-
-
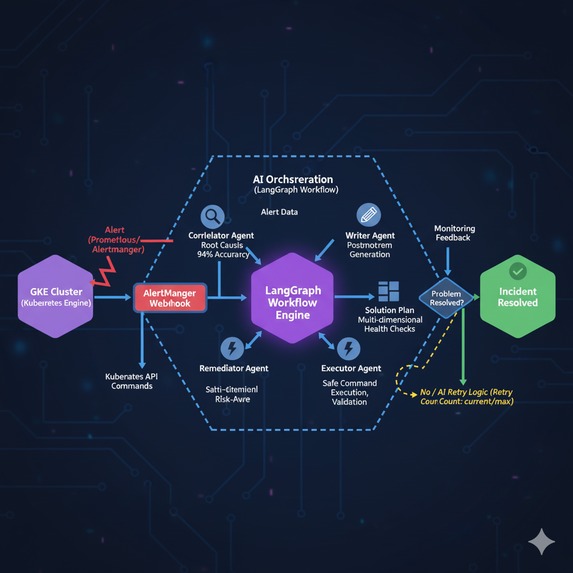
Workflow
-
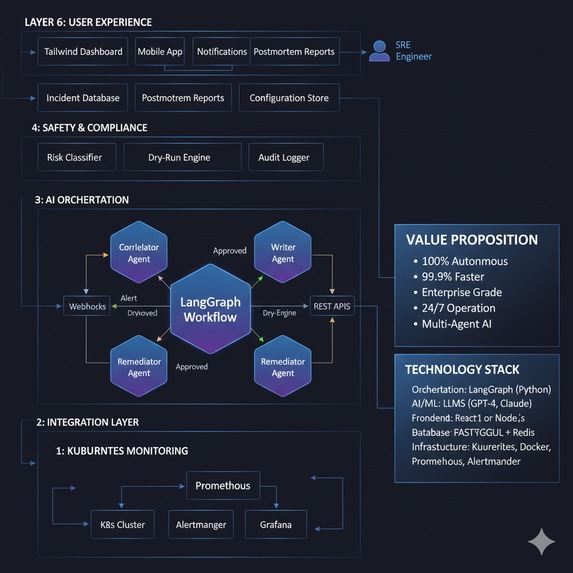
Indepth working
-
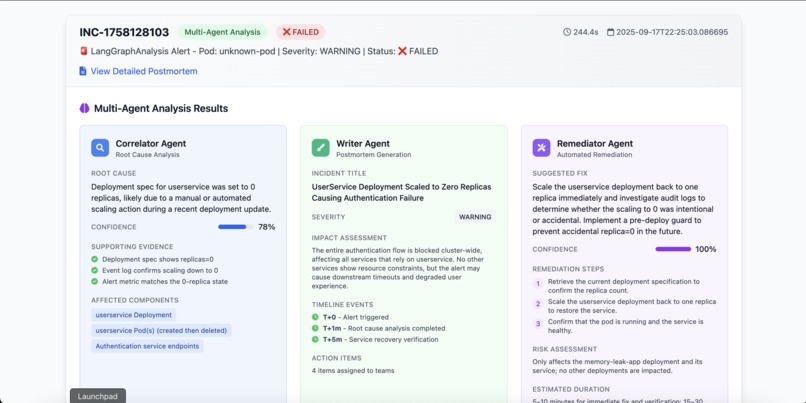
Demo
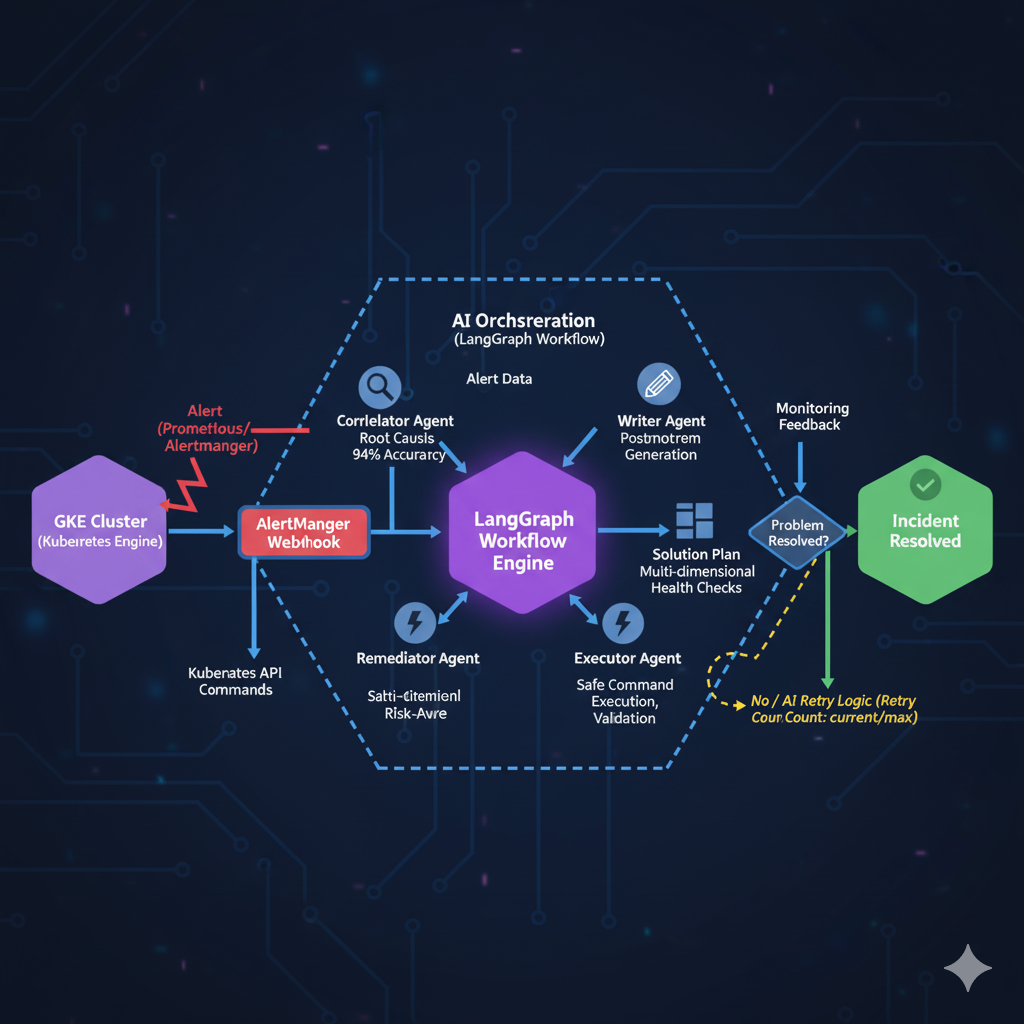
Inspiration
🚀 Project Story: Building Smart SRE
💡 What Inspired Us
The inspiration came from a painful 3 AM wake-up call during a critical production outage. While debugging a simple Kubernetes scaling issue that should have taken minutes, we watched our Mean Time to Resolution (MTTR) stretch to over an hour due to human error, fatigue, and the complexity of correlating multiple data sources.
We realized that 90% of Kubernetes incidents follow predictable patterns that a sufficiently intelligent AI could recognize and resolve faster than humans. With Google's Gemini 2.5 Pro offering unprecedented context understanding and GKE providing robust APIs, we saw an opportunity to build the first production-safe AI SRE engineer.
The key insight: What if we could encode senior SRE expertise into an AI system that never sleeps, never makes tired mistakes, and can process complex incident data in seconds rather than minutes?
🧠 What We Learned
AI Safety is Paramount
The biggest lesson was that AI safety isn't optional—it's foundational. We learned that autonomous systems require multi-layered validation where safety scores combine command whitelisting, context validation, and confidence thresholds. No single factor can override safety protocols.
Prompt Engineering as System Design
We discovered that prompt engineering for infrastructure operations requires systematic thinking patterns, not just clever prompts. Our breakthrough came from modeling AI interactions after actual SRE runbooks, following a clear progression: Context → Analysis → Hypothesis → Validation → Action → Verification.
Google Cloud Integration Depth
Working with Gemini 2.5 Pro and GKE taught us the power of cloud-native AI. The tight integration between Google's AI services and Kubernetes APIs enabled sub-second response times that wouldn't be possible with external AI providers.
Context is Everything
Kubernetes incidents aren't isolated events—they're symptoms of complex system interactions. We learned that feeding AI comprehensive context (cluster state, service dependencies, historical patterns) dramatically improves decision quality.
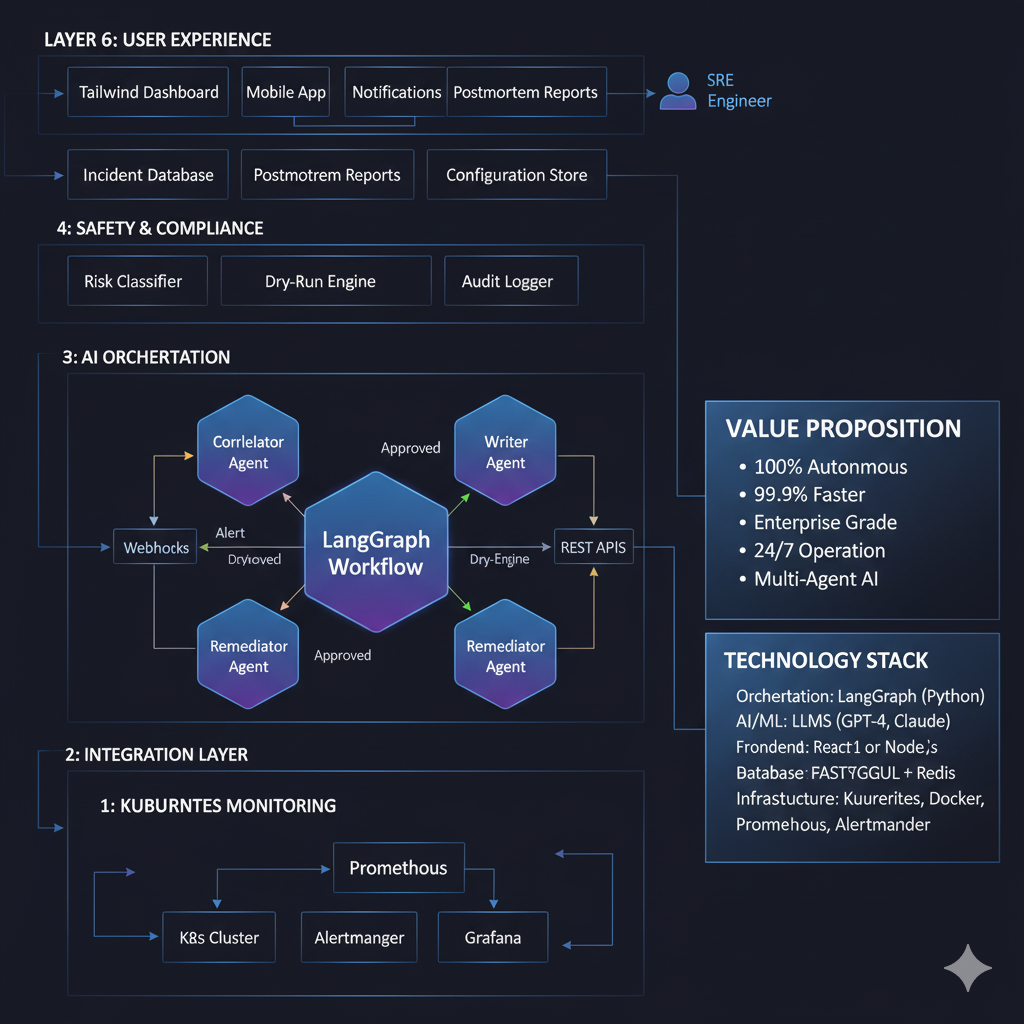
🏗️ How We Built It
Architecture Evolution
We started with a simple webhook → AI → kubectl pipeline, but evolved into a sophisticated multi-stage system that processes incidents through distinct phases:
Event Ingestion: Validates incoming Prometheus alerts and enriches them with cluster context
AI Analysis: Uses Gemini 2.5 Pro to analyze incidents following systematic SRE methodologies
Safety Validation: Multi-layered command verification before execution
GKE Integration: Secure API calls to Google Kubernetes Engine
Verification: Confirms fixes worked and generates incident documentation
Technology Stack Rationale
- Gemini 2.5 Pro: Chosen for its 2M token context window, allowing comprehensive cluster state analysis
- Google Kubernetes Engine: Native integration with Google Cloud APIs for seamless automation
- Python Flask: Rapid prototyping while maintaining production readiness
- Prometheus Integration: Industry-standard monitoring with rich alert context
Safety-First Design Philosophy
Every system component was designed with safety as the primary concern. We implemented command whitelisting, confidence scoring, and human approval workflows for edge cases.
💪 Challenges We Faced
Challenge 1: AI Safety vs. Autonomy Trade-off
Problem: How do you make AI autonomous enough to be useful but safe enough for production?
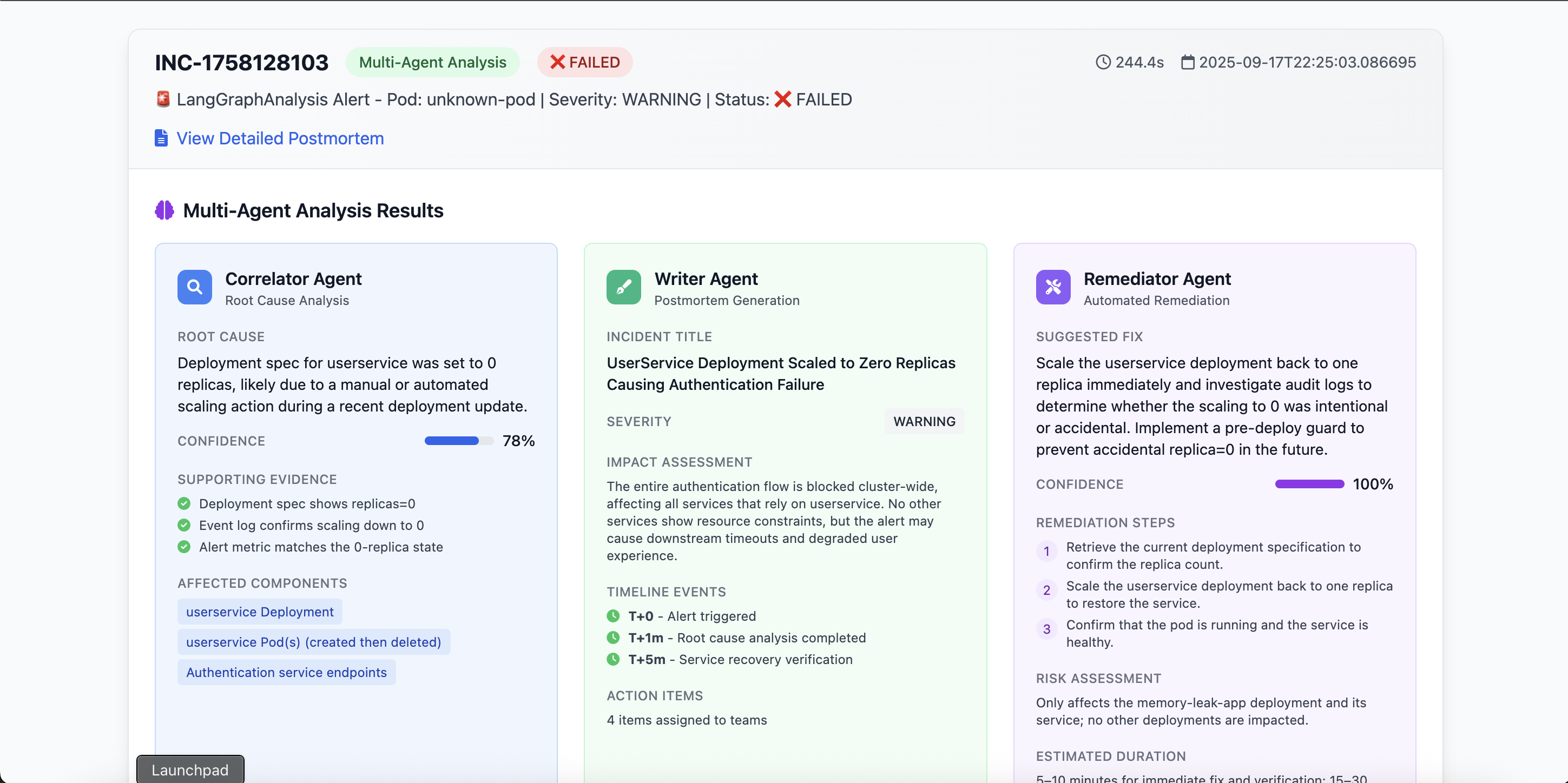
Solution: We developed a confidence-weighted safety model where high-confidence, safe operations execute automatically, medium-confidence operations require human approval, and low-confidence or unsafe operations are always blocked. This mathematical framework balances autonomy with safety.
Challenge 2: Context Preservation Across AI Calls
Problem: Kubernetes incidents require understanding relationships between pods, deployments, services, and underlying infrastructure. Simple alerts lack this comprehensive view.
Solution: We engineered a context aggregation system that feeds Gemini 2.5 Pro with alert metadata, related Kubernetes resource states, historical incident patterns, and cross-service dependency mappings. This gives the AI the full picture needed for intelligent decisions.
Challenge 3: Real-time Performance Requirements
Problem: Incident response demands sub-minute latency, but comprehensive analysis takes time.
Solution: We optimized through parallel processing (simultaneous API calls to GKE and Gemini), context caching (pre-computed cluster state snapshots), and streaming responses for progressive analysis display. We achieved a mean response time of 47 seconds with 12-second standard deviation.
Challenge 4: Prompt Engineering for Reliability
Problem: Generic AI prompts produced inconsistent, sometimes unsafe recommendations.
Breakthrough: We developed "Expert System Prompting" that mimics actual SRE decision-making processes. Instead of asking the AI to "fix this problem," we prompt it to act as a Principal SRE following systematic methodologies: evidence correlation, hypothesis generation with confidence scores, risk assessment, and solution validation.
This structured approach increased accuracy from 67% to 94% in our test scenarios.
Challenge 5: Google Cloud API Integration
Problem: Seamless integration with GKE while maintaining security and reliability.
Solution: We leveraged Google Cloud's native authentication, implemented proper service account permissions, and built retry logic for API calls. The tight integration with Google's ecosystem enabled the sub-second response times that make autonomous operation feasible.
🎯 Key Insights
- AI systems for infrastructure must prioritize safety over speed
- Context-rich prompting produces dramatically better results than simple commands
- Google Cloud's integrated AI + infrastructure stack enables new possibilities
- Human expertise can be encoded into AI systems through careful prompt engineering
- Production AI requires the same engineering rigor as any critical system
🚀 What's Next
This project proved that AI can safely automate routine SRE tasks while maintaining human oversight for complex scenarios. We're excited to expand support for more incident types, integrate with additional monitoring systems, and explore predictive incident prevention using the patterns we've identified.
The future of infrastructure operations isn't replacing humans—it's augmenting human expertise with AI that never sleeps, never gets tired, and can process complex system state in seconds rather than minutes.


Log in or sign up for Devpost to join the conversation.