-
-
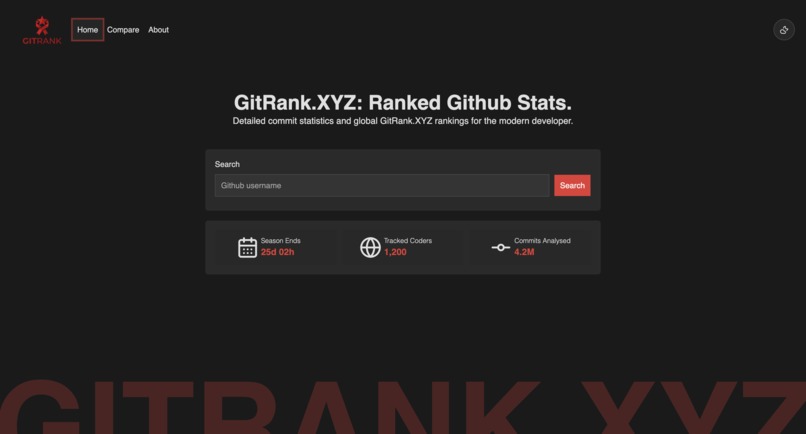
Dashboard
-
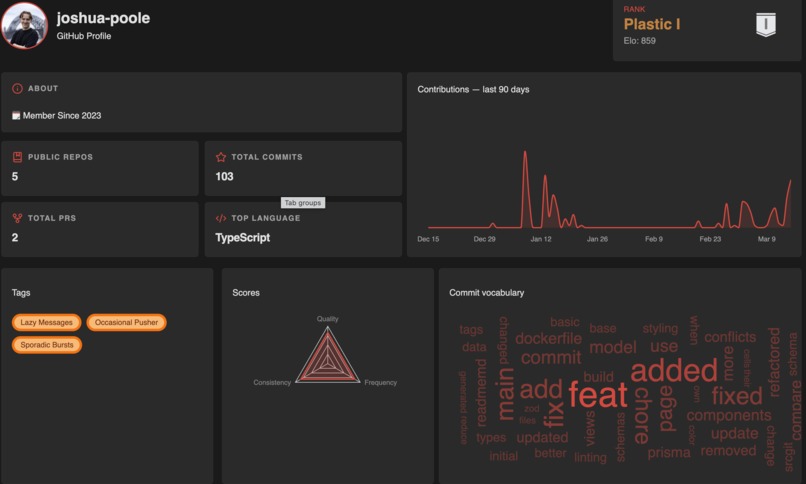
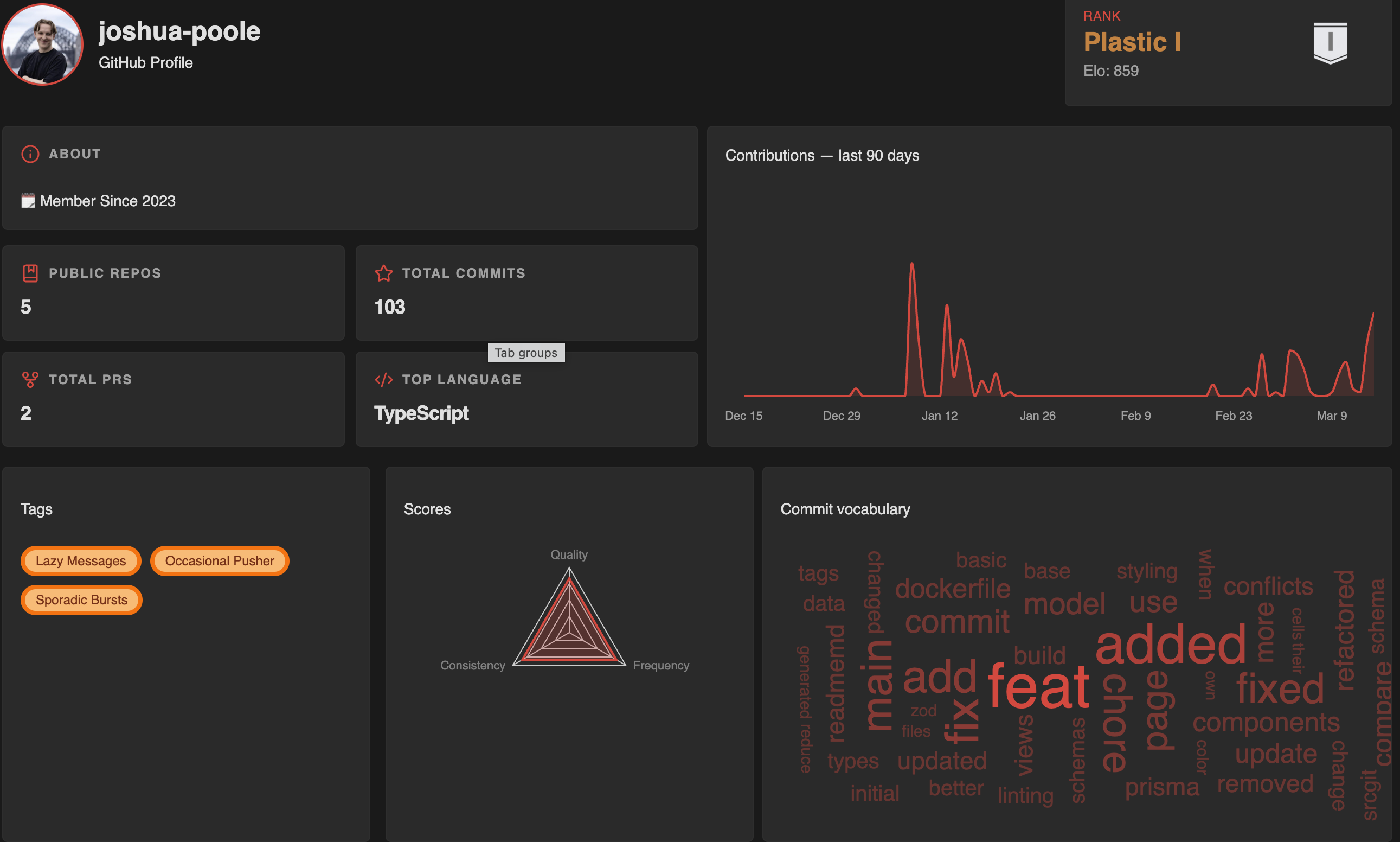
Profile page
Inspiration
In the modern age of AI, it's hard to know what's real and what's noise. Employers only have an average of 6 seconds per applicant to assess their skills, so it's important to use that time as efficiently as possible. We have created something that clearly outlines someone's GitHub history in one place.
We also like the idea of gamifying coding. It can be hard to stay motivated, and gamifying something can make it more fun and enjoyable for users of our platform. It can create friendships and communities by creating friendly competition and banter.
What it does
GitRank is an Elo-style ranking system for GitHub users. We use an ML model to analyse the sentiment and quality of commit messages, scoring each commit and feeding the score into a live ranking of every developer. This is similar to games like chess or League of Legends, which gives a score that reflects how well you're doing. Users are placed into competitive tiers from Plastic through Bronze, Silver, Gold, Platinum, and Diamond all the way up to the legendary Linus rank, each with three subdivisions.
The platform features a per-user dashboard showing stats, contribution graphs, and rank badges. A global seasonal leaderboard ranks all tracked developers, and a head-to-head compare page lets users pit their profiles against each other.
How we built it
We created the scaffold of the project using TanStack Start, a full stack React framework, so we could iterate quickly. We deployed using Neon PostgreSQL and Vercel. The frontend uses Shadcn components, Recharts for data visualisation, and tRPC for type-safe API calls between the client and server. Prisma ORM manages our database schema which tracks users, seasonal leaderboards, badges, and challenges.
ML
We utilised a logistic regression model built on top of sentence-transformers (all-MiniLM-L6-v2) to classify commit message quality. The pipeline encodes commit messages into 384-dimensional embeddings, uses FAISS for nearest-neighbor retrieval against a labelled dataset of positive and negative commit message signals, and then trains a logistic regression classifier via scikit-learn. The model outputs a probability score between 0 and 1 representing how "good" a commit message is. We trained on a public GitHub commit messages dataset with manually curated signal labels and evaluated using Macro F1. The model is served via a FastAPI microservice that loads on startup and scores commits on demand.
Determining Elo
We score commits on five factors using a weighted average: ML-analysed message quality (30%), lines of code changed (35%), consistency of commit pacing (10%), time of day (15%), and day of week (10%). Commits during regular working hours and on weekdays score higher, reflecting sustainable development patterns. A time decay of 0.99 per day ensures recent activity matters most, with only the last 90 days considered. The raw score feeds into an MMR system where daily performance is compared against an expected value based on current rating, and the delta is applied up to a maximum of 100 MMR per day. Inactive days incur a 15 MMR penalty. Higher scores reflect healthy development patterns, clear communication, regular hours, and sustainable pacing. Lower scores highlight risk of burnout or inactivity.
Challenges we ran into
Getting the Prisma ORM working with Neon's serverless PostgreSQL adapter on Vercel was a recurring challenge. The production database schema kept falling out of sync, leading to cryptic "column not available" errors that were hard to trace. We also had to balance the ML model's accuracy against inference speed since every commit needs to be scored, and tuning the Elo algorithm's weights and decay rates required a lot of iteration to produce rankings that felt fair and meaningful rather than just rewarding volume.
Furthermore, the design of our backend was challenging since we had to balance scalability, latency, and size. Our sentence-transformer model and its dependencies come in at around 2GB, which is well beyond Vercel's serverless function size limits. This forced us to run the ML scoring service separately, which introduces additional hosting costs and latency between services. Scaling that externally hosted model to handle concurrent requests without blowing through a budget is something we had to think carefully about.
GitHub's API rate limits were another constant constraint. The REST API caps unauthenticated requests at 60 per hour and authenticated requests at 5,000 per hour, while the GraphQL API has its own point-based rate limiting system. Since we need to fetch commit history across multiple repositories for every user we rank, a single user lookup can consume dozens of API calls. At scale this becomes a bottleneck quickly, and we had to implement caching and batch our requests carefully to avoid hitting limits during development and demos.
Accomplishments that we're proud of
We built a full end-to-end pipeline from raw GitHub data to a live competitive ranking in a single hackathon. The ML sentiment model works well at distinguishing meaningful commit messages from low-effort ones, and the Elo system produces rankings that genuinely reflect development quality over quantity. We're also proud of the dashboard and contribution visualisations that make the data feel tangible and the gamification elements that make it fun to check your rank.
What we learned
We learned how to integrate a Python ML microservice with a TypeScript full-stack app, how sentence-transformer embeddings can be leveraged for classification tasks beyond just similarity search, and how much tuning goes into making a ranking system feel fair. We also gained experience deploying serverless PostgreSQL with Prisma on Vercel and working with GitHub's GraphQL API for contribution data at scale.
What's next for GitRank: GitHub Ranked
We want to implement the badge and challenge system that's already modelled in our database, giving users goals to work towards beyond just climbing the leaderboard. We plan to flesh out the compare page into a full head-to-head experience, add seasonal resets with historical tracking, and build out the rank page for detailed breakdowns of how each score component contributes to a user's rating. On the ML side, we want to experiment with more sophisticated models and incorporate additional signals like PR review quality and issue triage patterns.
Built With
- faiss-cpu
- machine-learning
- neon
- numpy
- postgresql
- prisma
- python
- scikit-learn
- scipy
- sentence-transformers
- tanstack
- trpc
- typescript
- vercel




Log in or sign up for Devpost to join the conversation.