-
-
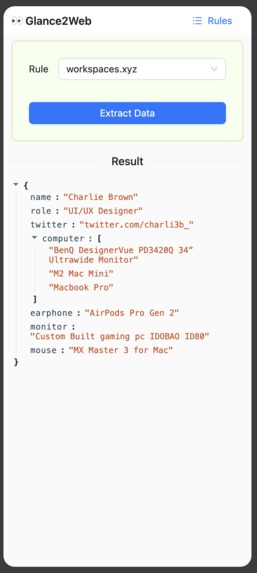
home page (extract result)
-
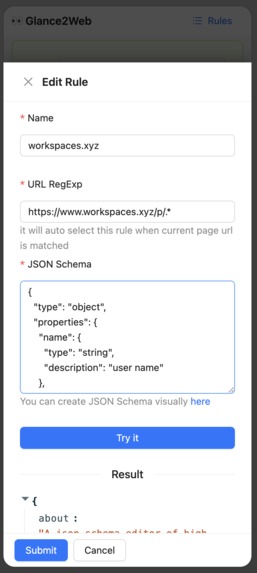
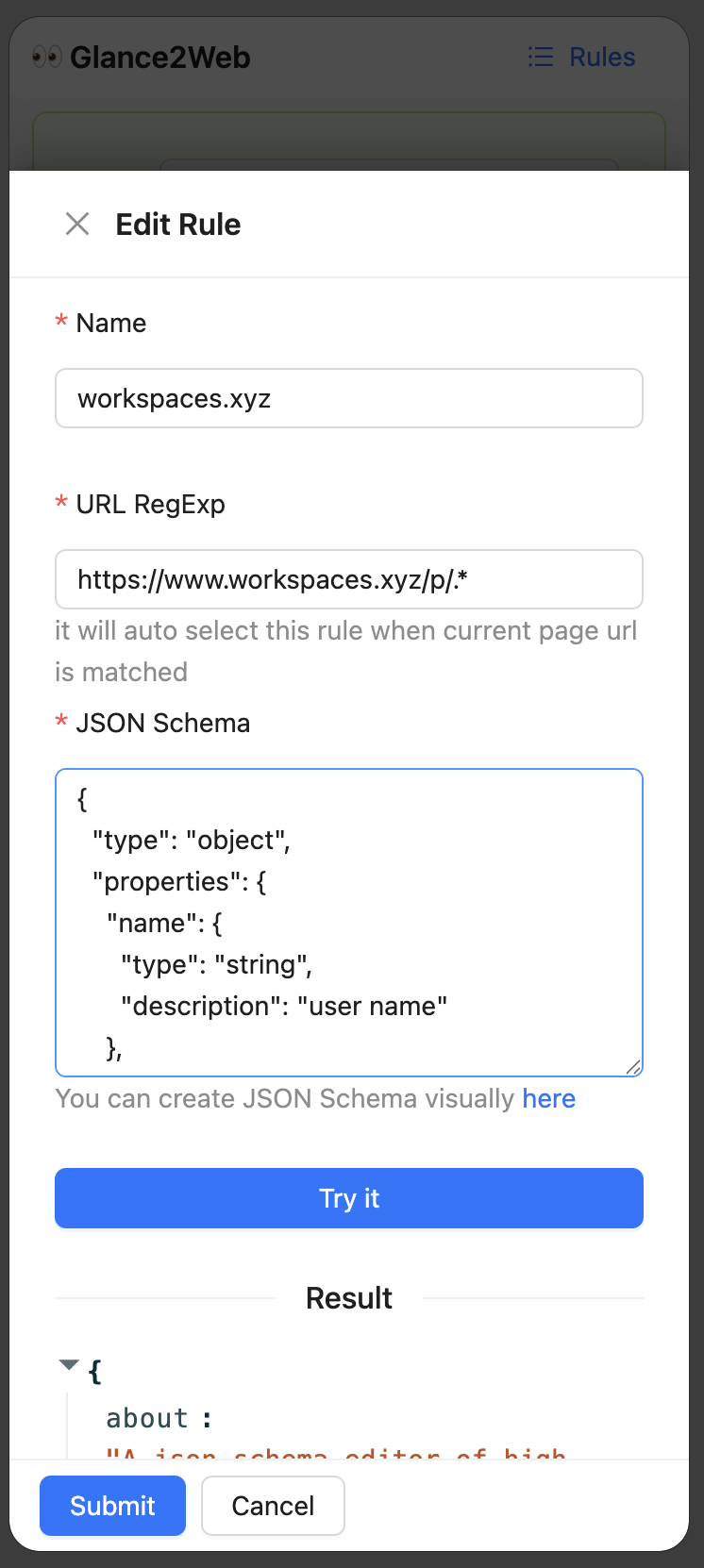
edit rule and debug
-
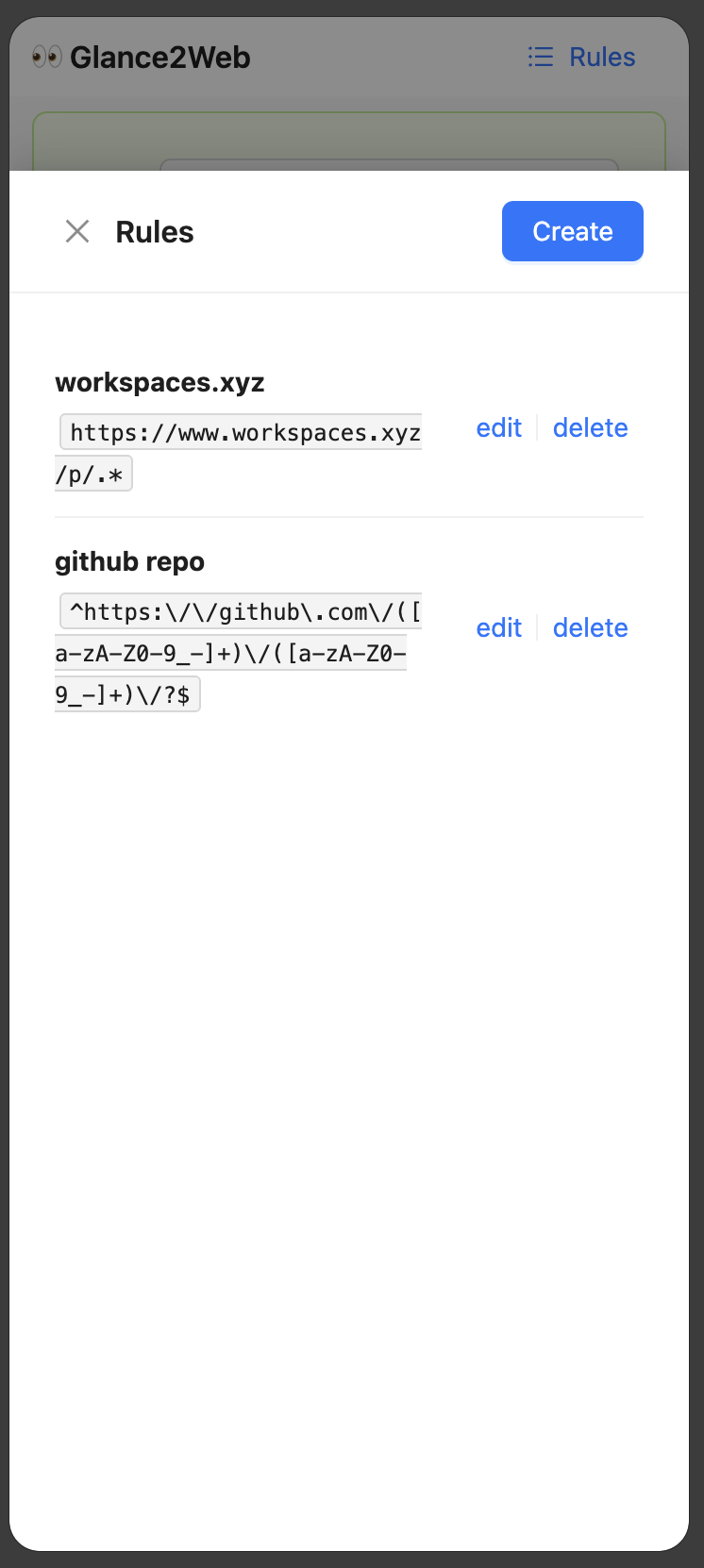
rule list
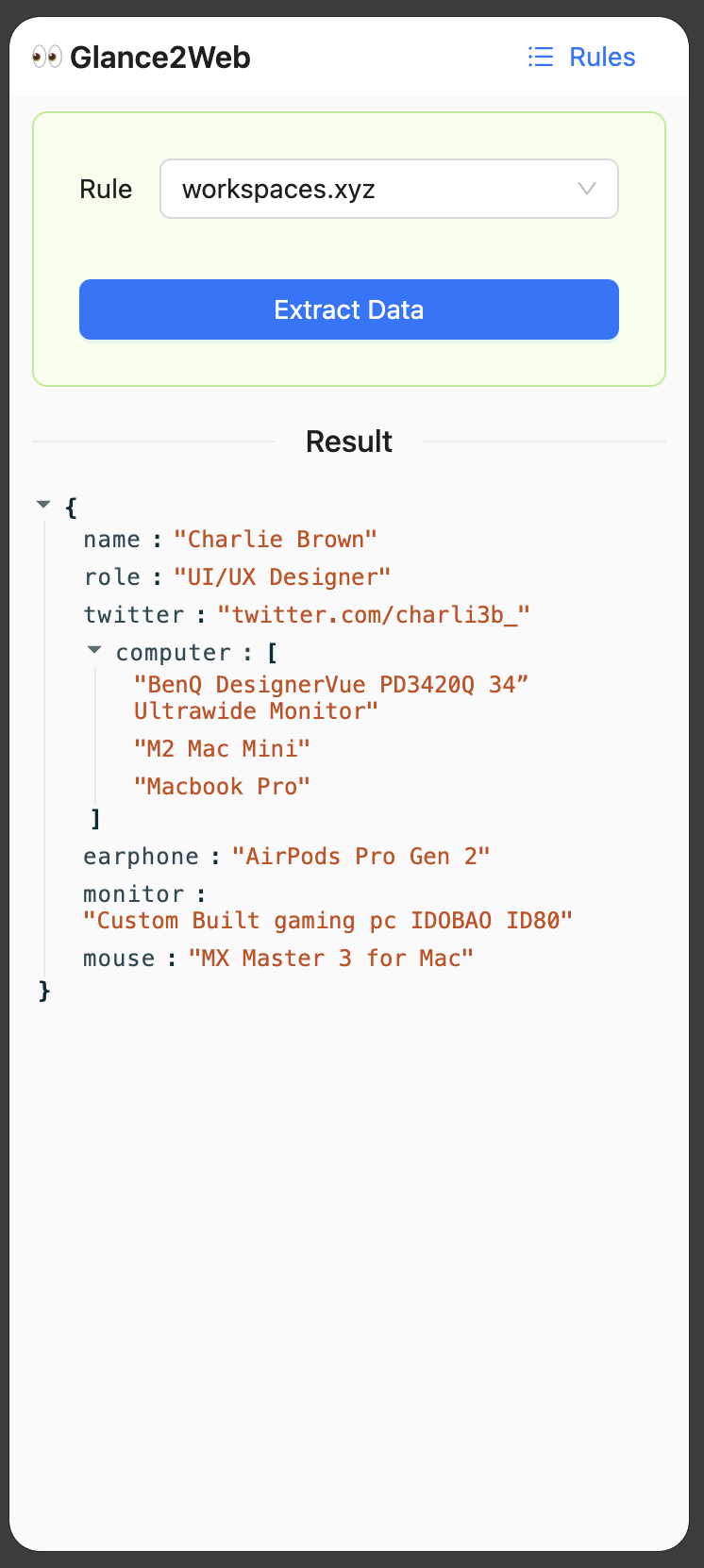
Inspiration
- In my daily work, sometimes I want to quickly obtain some key information from web pages. I think AI can help do this (understand and extract web page content).
- I build some chrome extensions in my company, I think extension has two major advantages: able to perceive 「what's on the page」 and 「what the user is doing」. I have tried to use engineering methods to leverage these capabilities, but it's not good enough in terms of accuracy and generalization ability, I believe AI can use these capabilities more efficiently. So when gemini nano is ready, I'm excited to try it further
What it does
User Input JSON Schema, AI outputs JSON data on the page. User can provides a JSON Schema to describe what kind of content they want to get from the web page, and sets the matching URL rules. When the URL is accessed, the JSON data that conforms to the previously set JSON Schema can be extracted from the web page with one click.
How we built it
I have experience in plugin development in my company. I chose the Plasmo framework to help me quickly build the basic UI and interaction logic of the plugin, and used the Prompt API to extract JSON data from the web page.
Challenges we ran into
Due to the token number limit, I trimmed the content of the web page and only kept the text content (this may lead to poor recognition of some pages. We can consider how to optimize it in the future, and I believe the token limit will also increase)
Accomplishments that we're proud of
I spent about a week on the idea and only spent about five hours writing the code. I think the offline model provides a very efficient development experience. I don’t need to consider model deployment issues, I just need to focus on business logic. In addition, data security is a very important issue within my company. The offline model does not have data security risks, so we can use it in some internal tools of the company.
What we learned
I think understanding the content on the web page is a very important advantage of Chrome extension. In order to make use of this advantage, we must face the problem of how to compress the long HTML content to a length that the model can handle. Although this is still a simple implement so far. I have some ideas, such as retaining the necessary HTML tags and aria attributes. I think this work will be very valuable.
What's next for Glance2Web
- optimize the logic of compress HTML,make it reserve more key information and keep the size small
- Good rules can be shared with other users, I may build a communicate in future
- Add an automated mechanism to extract content from multiple web pages at once
- Optimize the overall user interaction experience, make extension is more easy to use in many scene
Built With
- plasmo
- prompt-api
- react
- typescript



Log in or sign up for Devpost to join the conversation.