Inspiration
For open-source developers who waste hours scrolling through endless issue backlogs only to find the best tasks already taken, GitClaim is an autonomous background agent that secures the right issues for you completely on autopilot. The system continuously monitors your repository watchlists, passes new issues through an LLM to evaluate if they match your technical skillset, and instantly posts a tailored, context-aware contribution proposal to claim the task before anyone else. While manual issue hunting is slow and competitive, GitClaim runs 24/7 in the background, ensuring you never miss a perfect contribution opportunity.
What it does
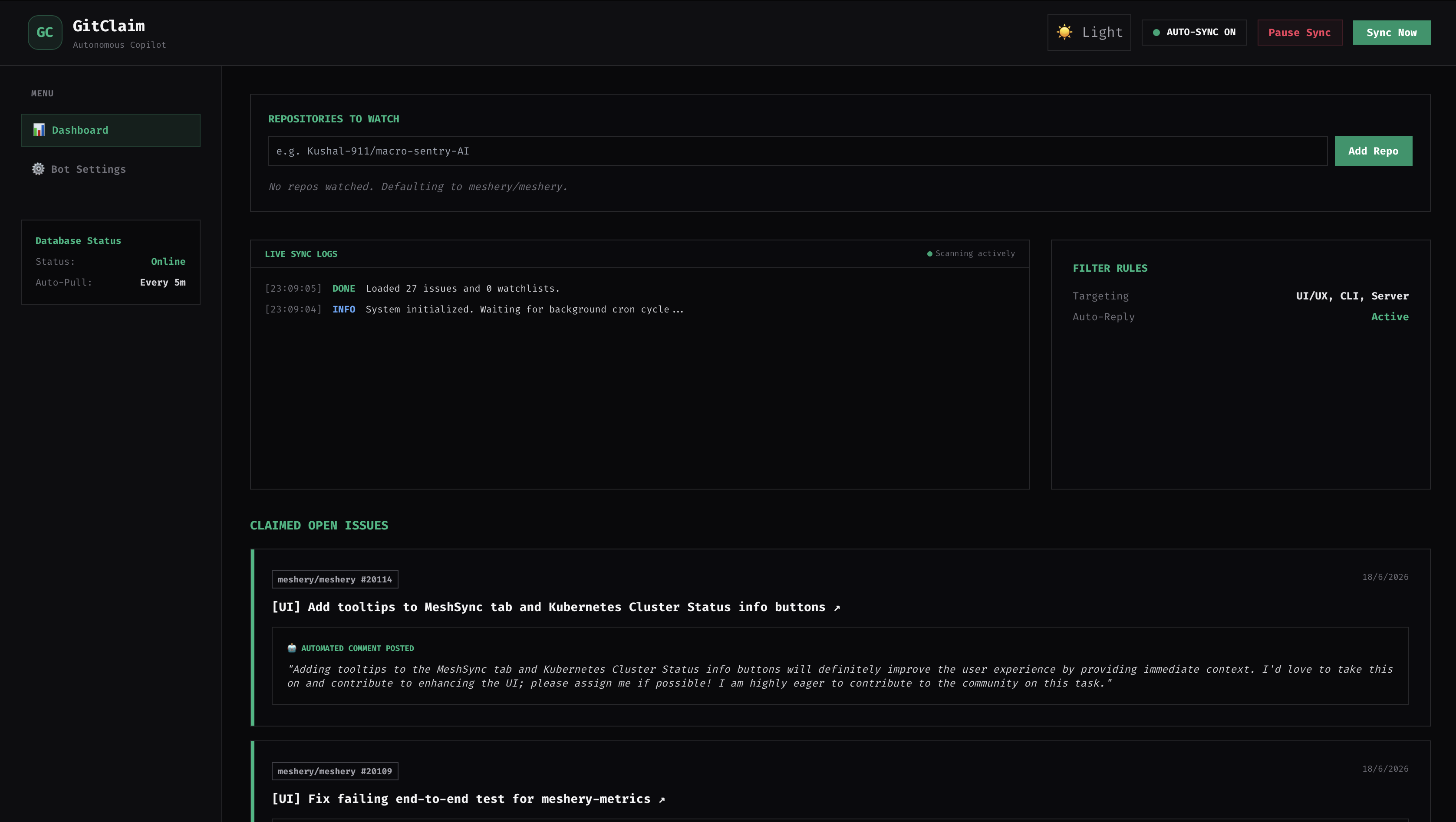
GitClaim is an autonomous AI agent designed to eliminate the manual overhead of finding and claiming open-source issues. It sits in the background monitoring a specified watchlist of repositories for newly opened issues. When an issue appears, GitClaim extracts the context and passes it to an LLM to evaluate if the technical requirements align with the developer's skillset. If the issue is determined to be a high-confidence match, the system generates a tailored, context-aware contribution proposal and leverages the GitHub API to post it immediately as a comment, securing the task before it gets claimed by someone else. The entire operation is managed through a live mission control dashboard that categorizes issues into distinct pipelines like Pending Review, Ignored Domain, or Automatically Claimed.
How we built it
The core architecture is split into a Next.js App Router frontend and a background execution layer, built entirely with TypeScript.
- The Web Interface: A highly responsive dashboard styled with Tailwind CSS that provides full visibility into live system actions, synchronization states, and log tracking.
- The Data Layer: We used AWS DynamoDB as our primary database for fast, key-value storage to handle real-time state synchronization of tracked issues without heavy overhead.
- The Integration Layer: Communication with GitHub is powered by Octokit. The backend exposes structured API endpoints, notably a GET endpoint to pull current states from DynamoDB and a POST endpoint that executes the repository sweep, runs the AI evaluation engine, and triggers the automated GitHub commenting pipeline.
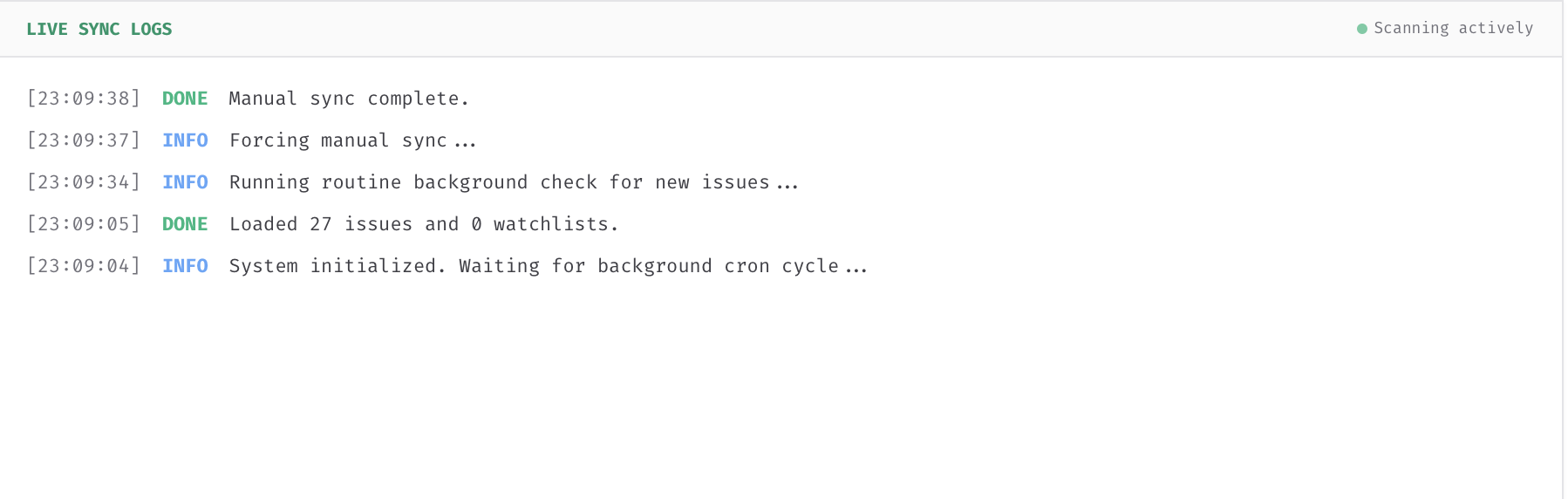
- The Automation Engine: Rather than relying on rigid, third-party cron infrastructure, the application deploys an active, client-side background polling routine that automatically executes state-mutating sweeps to keep the automation cycle looping seamlessly.
Challenges we ran into
One of our biggest early hurdles was infrastructure blockages during deployment. We originally intended to trigger the backend sweeps using standard Vercel background crons, but quickly discovered that high-frequency intervals are heavily restricted or gated on standard hobby tiers. To work around this limitation without breaking the autonomous requirement, we had to shift our architecture to a self-contained, active client-side loop that drives automated POST sweeps directly to our worker endpoints.
Another significant challenge was debugging the execution contexts between manual and auto-sync triggers. While manual testing worked flawlessly, the automated background worker initially ran passive read operations rather than active write mutations, resulting in silent claim drops. Tracing this required isolating our database transaction logic from the API execution flows to ensure proper token state across both automatic loops and manual dashboard overrides.
Accomplishments that we're proud of
We are incredibly proud of building a project that functions as a truly autonomous end-to-end prototype rather than just a static visual concept. Seeing the system independently scan a live repository, accurately determine an issue's technical stack via AI, and post a professional proposal directly to GitHub within seconds without any human intervention was a huge milestone. We also managed to maintain an extremely clean, zero-hydration-error layout with a seamless dark-mode dashboard setup that stays highly scannable under heavy data load.
What we learned
This project provided a massive learning experience in understanding execution context differences between client sessions and background server runtimes. We learned how to handle API rate limiting effectively, striking a delicate balance between aggressive 30-second polling frequencies and GitHub's secondary rate limits to prevent token throttling. Additionally, we gained a much deeper understanding of relational state management within serverless web applications, specifically how to structure conditional write operations to a database like DynamoDB so that network latencies don't lead to race conditions or duplicate issue claims.
What's next for GitClaim
The immediate next step for GitClaim is scaling the ingestion engine to handle multi-repository ecosystems simultaneously through optimized webhook listening rather than relying purely on polling. We also plan to integrate personalized contributor profiles, allowing developers to upload their specific resumes, past PR histories, or deep codebase context. This will enable the matching LLM to perform highly individualized filtering, ensuring the generated proposals match the developer's exact coding style and architectural expertise.
Built With
- amazon-web-services
- configuration)
- css
- dynamodb
- github
- nextjs
- octokit
- rest
- tailwind
- typescript

Log in or sign up for Devpost to join the conversation.