-
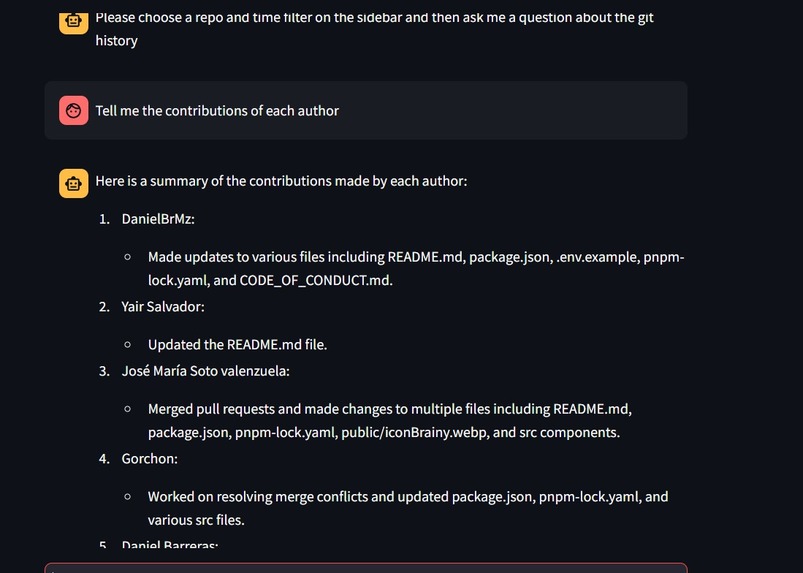
ChatBot making Responses about each author contribution.
-
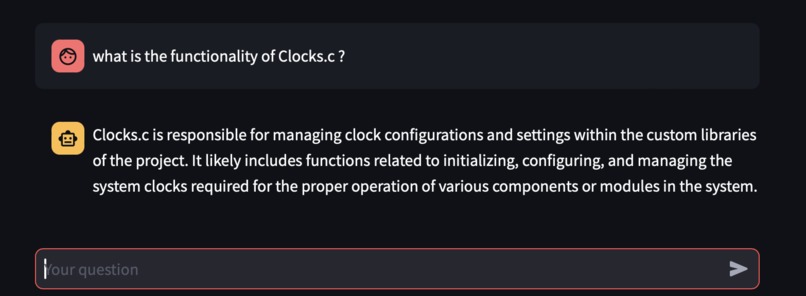
Knowing what a certain file is for
-
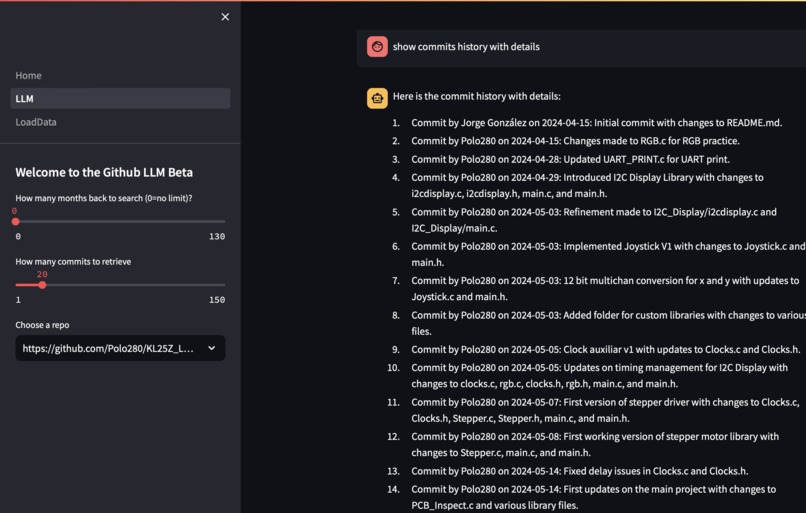
Commit history digested correctly.


Inspiration
Every Software Developer team uses Github as its primary way to share code and work together. The problem is that when thins get big, commits get very difficult to get tracked, and also very difficult for each individual to know what is everyone doing inside the repository. That's why we built a Chabot able to digest all the repository data efficiently and give insights with any questions you make.
What it does
It gives insights about the commits history of the repository, knows what each code/file is about in the repo, and also is able to differentiate between what each collaborator has work on. The most interesting feature is that we make it possible to digest all this data history into time-aware data so we can choose between time frames for searching specific data.
How we built it
We used various Pipelines & technology, primary using LLama Index & TimeScaleVectorStores for making a connecting a PostgreSQL Database and then turning it into a VectorStore DataBase which powers the use of Hypertables for time-aware RAG. We used ChatGpt for powering the NLP tasks, and various pipelines for efficiently preprocessing the raw data.
Challenges we ran into
Making the RAG time-aware, connecting everything together.
Accomplishments that we're proud of
Finishing a working beta in less than 24 hours.
What we learned
The use of various libraries like llama-index and how to work with RAG.
What's next for Github ChatBot LLM
Upgrades and better responses.
Built With
- llama-index
- python
- rag
- timescalevector


Log in or sign up for Devpost to join the conversation.