-
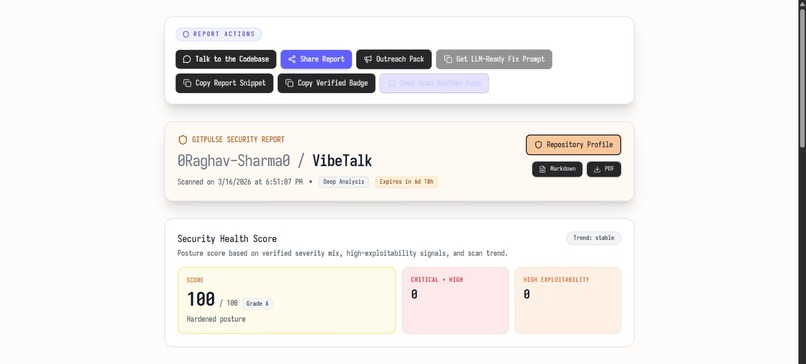
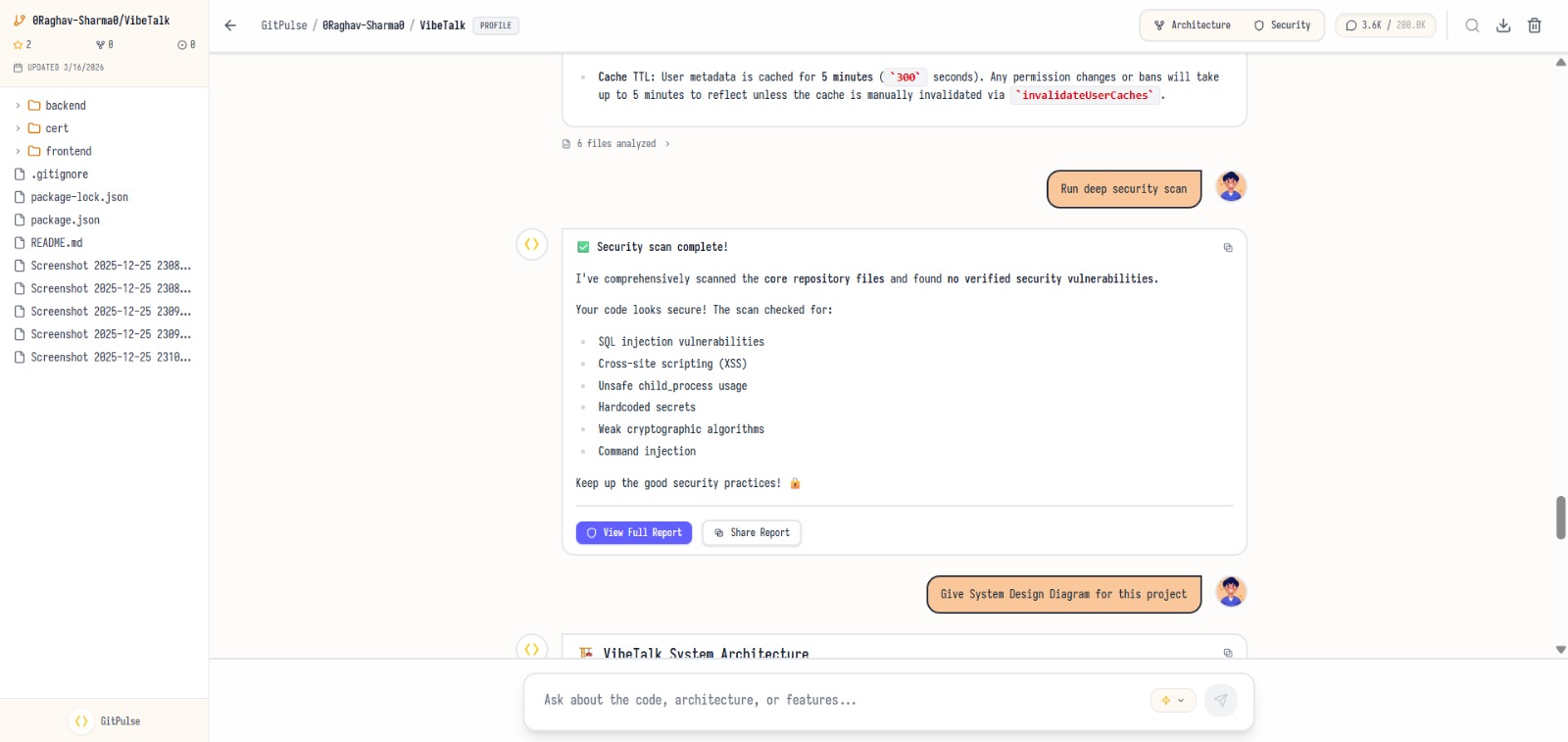
any security or vulnerability threats
-
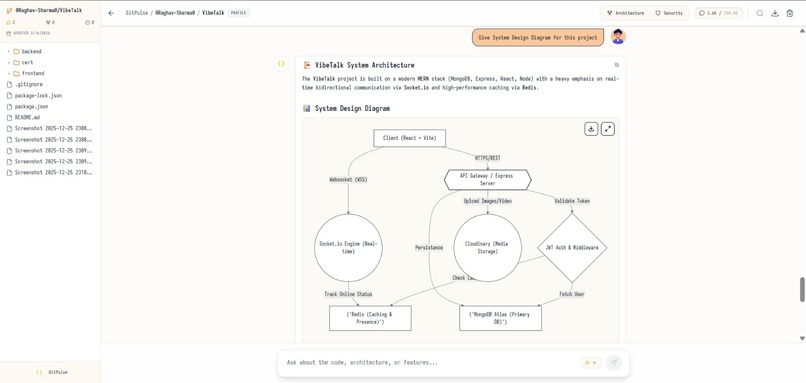
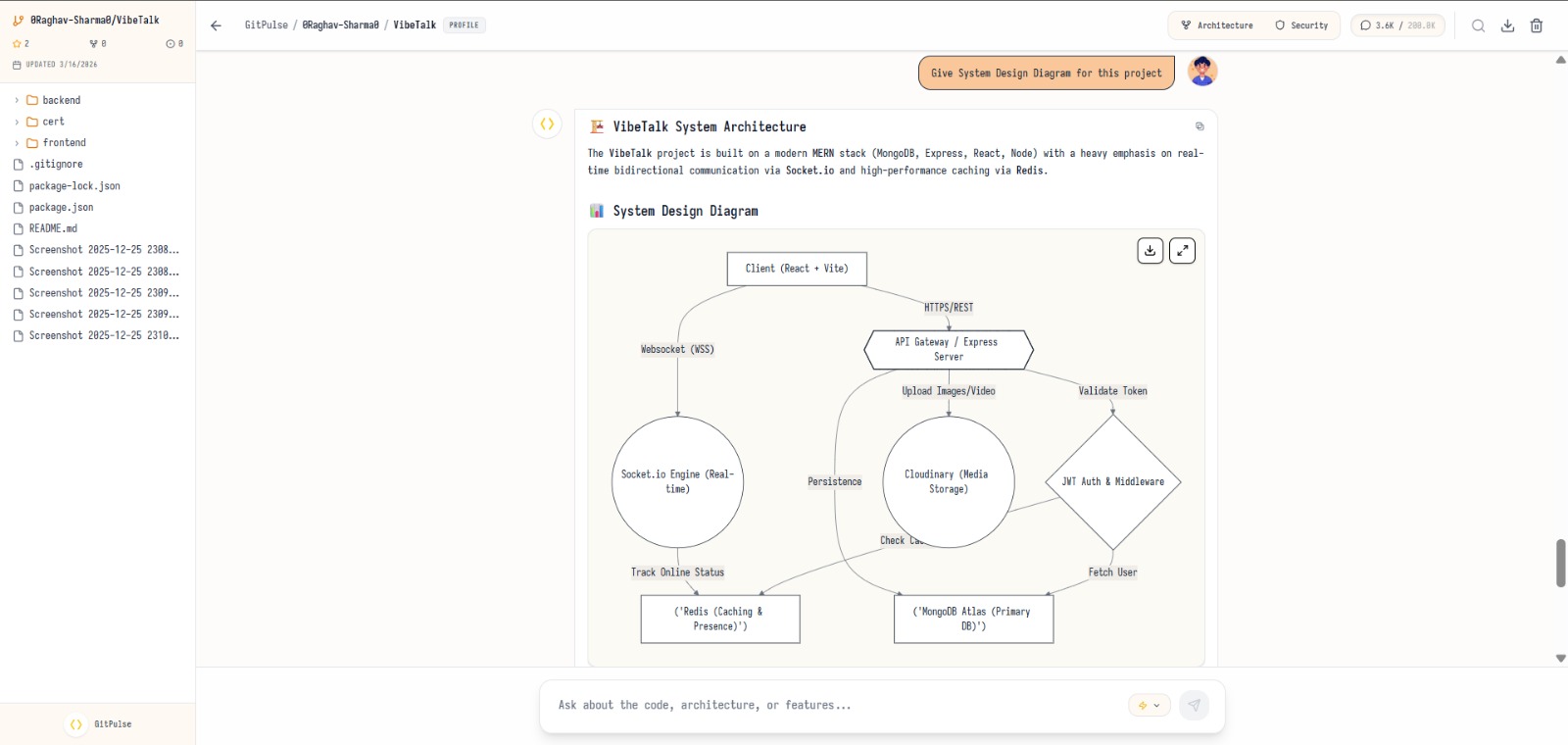
full diagramatical analysis
-
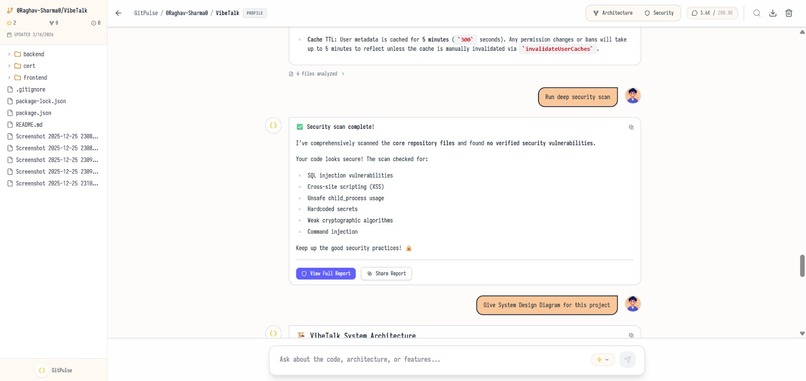
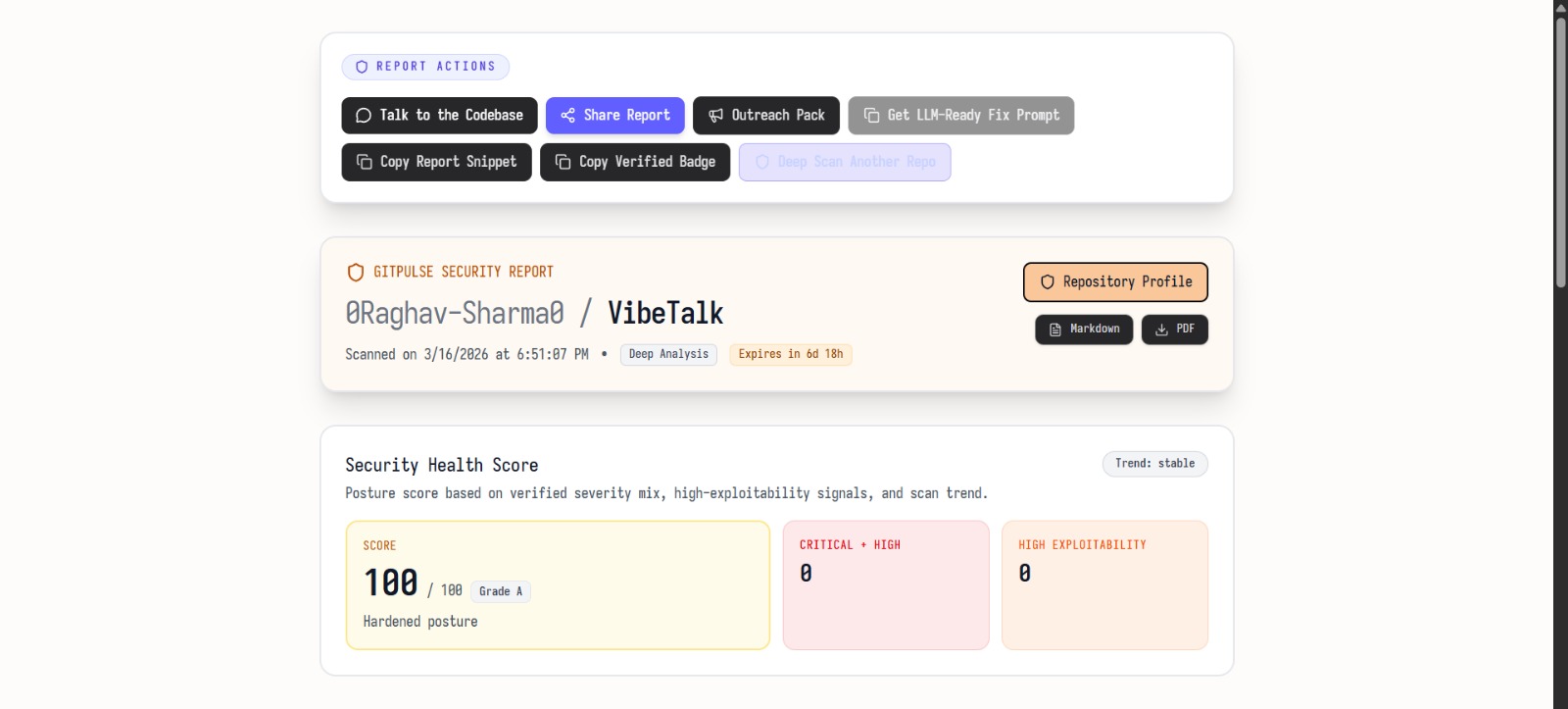
analysis of repository
-
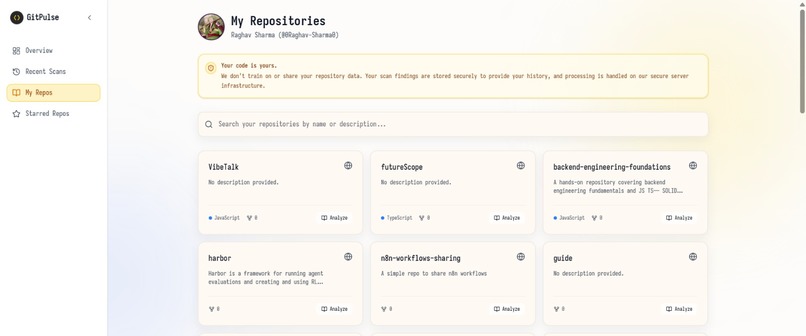
when signed up we can see all repositories
-
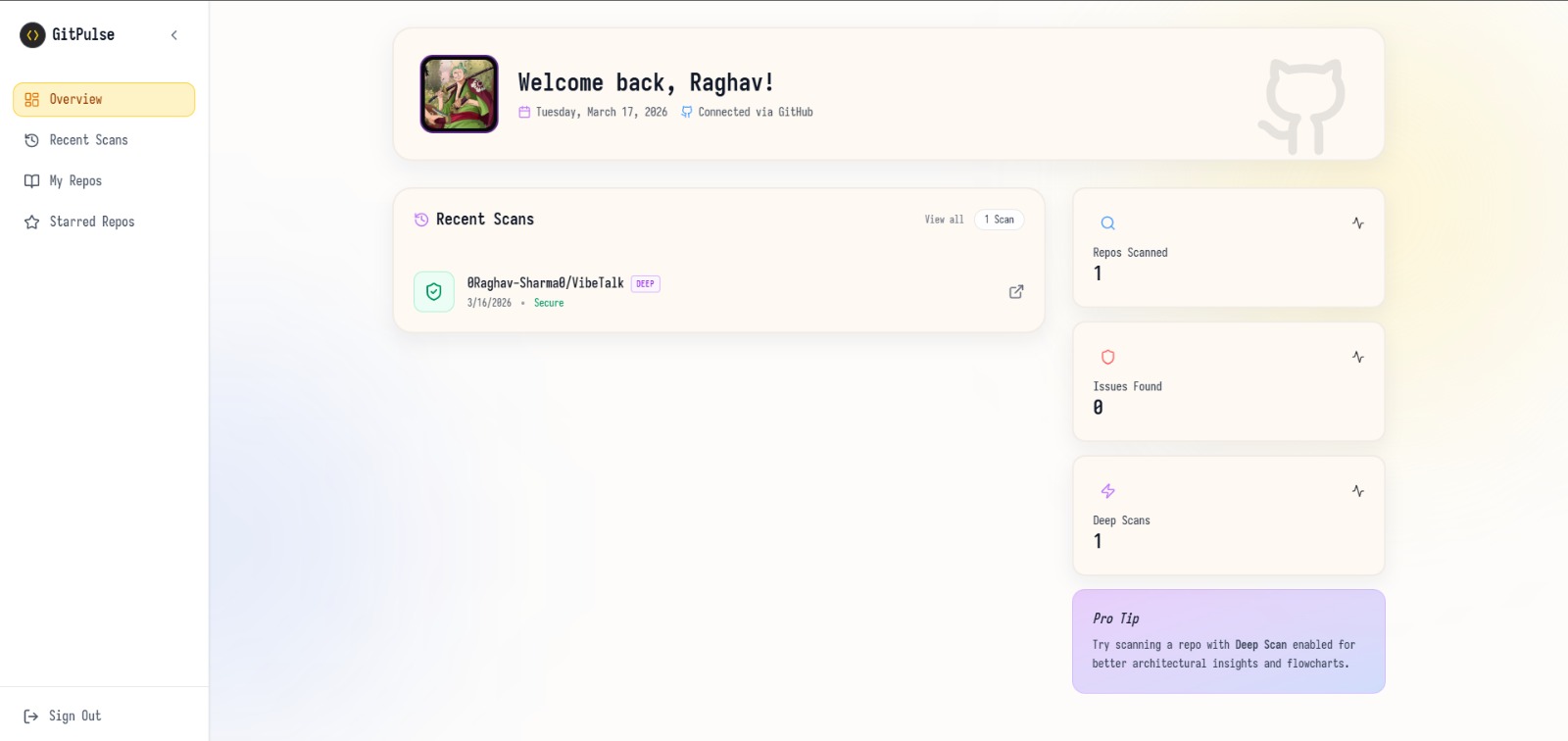
personal overview's and dashboard
Inspiration Onboarding to a new open-source repo—or even your own old code—often means hours of clicking through files, tracing imports, and guessing how things connect. We built gitAnalyze so anyone can understand a GitHub repository in seconds, without cloning it, by talking to the codebase the way a senior engineer would.
What it does gitAnalyze turns any public GitHub repository into an interactive AI workspace. Users can:
Chat with the repo — ask how features work, where logic lives, and how components connect Get architecture insights — diagrams and structural understanding from real source code Run security scans — find vulnerabilities, secrets, and risky patterns Explore developer profiles — contribution patterns and standout projects Paste a repo URL, ask a question, and get answers grounded in actual files—no local setup required.
How we built it Next.js + TypeScript for the app and API Google Gemini for file selection, streaming answers, and deep reasoning mode Agentic CAG (not classic RAG): an AI agent picks relevant files, loads full file context, then generates answers within a large token budget GitHub API for repo metadata, file trees, and file content Prisma + PostgreSQL for users, sessions, and app data Redis / Vercel KV to cache GitHub responses and repeat queries Static security rules + AI verification for scan accuracy Deployed on Vercel, with Docker Compose for local or self-hosted full-stack runs Challenges we ran into Huge repositories — fitting thousands of files into context; solved with hierarchical pruning and smart file selection Token limits and API costs — balancing full-file context with budget and rate limits Production auth — GitHub OAuth, database URLs, and environment config across Vercel and Docker Caching failures — keeping the app usable when Redis/KV is down Security false positives — tuning scans so findings are useful, not noisy Accomplishments that we're proud of A complete URL → understand repo flow with zero clone Agentic file selection that works better than blind chunking for real codebases Chat, architecture, and security in one product Shipped to production with auth, caching, and health checks Docker setup so the whole stack runs locally or on a VPS What we learned Vector RAG isn’t always best for code — whole files plus smart retrieval often beat disconnected chunks LLMs are strong at “which files matter” when given structure and clear rules AI products need as much work on caching, limits, and fallbacks as on prompts Vercel vs Docker taught us both “ship fast” and “own your infra” What's next for gitAnalyze Richer dependency graphs and cross-repo analysis Pull request intelligence — summarize and review PRs in context Multi-repo workflows for teams Hybrid retrieval for very large monorepos Deeper contributor and team insights
Built With
- auth.js
- docker
- docker-compose
- eslint
- github-api
- google-gemini
- neon
- next.js
- postgresql
- prisma
- react
- redis
- tailwind-css
- typescript
- upstash
- vercel
- vitest



Log in or sign up for Devpost to join the conversation.