


Inspiration
Most of us have seen the recent news about open source maintainers getting bombarded with AI-generated MRs, with many of them overwhelmed by low-quality, automated, or irrelevant submissions, which are leading to high burnout rates.
What it does
Gitdefender aims to be the system to help maintainers cut through the noise, from triaging MRs to confidently merging them. You point the agent at an MR and it tells you if it's worth your time, then guides you through reviewing and merging it.
But the problem is more subtle than just filtering bad MRs. The problem is that maintainers used to be able to tell if an MR is worth their time just by looking at it, by instinct. But with the proliferation of AI written code, glancing through the code doesn't really tell you what it does. AI generates code that looks right, but often doesn't work as intended.
Having another AI agent review that nice looking code is a catch-22 because the same kinds of weights generated the code in the first place. What a human would do instead is rely on heuristics. Just like how we check how many subscribers a YouTuber has before trusting them, we can look at features of the user, their MR, and their interactions with the repo to understand if they're legitimate.
These heuristics include things like cross-repo velocity (how quickly someone contributes across repos), test-to-code ratio, blast radius, commit patterns, and more. I extract 58 features across 6 categories: code quality, AI fingerprints, description and commit analysis, architectural fit, MR metadata, and user reputation.
| Category | Features | Examples |
|---|---|---|
| Code Quality | 13 | Test-to-code ratio, hardcoded secrets, empty catch blocks, unused imports |
| AI Fingerprints | 9 | Over-engineering score, happy-path-only code, comment what-vs-why ratio |
| Description & Commits | 7 | AI-tell phrases, description-to-diff alignment, commit repetitiveness |
| Architectural Fit | 9 | Convention deviation, blast radius, hallucinated API calls |
| MR Metadata | 7 | Lines added/removed, files changed, commit count, references issue |
| User Reputation | 13 | Account age, prior merged MRs, first contribution, convention familiarity |
But no fixed threshold can tell you when something is slop, and that threshold changes over time as AI models get better. So instead of hardcoding rules, I train an Adaptive Random Forest model (using River) that learns incrementally from every merge and close decision a maintainer makes. It updates per event, no batch retraining needed. The model was pre-trained on 896 real GitLab MRs and adapts over time to the evolving definition of what "looks good but isn't" actually means.

But how do we even extract so much data in the first place? Some of the data are deterministic, we can query it from Gitlab's GraphQL and some others are semantic, we would need an agent to look through the code to understand it's features.
How I built it
This is where the GitLab Duo Agent Platform comes in. I built two components that work together:

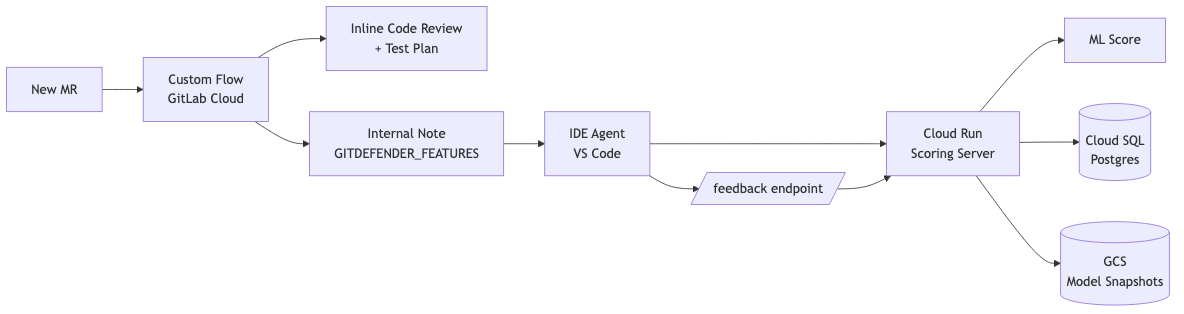
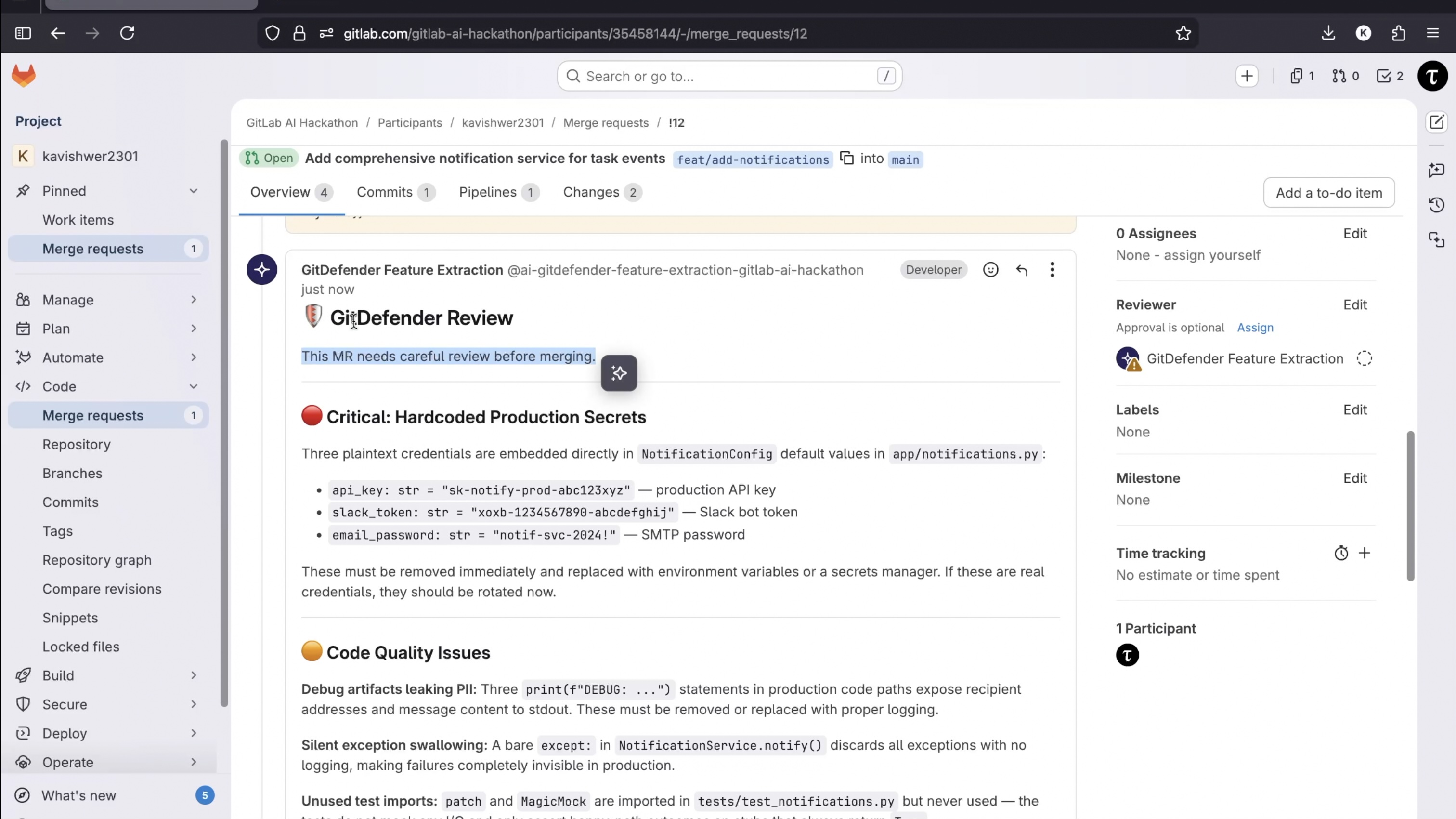
A custom flow runs in GitLab's cloud when triggered on an MR. It chains 5 specialized agents in sequence. The first 4 agents each read the diff, explore the codebase using GitLab tools (read files, search code, list directories), and extract their set of semantic features. The final agent aggregates everything, fetches the remaining repo/user data via GitLab GraphQL (star count, account age, prior merge history, contribution patterns), posts a consolidated code review on the MR with a collapsible test plan, and stores the full feature vector as an internal note for the next step. This means the model gets the same kind of data at inference that it was trained on.

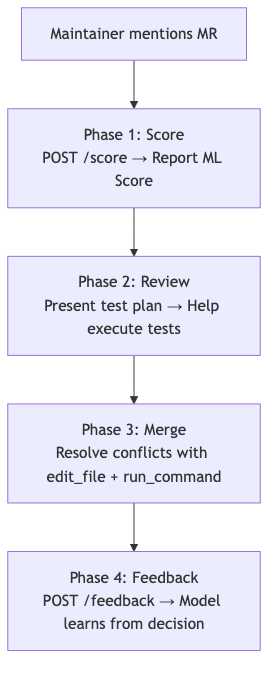
A custom IDE agent runs in VS Code and handles the rest of the lifecycle. When a maintainer asks about an MR, the agent picks up the extracted features, sends them to my Cloud Run scoring server, and reports the ML score. From there it guides the maintainer through reviewing the code, executing the test plan, resolving merge conflicts, and finally sending feedback to the model after the MR is merged or closed. The maintainer just keeps saying "yes" to move to the next step.

The scoring server is a FastAPI app on Google Cloud Run backed by Cloud SQL (Postgres). It hosts the River model, scores feature vectors, and stores every outcome so the model keeps learning. The model is persisted to GCS so it survives redeployments.
To solve the cold start problem, I pre-trained the model on 896 real MRs from 20 public GitLab repositories including gitlab-org/gitlab, inkscape, fdroid, and others. For each repo I fetched 25 merged and 25 closed MRs via GitLab's GraphQL API, extracted the API-derivable features (repo metadata, user history, MR stats), and trained the model one sample at a time using progressive validation, the standard evaluation method for online learning where you score each sample before training on it. The model reached a stable accuracy before being serialized and uploaded to GCS as the production starting point. From there, every maintainer decision (merge or close) continues to update the model incrementally, so it never needs batch retraining.
Challenges I ran into
The biggest challenge was the network sandbox. All agents and flows running in GitLab's cloud cannot make outbound HTTP requests, which meant my original plan of having the flow call the scoring server directly was impossible. I had to rethink the architecture entirely and split it into two parts: the flow extracts features and stores them as an internal note, and the IDE agent picks them up and calls the server from the user's local machine.
I also had to figure out how to pass 58 features between the cloud flow and the IDE agent with no shared state. The solution was simple but effective: the final flow agent posts the feature JSON as an internal MR note with a known prefix, and the IDE agent searches for that prefix when it runs.
Accomplishments I'm proud of
The full lifecycle works end to end. A maintainer can trigger the flow on any MR, get inline code reviews and a test plan, then open their IDE and get an ML score, review assistance, conflict resolution, and feedback to the model, all by just saying "yes" at each step.
The online learning model is genuinely useful. It was pre-trained on 896 real MRs and updates with every maintainer decision. It doesn't just flag bad code, it learns what wastes time for each specific project and adapts as AI-generated patterns evolve.
What I learned
That the hardest part of building on a new platform isn't the code, it's understanding the constraints. I spent hours discovering what was and wasn't possible in the Duo Agent Platform before landing on the right architecture. The constraints actually pushed me toward a better design: splitting cloud and IDE responsibilities made each component simpler and more focused.
I also learned that the real problem isn't detecting AI code or filtering inexperienced contributors. It's identifying MRs that look good but aren't. That distinction shaped every design decision.
What's next for Gitdefender
- Webhook-based feedback so the model updates automatically on merge/close without the maintainer needing to be in the IDE.
- More features from the GitLab API like CI pass rates, reviewer history, and label patterns.
- Expanding the training data beyond 896 MRs by partnering with open source projects willing to share their merge outcomes.
Built With
- adaptive-random-forest
- claude-(via-ai-gateway)
- cloud-sql-(postgres)
- docker
- fastapi
- gitlab-custom-flows
- gitlab-custom-ide-agents
- gitlab-duo-agent-platform
- gitlab-graphql-api
- google-cloud
- google-cloud-run
- python
- river
- terraform







Log in or sign up for Devpost to join the conversation.