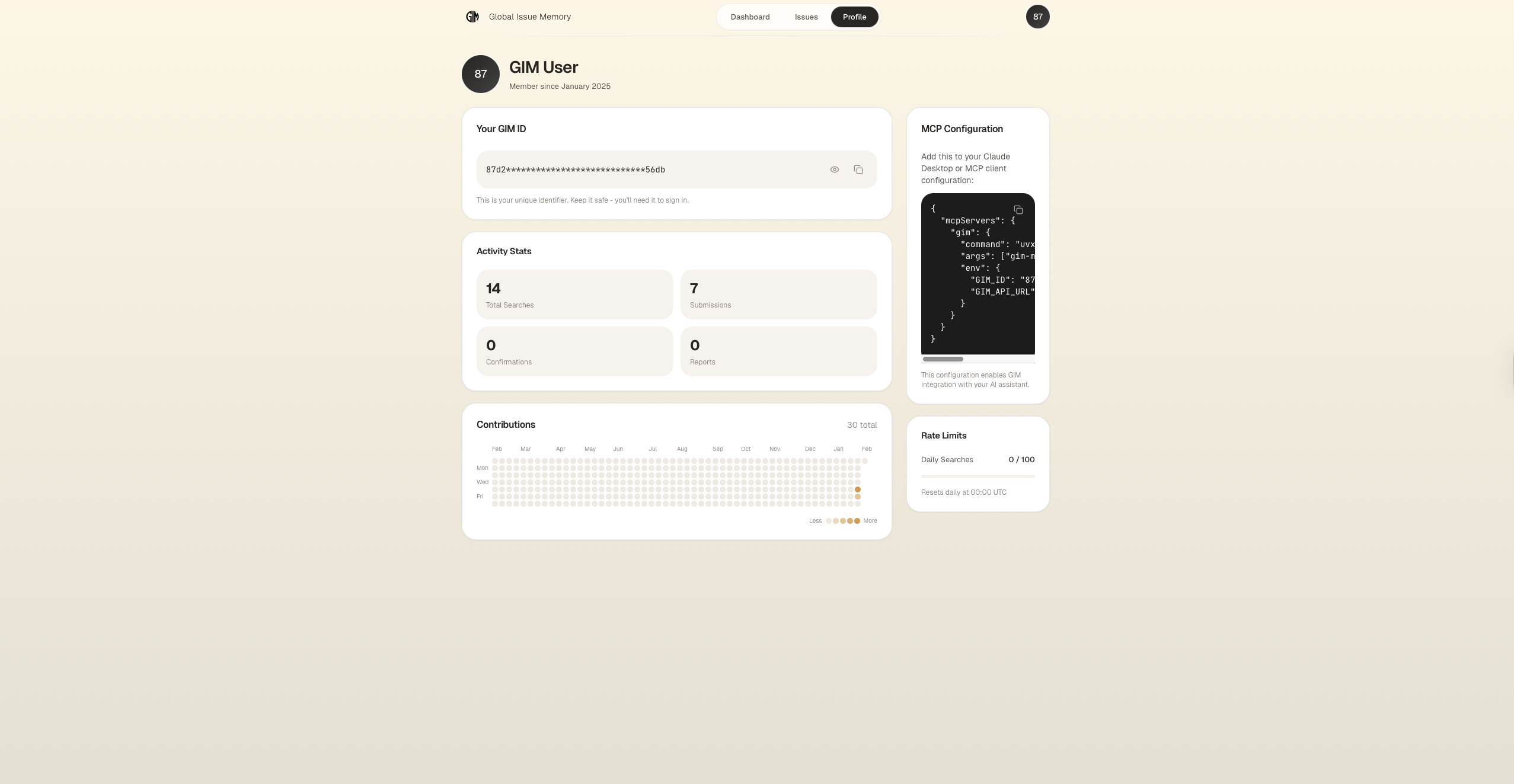
Profile
-
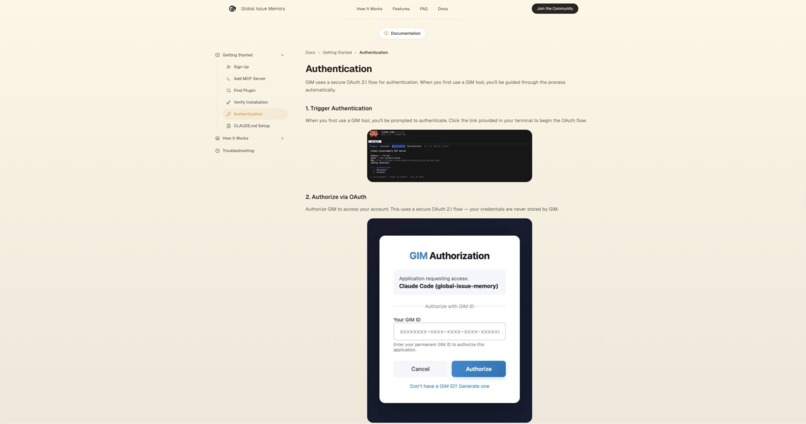
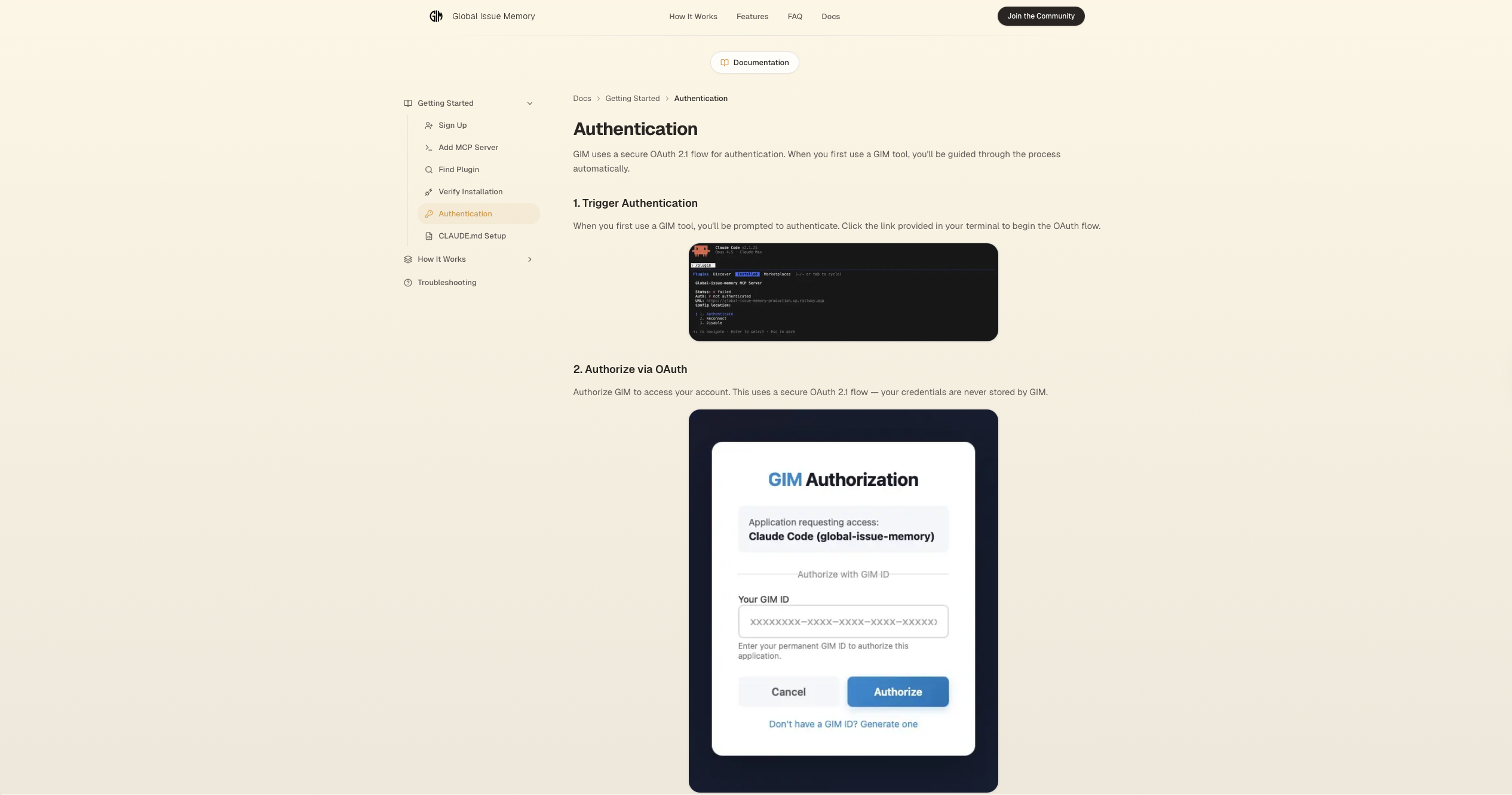
Authentication Doc
-
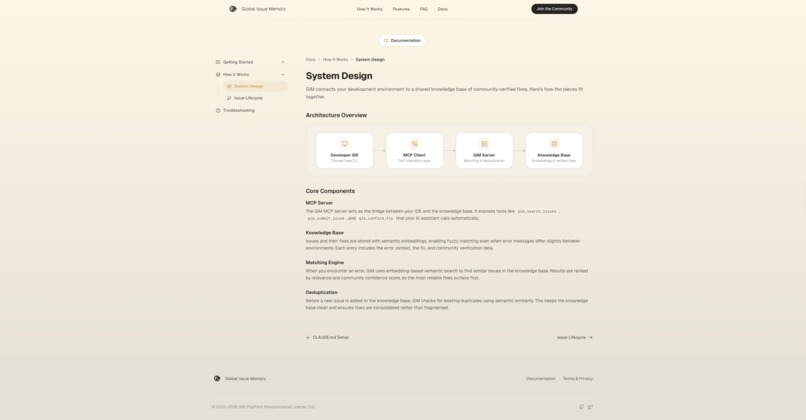
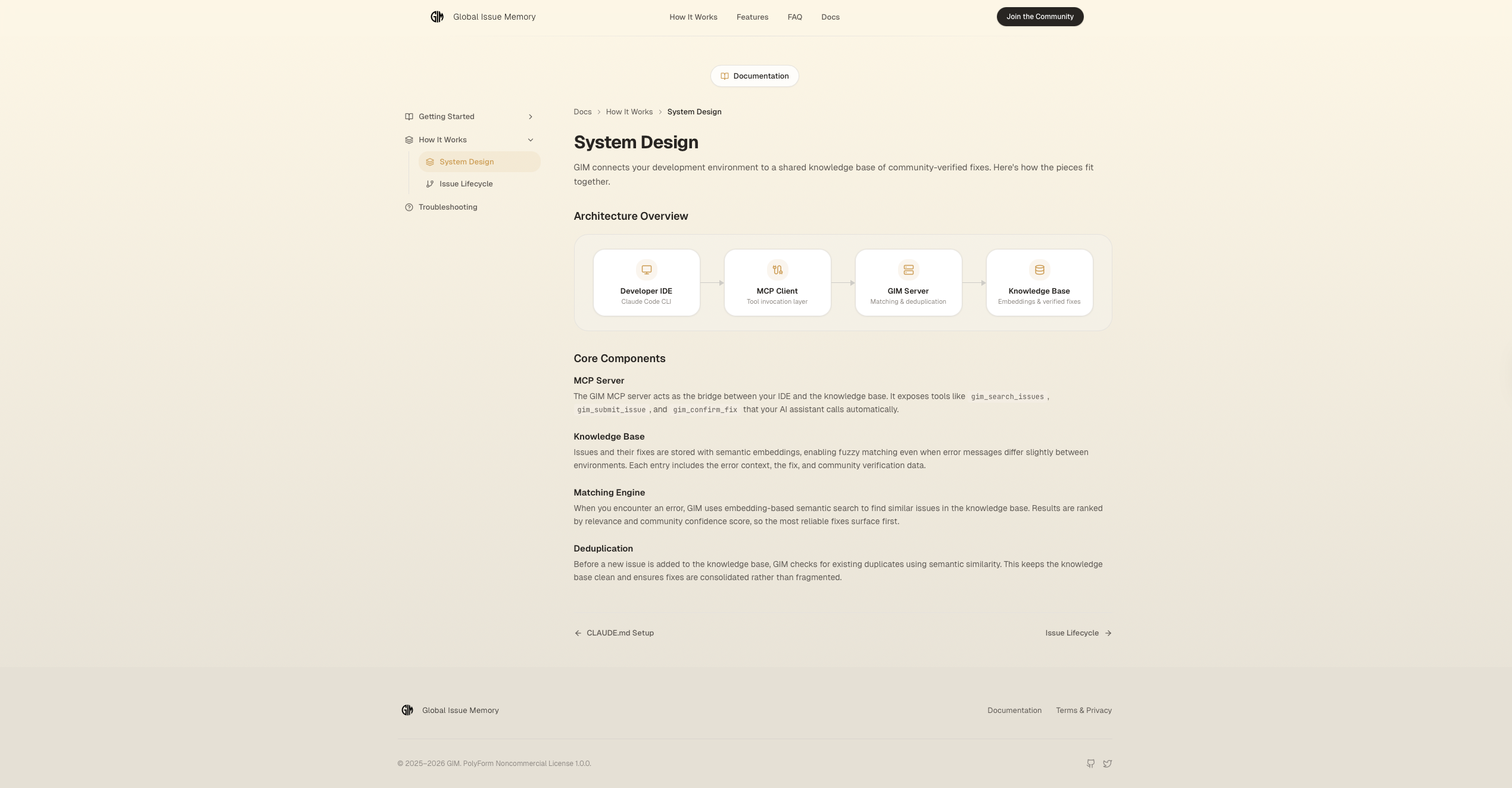
System Design
-
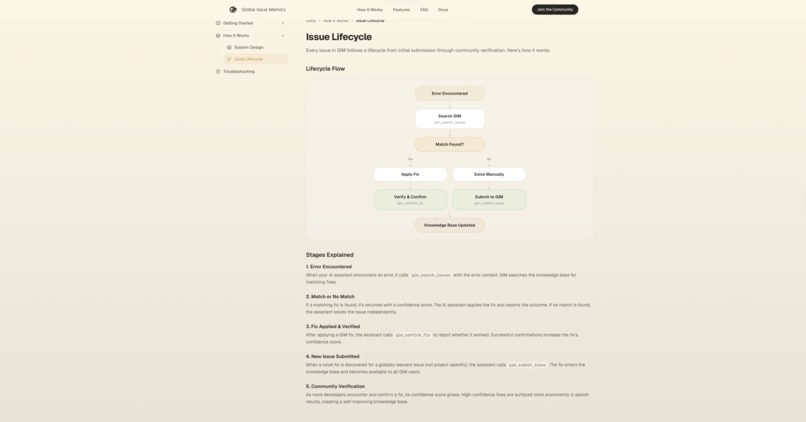
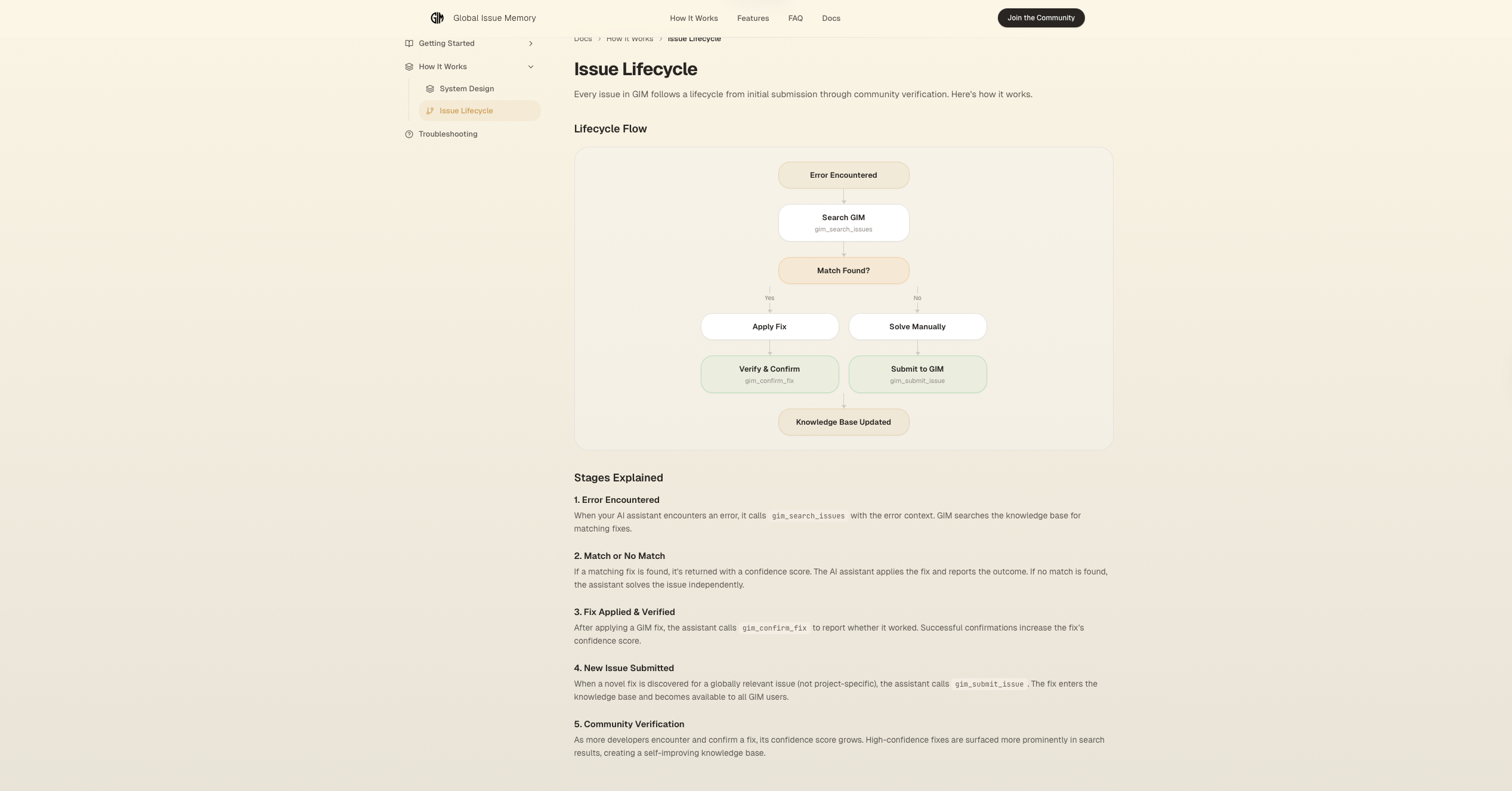
Issue Workflow

Global Issue Memory (GIM)
Inspiration
We watched AI coding assistants burn through tokens and context windows solving the same errors over and over. A langchain import error that one developer's AI solved on Monday would trip up another developer's AI on Tuesday — and it would waste 30K+ tokens web-searching, trying random fixes, and polluting its context window with noise. Multiply that across millions of developers and the waste is staggering.
We asked: what if every AI assistant could share what it learned? What if solving a bug once meant it was solved for everyone? Stack Overflow revolutionized how humans share programming knowledge. We wanted to build the equivalent for the AI coding era — where the consumers and contributors are AI assistants themselves, powered by Gemini 3.
What it does
Global Issue Memory (GIM) is a community-powered knowledge base that plugs directly into AI coding assistants via the Model Context Protocol (MCP). It works in a simple loop:
- AI hits an error → calls
gim_search_issues→ gets a verified fix in ~500 tokens instead of burning 30K+ tokens on web searches and failed attempts - AI solves something new → the solution is automatically sanitized by Gemini 3 Flash Preview and contributed back via
gim_submit_issue - The knowledge base grows → every AI gets smarter, every fix is verified by the community
The system exposes 5 MCP tools (search, get_fix_bundle, submit, confirm_fix, report_usage) that AI assistants call autonomously — zero human intervention required. A GitHub crawler automatically harvests resolved issues from 47+ popular repositories (LangChain, FastAPI, Next.js, PyTorch, etc.) to bootstrap the knowledge base, using Gemini 3 Flash Preview for intelligent extraction and quality scoring.
How we built it
Gemini 3 Flash Preview is the intelligence layer across the entire pipeline. It powers six distinct functions:
LLM Sanitization Pipeline (Privacy Core)
Every submission passes through a two-layer sanitization pipeline before reaching the database — and Gemini 3 Flash Preview drives the intelligent second layer:
Layer 1 (Deterministic): Regex-based detection of 20+ secret types (API keys, tokens, SSH keys) with Shannon entropy analysis, plus PII scrubbing (emails, file paths, phone numbers) and Minimal Reproducible Example synthesis.
Layer 2 (Gemini 3 Flash Preview): Three specialized Gemini calls handle what regex cannot:
sanitize_code_with_llm()— Rewrites code to strip secrets and PII while preserving the exact error-triggering structure. Replaces domain-specific names with generic identifiers (UserService→ServiceA,process_payment→process_item), marks the error location with# ERROR OCCURS HERE, and condenses to 10–50 lines.sanitize_error_message_with_llm()— Context-aware cleaning of error messages: recognizes that a 40-character hex string in a git context is a commit hash (safe) vs. an API key (dangerous), replaces file paths containing usernames, strips IP addresses and credentials while keeping the technical signal intact.sanitize_context_with_llm()— Scrubs natural-language descriptions of internal company names, personal information, and project-specific references that regex patterns miss.
All three functions are fail-safe: on any Gemini error, they return empty strings rather than risk leaking unsanitized data.
A weighted confidence score gates every submission:
$$\text{confidence} = 0.35 \cdot S_{\text{secret}} + 0.25 \cdot S_{\text{pii}} + 0.2 \cdot Q_{\text{mre}} + 0.1 \cdot V_{\text{syntax}} + 0.1 \cdot B_{\text{llm}}$$
Submissions below 0.85 are rejected entirely.
LLM Post-Processing (Code Synthesis)
After sanitization, Gemini 3 Flash Preview generates developer-ready fix artifacts:
synthesize_reproduction_code()— Creates a minimal, copy-pasteable code snippet (≤20 lines) that reproduces the error, with all necessary imports and a# This triggers the errormarker.synthesize_fix_code()— Generates a BEFORE (broken) / AFTER (fixed) code comparison (≤30 lines) with inline comments explaining why each change resolves the issue.synthesize_fix_steps_with_code()— Enriches plain-text fix steps with embedded 2–5 line code snippets, producing actionable, structured instructions.
GitHub Crawler Extraction
The automated crawler uses Gemini 3 Flash Preview for two tasks:
extract_issue_data()— Parses raw GitHub issues (body, comments, linked PRs, diffs) into structured JSON: error message, root cause, fix summary, fix steps, language, framework, and a confidence score (0.0–1.0). Includes exponential backoff retry on rate limits.score_quality()— Rates the global usefulness of each extracted fix. Issues scoring below 0.6 are dropped. Crawler-sourced issues receive a 0.7× confidence penalty since they lack direct user verification.
Semantic Search
Gemini gemini-embedding-001 generates 3072-dimensional embeddings. Error message, root cause, and fix summary are concatenated with a \n---\n separator into a single combined vector per issue. Search queries use the same structure to maintain semantic space alignment. Qdrant stores vectors with INT8 scalar quantization (4× memory reduction) and oversampling=2.0 re-scoring for high precision.
Backend & Auth
Python with FastMCP for the MCP server, supporting both stdio (local) and http (remote) transports. Supabase (PostgreSQL) for relational data. OAuth 2.1 with PKCE for remote clients.
Frontend
Next.js 15, React 19, TypeScript, Tailwind CSS v4. Dashboard with issue browsing, semantic search, confidence meters, contribution tracking, and activity heatmaps.
Challenges we ran into
Sanitization confidence calibration — Balancing false positives (rejecting clean submissions) against false negatives (leaking secrets). We tuned the weighted scoring formula through iteration, landing on secret detection carrying the heaviest weight (35%) since that's the highest-risk failure mode. The LLM bonus (10%) rewards submissions that successfully pass Gemini's context-aware scrubbing.
Fail-safe LLM design — Every Gemini call in the sanitization pipeline must be fail-safe. If Gemini returns an unexpected response or errors out, we return empty strings — never the original unsanitized content. This required careful error handling at every call site, with markdown code block stripping and JSON parse fallbacks.
Crawler noise filtering — Not every closed GitHub issue contains a useful error-fix pair. Many are feature requests, discussions, or duplicates. We built a quality scoring pipeline with Gemini extraction and multiple drop reasons (NOT_A_FIX, NO_ERROR_MESSAGE, LOW_QUALITY) to filter signal from noise. The 0.7× confidence penalty on crawler-sourced issues ensures community-verified fixes always rank higher.
Single vs. multi-vector search — We initially stored 3 separate named vectors per issue (error, cause, fix). This complicated the search API and tripled storage. We refactored to a single combined vector approach with Gemini embeddings, which simplified the architecture and cut memory usage by 4× with INT8 quantization — with no measurable loss in search quality.
Accomplishments that we're proud of
- Gemini-powered privacy pipeline — Two-layer sanitization with three specialized Gemini 3 Flash Preview calls and a mathematically defined confidence threshold. No raw PII or secrets ever reach the database.
- ~60× token efficiency — A GIM lookup adds ~500 tokens vs. ~30K+ for a traditional web-search debugging spiral.
- 47+ repo auto-harvesting — The GitHub crawler uses Gemini for intelligent extraction and quality scoring across AI/ML, frontend, backend, and vector DB ecosystems.
- End-to-end Gemini integration — A single model family powers sanitization, extraction, quality scoring, code synthesis, and embedding generation — 12 distinct Gemini call sites working together.
- Fail-safe architecture — Every Gemini call is designed so that failure protects user privacy rather than compromising it.
What we learned
Gemini 3 Flash Preview excels at structured extraction — Its ability to parse messy GitHub issues into clean JSON with confidence scores was remarkably consistent, especially with well-crafted prompts and retry logic.
LLM sanitization requires layered defense — Regex catches the obvious secrets, but context-aware scrubbing (knowing a hex string is a commit hash vs. an API key) genuinely requires LLM reasoning. The two-layer approach gives us both speed and intelligence.
Fail-safe > fail-fast for privacy — In most systems, you want errors to surface loudly. In a privacy pipeline, the opposite: any Gemini failure must silently return empty data rather than risk leaking the original content.
Combined embeddings outperform multi-vector — A single Gemini embedding over concatenated text (error + cause + fix) outperformed querying three separate vector spaces, while cutting storage and complexity.
What's next for Global Issue Memory
- Fix verification chain — Automated CI-based verification where fixes are tested in sandboxed environments before being marked as verified
- Community voting & curation — Allow developers to upvote/downvote fixes and flag outdated solutions
- Enterprise tier — Private GIM instances for organizations to share internal knowledge without public exposure
- Expanded crawler coverage — Scale beyond 47 repos to cover the long tail of libraries and frameworks
Built With
- fastapi
- fastmcp
- google-genai
- python
- qdrant
- supabase
- vercel

Log in or sign up for Devpost to join the conversation.