💡 Inspiration
Two facts collided for us. First, modern intrusions move at machine speed — an AI-assisted attacker can go from foothold to domain compromise in about eight minutes. No human responder triages evidence that fast.
The obvious answer is to put an autonomous AI on the evidence. But that breaks two sacred rules of digital forensics. AI agents hallucinate — Anthropic's own threat report on the GTG-1002 operation noted that Claude "frequently overstated findings and occasionally fabricated data." And worse, an agent with shell access can modify the very evidence it's supposed to protect, destroying chain of custody.
So we asked: can you build an autonomous DFIR agent that is structurally incapable of doing either? Not "asked nicely in a prompt" — incapable by construction. That question became GLASSBOX.
🔍 What it does
GLASSBOX is an autonomous, read-only DFIR triage agent for the SANS SIFT Workstation. It's a glass box, not a black box: every single finding traces back to the exact tool call that produced it.
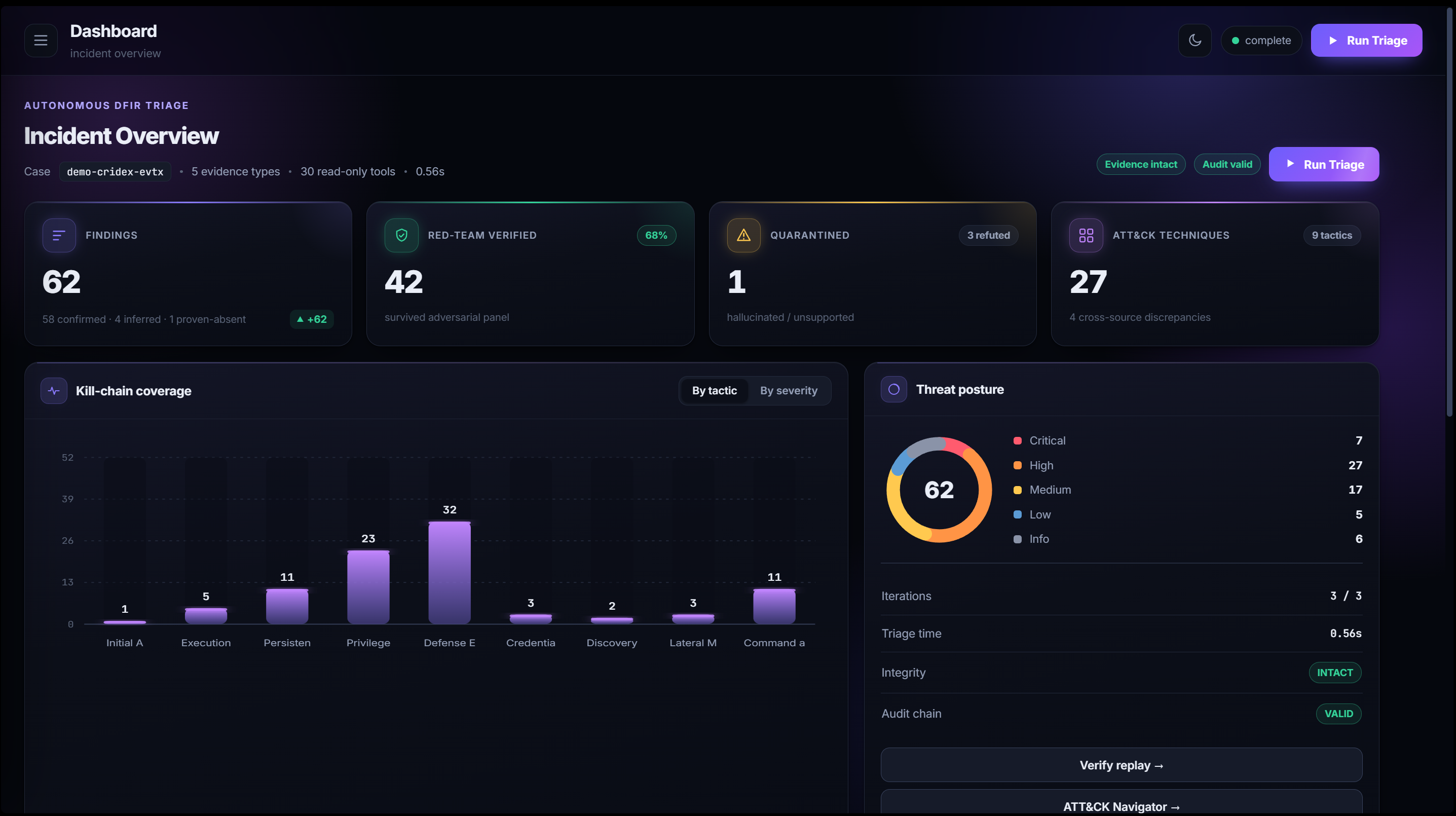
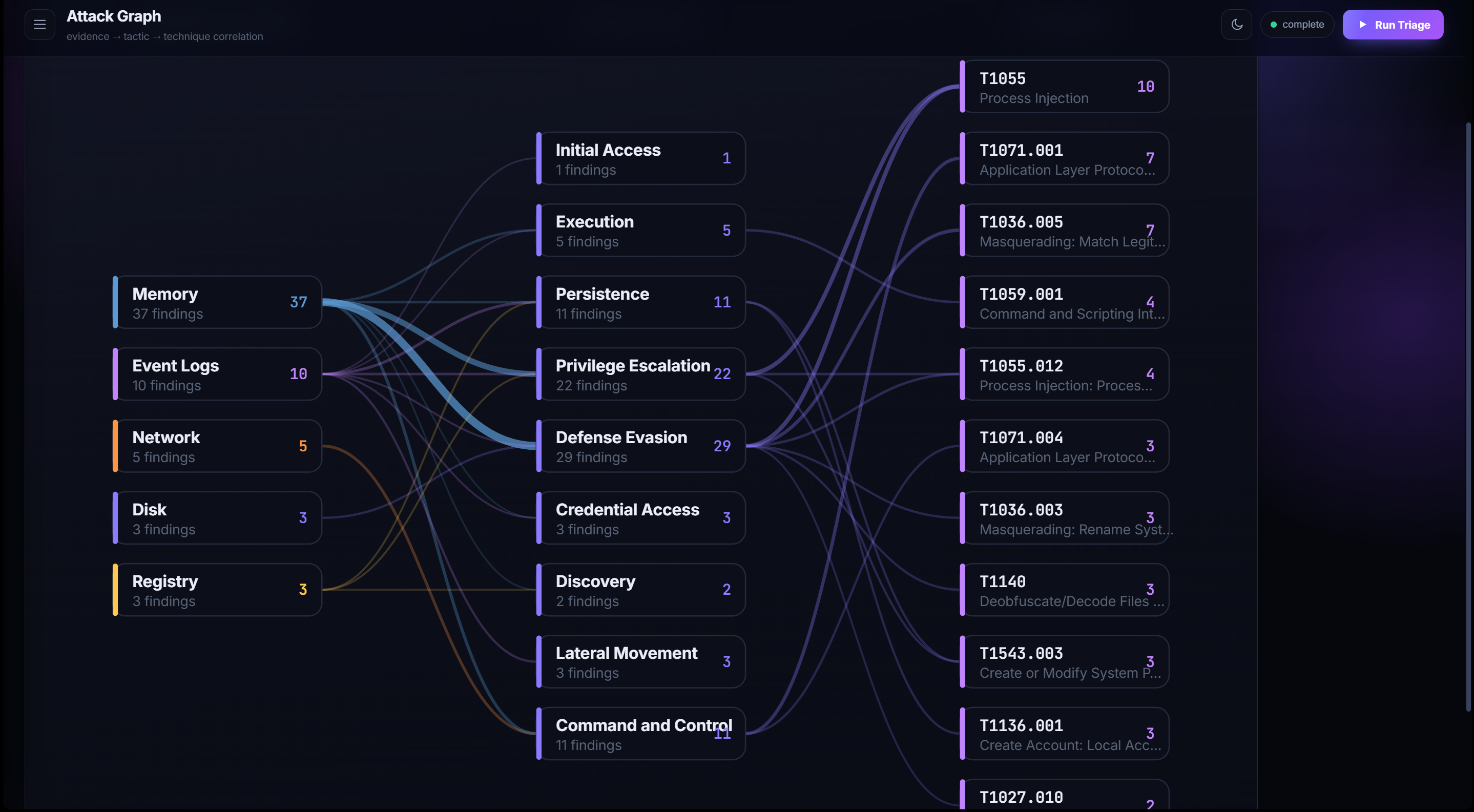
Point it at a case and it hashes the evidence, plans which read-only tools to run, collects artifacts across disk, memory, event logs, network, and registry, correlates them, maps everything to MITRE ATT&CK, then verifies and adversarially red-teams every claim — all in under a second on our Cridex banking-trojan demo (62 grounded findings, 5 evidence types).
What makes it trustworthy:
- Read-only by construction — the MCP tool surface exposes 30 read-only tools and zero destructive ones. There is no write/delete/shell tool to misuse, so spoliation isn't blocked, it's impossible.
- A mechanical hallucination gate — a finding is admitted only if its cited value actually appears in the captured tool output. Formally, a finding \( f \) with cited value \( v \) and captured output \( O \) is admitted iff \( v \in O \); otherwise it is quarantined. The model cannot talk its way to CONFIRMED.
- An adversarial red-team panel — skeptics attack every surviving claim; only ones that hold up are reported as fact.
- Break-the-Chain — our favorite demo. We corrupt a single byte of evidence on purpose; the affected finding can no longer be re-derived and drops from the report, the audit hash chain snaps, and the real case stays byte-for-byte untouched. Tampering isn't just blocked — it's demonstrably caught.
- ABHAVA (proving a negative) — GLASSBOX states and verifies "no ransomware encryption on this disk," grounded the same way every positive finding is.
- A court-ready, replayable, hash-chained audit trail.
🛠️ How we built it
The agent is a LangGraph state machine, not a chatbot — a bounded graph of nodes: intake → plan → collect → correlate → map ATT&CK → verify → red-team → critique → report, with a self-correction loop capped in code.
Three design choices carry the whole project:
The tool boundary is the security boundary. Instead of a guardrail prompt, we give the agent a read-only MCP toolkit. If a capability isn't in the toolkit, it doesn't exist for the agent.
Verification is code, not a prompt. The hallucination gate re-reads the raw captured output and does a literal containment check — it never asks the model whether it's sure.
Integrity is cryptographic. Every audit record links to the previous one:
$$ h_i = H\left(h_{i-1} \,\Vert\, e_i\right) $$
Alter any record \( e_i \) and every subsequent hash \( h_{i+1}, h_{i+2}, \dots \) breaks — the same tamper-evidence a blockchain uses, applied to chain of custody.
On top sits a zero-dependency dashboard (vanilla JS, server-sent events for the live triage stream) with a Live Triage trace, an Attack Graph (an evidence → tactic → technique node-link diagram), a graph-led Timeline, and the Break-the-Chain and guardrail self-test demos. It's deployed as a long-running web service on Render.
📚 What we learned
- "Architectural vs. prompt-based" is the whole ballgame in agent safety. Anything enforced in Python and verified against raw bytes survives adversarial pressure; anything enforced by instruction does not.
- You can prove a negative — but only if you re-read the evidence and check for absence as rigorously as you check for presence.
- Determinism is a feature. Because runs are reproducible from the audit log + raw store, a judge can take any finding ID and replay exactly how it was derived.
- A surprising amount of "AI trust" turns out to be plain old engineering — containment checks, hashing, and bounded loops — wrapped around the model rather than baked into it.
🧗 Challenges we ran into
- Making tampering visible, not just prevented. Blocking writes is easy; demonstrating that the system catches a flipped byte required cloning a case, mutating one byte, and re-running deterministic replay so the finding visibly drops and the chain visibly snaps.
- Closing hallucination loopholes. Naive substring grounding lets vague locators match anything, so we had to tighten what counts as "physically present" in the output.
- Keeping it fast and offline. The demo runs with no SIFT, no API key, and no network — forensically deterministic — which meant building replayable fixtures for real Volatility/EVTX/registry artifacts.
- A live UI over a streaming agent. Streaming the node-by-node trace over SSE while preserving it after completion (and not wiping it on refresh) took real care.
🚀 What's next
Locator-specificity guards, raw-corroboration and temporal-consistency skeptics, and a bearer-token guardrail for the web surface — each one closing another gap between "the AI says so" and "the evidence says so."

Log in or sign up for Devpost to join the conversation.