-
-

Every AI review claim backed by a runnable Orbit graph query, its result, and its scope.
-
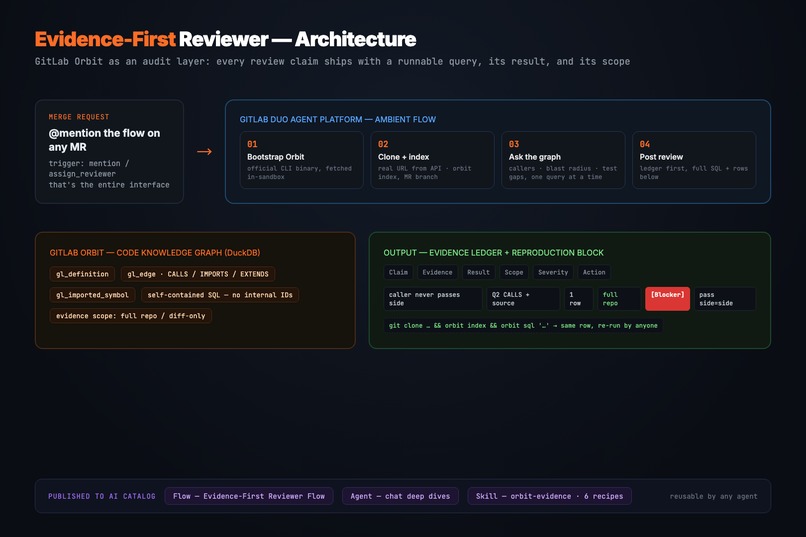
The Evidence Ledger: severity-tagged claims, each tracing to a query you can re-run yourself.
-
Mention an MR → flow bootstraps Orbit, indexes the branch, queries the graph, posts evidence.

Inspiration
AI code review has a hidden double cost. The review itself is cheap — but every claim it makes ("this might break callers", "consider adding tests") is unverifiable, so your team pays again to re-check it. GitLab's own Orbit research names this exact problem: agents are good at writing code but bad at understanding the system around it. GitLab proved Orbit makes AI review more accurate. We asked the next question: can Orbit make AI review auditable?
This isn't just static analysis: static analysis gives you results, while this flow binds agent review claims to Orbit queries, results, and limitations — so the review comment itself can be re-run and refuted.
What it does
Mention the flow on a merge request — that's the whole interface. It:
- Bootstraps the Orbit CLI in its sandbox, resolves the repo's real clone URL from the GitLab API, clones the MR source branch, and runs
orbit index. - Classifies its evidence scope:
full repo index(clone succeeded) ordiff-only index(fallback) — and every claim carries that scope. - Interrogates the code graph with self-contained SQL queries (definitions located by name + file path, never internal IDs — anyone can re-run them on a fresh index and get the same rows).
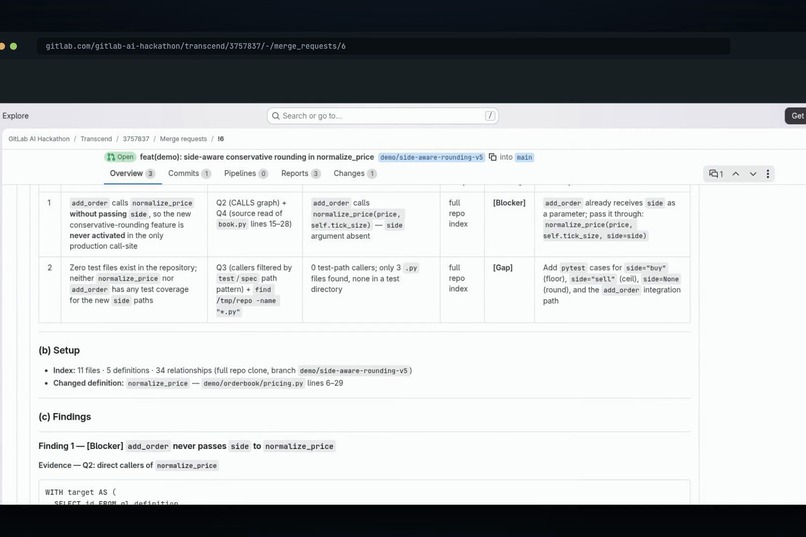
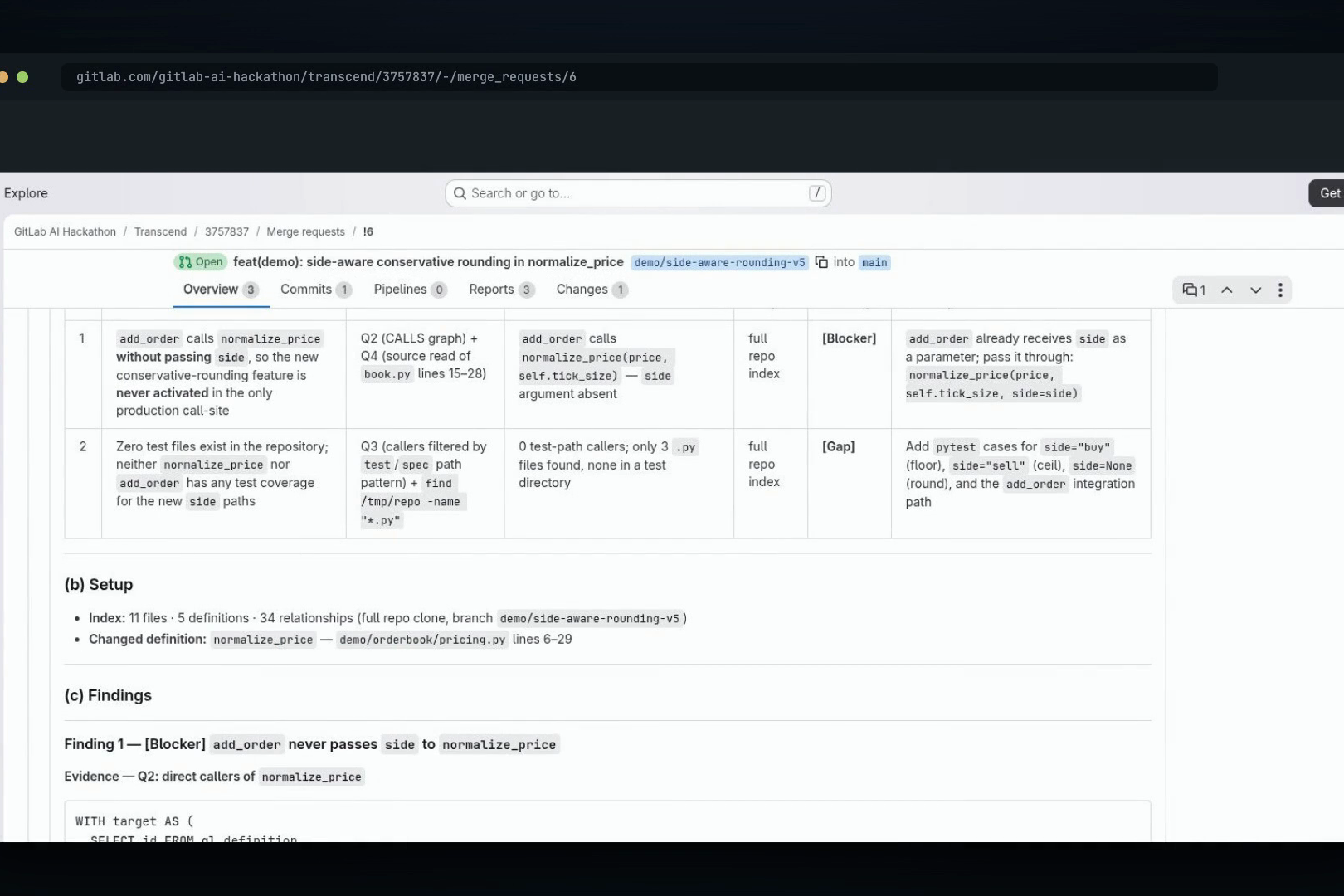
- Posts one review note: an Evidence Ledger on top (Claim | Evidence | Result | Scope | Developer action, severity-tagged), full SQL + returned rows per finding, a "checked, clear" list, and a "Reproduce this review evidence" block. In our flagship run, the reviewer caught that the MR's headline feature was dead on arrival: the only in-repo caller never passed the new parameter. The CALLS query found the caller, the source read roved the missing argument, and the review shipped the one-line fix. A typical AI review would have said "consider adding tests."
How we built it
Three artifacts, all published to the AI Catalog: an ambient flow (mention-triggered MR reviewer), a chat agent (interactive deep dives), and the reusable orbit-evidence skill — six verified graph-query recipes against Orbit's DuckDB schema (gl_definition / gl_edge / gl_imported_symbol`). The whole build ran through GitLab's GraphQL API, and the flow bootstraps the official Orbit CLI binary inside the Duo Agent Platform sandbox at runtime.
Challenges we ran into
The agent sandbox is a hostile environment: we hit step-limit loops, dropped sessions, and a read-only filesystem that broke Orbit's DuckDB writes. That last failure became our favorite exhibit: the flow disclosed the exact failing command and error, downgraded its own evidence scope to "source-read only", bounded every claim accordingly — and still caught the planted bug via source reads. Honest failure handling stopped being a design principle and became a live demo.
Accomplishments that we're proud of
- The re-run promise is tested, not aspirational: we executed the review's own reproduction block on a separate machine — same query, same single row back. The trust model shifts from "believe the AI" to "audit the AI when it matters", the same way CI logs changed build trust.
- Battle-tested against real maintainers: we used the same evidence discipline while contributing to GitLab Orbit itself during this hackathon — 9 MRs submitted, 2 already merged, including a maintainer-requested rework.
What we learned
Orbit isn't just a context source for agents — it's a claim provenance layer. A bounded claim with an explicit scope beats a confident claim with no evidence, every time. Even when the graph is incomplete, what you trust is the evidence boundary: a full-repo index supports repo-level claims, a diff-only fallback only supports diff-scoped claims — and the review says which one it has.
What's next for Evidence-First Reviewer
Inline diff comments with per-line evidence, multi-project graph scoping, and a CI mode that turns the Evidence Ledger into a merge gate.

Log in or sign up for Devpost to join the conversation.