-
-

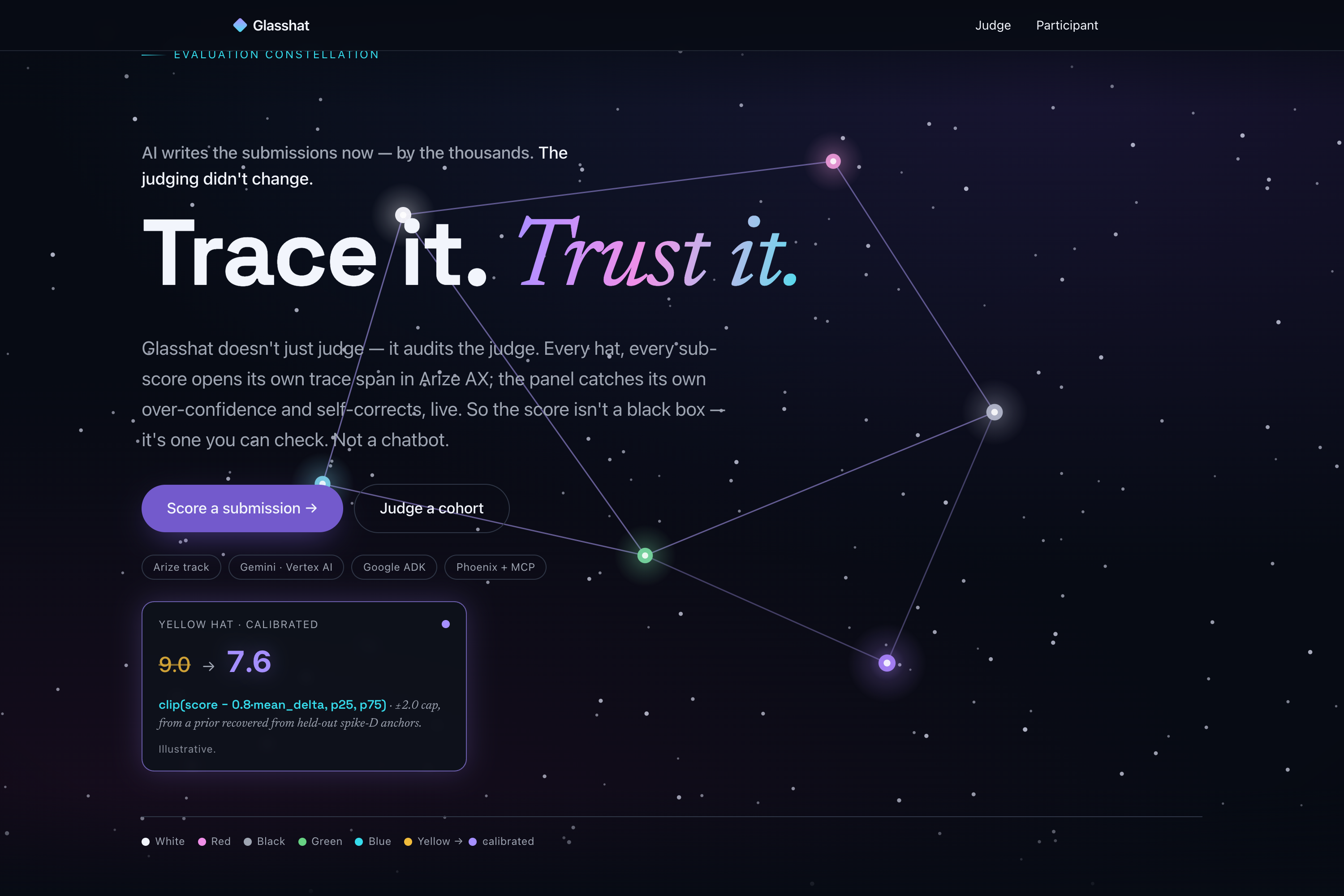
9.0 → 7.6: the optimism hat over-scores, the audit pulls it back to where the evidence holds — with the math shown, capped at ±2.0.
-
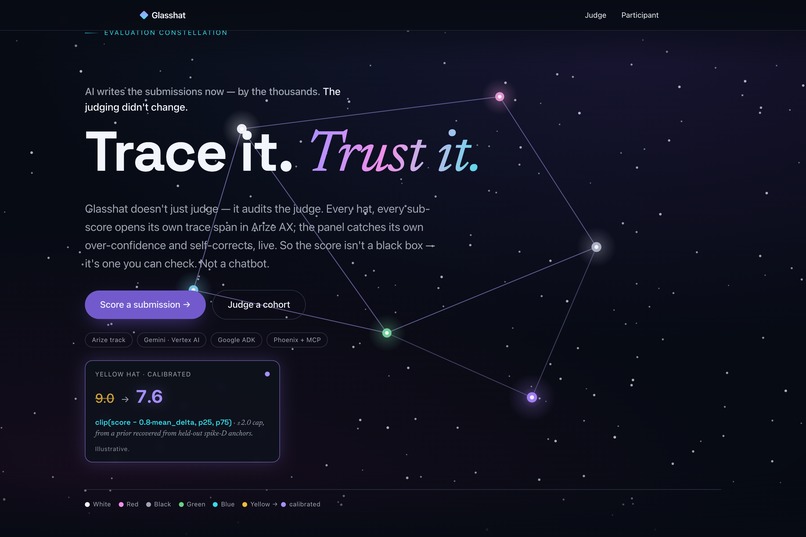
Trace it. Trust it. — a six-hat evaluator that audits the judge, with every sub-score a trace span in Arize AX.

Inspiration
We kept seeing the same problem at hackathons, grant rounds, and promo committees: nobody audits the judge.
A human judge can skim ten submissions at midnight and pick three. An AI judge can do the same thing faster, with more confidence, and with less of a paper trail. As more submissions become AI-assisted, simply adding an AI judge does not automatically make evaluation fairer. It can scale the same blind spots.
So we asked the obvious question: who audits the judge?
Glasshat is our answer.
What it does
Glasshat takes three inputs: a pitch deck, a GitHub repo, and the evaluator's own rules.
It turns the rules into a contest-specific rubric, then runs a six-hat evaluation panel based on the de Bono hats: White, Red, Yellow, Black, Green, and Blue. Each hat looks for different evidence and scores every criterion from its own angle.
Then Glasshat audits itself.
If one hat is too optimistic, too harsh, or too confident without enough evidence, Glasshat compares that score against a calibration prior and adjusts it live. The correction is not hidden behind a vague “AI confidence” label. The math is shown on screen:
clip(score − 0.8·mean_delta, p25, p75), capped at ±2.0.
So an overconfident 9.0 can recede to a more defensible 7.6, and the user can see why.
Across a full cohort, Glasshat shows what actually changed after recalibration. Sometimes the ranking moves. Sometimes it does not. On our held-out set of past winners, the top-13 did not move at all after recalibration, and we show that too. We would rather display “no change” honestly than fake a dramatic reshuffle.
Glasshat is an evaluation pipeline and fairness monitor in one.
It is not a chatbot.
How we built it
The core model is Gemini 3.1 Flash-Lite on Vertex AI, using the global endpoint. Embeddings use text-embedding-005. Retrieval is handled in code with cosine search, BM25, and reciprocal rank fusion over an in-memory index, so the demo does not depend on a rented vector database.
The agent runs as a real Google ADK 2.0 workflow:
ingest → synthesize rubric → plan → fan out six hats in parallel → join → audit → score.
We also deployed it on the Gemini Enterprise Agent Platform through Vertex AI Agent Engine. The live agent serves stream_query at reasoningEngines/7480191458771730432, while the credential-free Cloud Run demo runs the same Python path so anyone can try it without keys.
Arize is not just an add-on here. Every agent and every hat becomes its own span in Arize AX through OpenInference and OTLP, creating a nested trace tree. In one two-query capture, we recorded 104 spans.
The calibration loop runs through the Arize Phoenix MCP server. Each evaluation reads the glasshat-calibration dataset over MCP and writes its corrections back per request against a Phoenix instance on Cloud Run and Cloud SQL. That means the calibration dataset grows with every run.
We also ran an Arize AX experiment over a golden set of past projects with a prompt-injection evaluator. Glasshat reached hit@13 = 0.6154, with 8 of 13 known winners landing in the predicted top-13, compared with 0.26 by chance.
The frontend is a Next.js PWA with a live SSE trace, a 3D evaluation constellation, and a recalibration board. The repo is a uv Python monorepo with 323 Python tests, 74 web tests, and a CI gate that blocks general-purpose LLM SDKs. The stack is Google and Arize only.
Challenges we ran into
The hardest part was making the MCP loop real.
The consult/write path had never run against a live Phoenix instance before. When we connected it for the first time, it exposed three bugs that had been hiding in plain sight: a reversed p25/p75 bound, a misnamed tool argument, and a response wrapper we were not unwrapping.
Fixing those bugs is what turned the project from “wired up” into something that actually round-trips.
The other challenge was staying honest. With only one measured corpus, it would have been easy to invent per-rubric performance numbers. We did not. We shipped the mechanism, seeded it with real held-out anchors, and clearly labeled illustrative numbers as illustrative.
Accomplishments that we're proud of
Glasshat is live, reproducible, Apache-2.0, and backed by self-correction you can inspect and re-run.
The Phoenix-MCP consultant is enabled by default, so the audit loop already improves as evaluations accumulate. The recalibration board also tells the truth when nothing changes. If the ranking holds, it shows Δ=0.
That honesty is part of the product.
What we learned
“Audit the judge” is a stronger frame than “build a better judge.”
Bias becomes easier to discuss when it stops being a vibe and becomes a number you can bound, trace, and correct. We also learned that agent work is mostly observability work. Without the Arize AX trace tree, we would have been guessing where each score came from.
What's next
Next, we want to turn on hardened structured scoring for judged instances, add judge authentication, and keep building genuinely per-rubric calibration as the Phoenix dataset fills in.
Built With
- agent-engine
- arize
- arize-ax
- arize-phoenix
- cloud-build
- cloud-run
- cloud-sql
- docker
- fastapi
- gemini
- gemini-3.1-flash-lite
- gemini-enterprise-agent-platform
- google-adk
- google-cloud
- mcp
- next.js
- openinference
- opentelemetry
- python
- rank-bm25
- react
- secret-manager
- tailwindcss
- text-embedding-005
- three.js
- typescript
- uv
- vertex-ai



Log in or sign up for Devpost to join the conversation.