About GitAIOps: An AI-Native Command Center for GitLab
The Inspiration: From Automation to Autonomy
In the world of DevOps, automation is king. We have incredible tools that run tests, deploy code, and scan for vulnerabilities—all triggered by git push. Yet, as developers, we still spend countless hours on the cognitive glue that holds this all together: triaging merge requests, diagnosing cryptic CI/CD failures, untangling deployment bottlenecks, and chasing down the right person for a code review. We've automated the tasks, but we're still manually handling the decisions.
This was the spark for GitAIOps. We asked a simple question: What if our DevOps platform was more than just a workflow engine? What if it could be an intelligent, autonomous copilot that understood the context of our work and took action? What if we could use the power of modern LLMs like Google's Gemini to move from automation to true autonomy?
Our vision was to create a system that doesn't just present data but synthesizes it into actionable intelligence. A platform that doesn't just fail a pipeline but tells you why and proposes a fix. A command center that gives engineering teams superpowers by handling the operational overhead, so they can focus on what they do best: building great software.
How It's Built: A Modern, Scalable AIOps Architecture
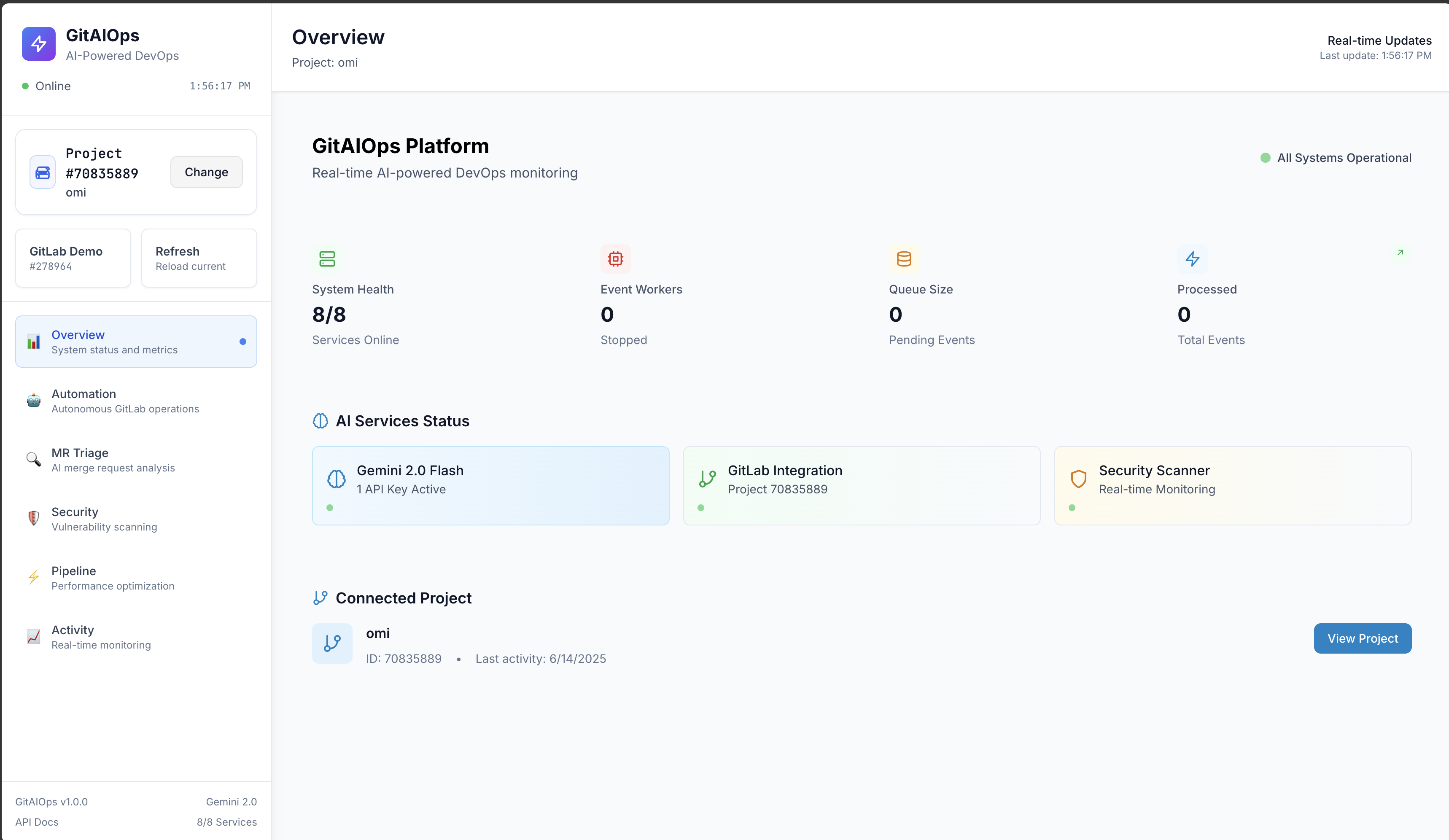
Building GitAIOps required a modern, event-driven architecture designed for real-time analysis and action.
The Backend Brain (Python & FastAPI): The core of the platform is a robust FastAPI server. We chose FastAPI for its high performance with
asyncioand its excellent Pydantic integration, which is critical for defining the structured data models our AI relies on. The entire backend is designed as a modular package, with clear separation of concerns for API endpoints, core services (like GitLab and Gemini clients), and feature logic.The AI Core (Google Gemini 1.5 Pro): This is where the magic happens. We deliberately moved away from brittle, hard-coded
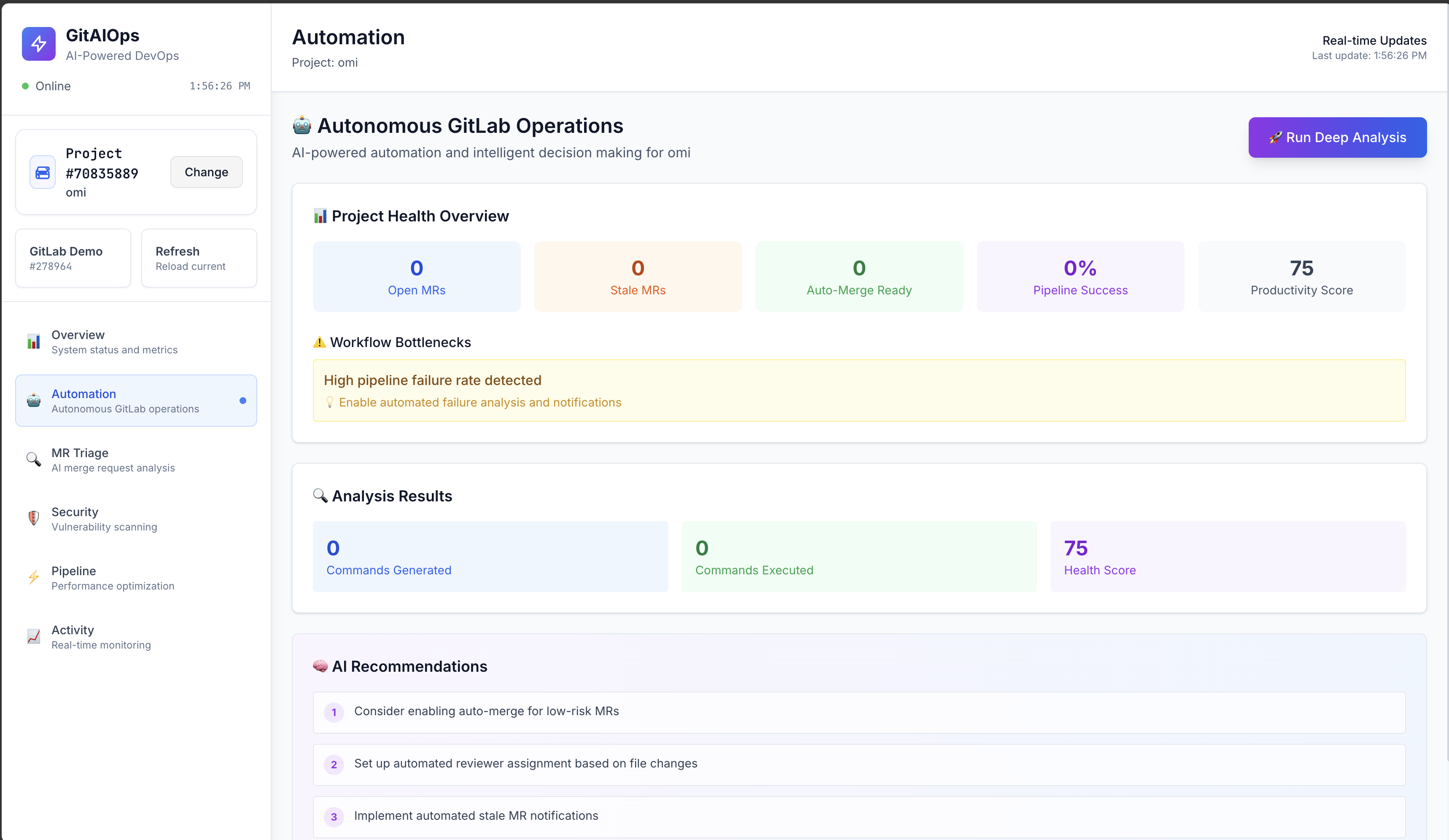
if/elselogic. Instead, ourAutomationEnginedynamically gathers a complete snapshot of a GitLab project—open MRs, pipeline statuses, code churn, and more—and feeds this context into a meticulously engineered prompt for Gemini. The model's task is to reason over this data and return a precise JSON array of executable commands. This makes the system incredibly flexible and intelligent, as it can chain actions and respond to novel situations without needing new code.Real-time Dashboard (React & Framer Motion): We believe a powerful backend deserves an elegant frontend. The dashboard is built with React and TypeScript, using TailwindCSS for styling and Framer Motion for smooth, intuitive animations. It provides a real-time, "mission control" view of all platform activities, from live metric updates to the stream of AI-driven commands being proposed and executed. The frontend is not just a vanity display; it's a crucial interface for transparency and human-in-the-loop oversight.
Seamless Setup & Deployment: To make the platform immediately usable, we created a unified
start.pyscript. It automates the entire setup process: creating a Python virtual environment, installing all dependencies, and building the React dashboard for production. This ensures a professional, one-command start for anyone wanting to run or contribute to the project.
Challenges We Overcame: Moving from Theory to Reality
Ensuring Reliable AI Output: Getting an LLM to consistently return valid, structured JSON is a classic challenge. We solved this through rigorous prompt engineering, providing a clear "command schema" in the prompt, and building a robust parsing layer on the backend that validates the LLM's output before execution. This ensures that even if the AI hallucinates, it won't break our system.
Handling Asynchronous Operations: A real-time DevOps platform deals with dozens of concurrent API calls and long-running analysis tasks. We built the entire platform on Python's
asyncioandaiohttpto manage this complexity, ensuring the UI remains responsive and the backend can scale to handle heavy workloads without blocking.Taming Hot-Reloading Environments: We initially faced a critical
Duplicated timeseries in CollectorRegistryerror when using Uvicorn's hot-reload feature. This was due to monitoring metrics being re-registered on every reload. We engineered a solution by creating a dedicated monitoring module with a separate Prometheus registry and updated our launcher to manage the environment correctly, ensuring both a smooth developer experience and production-ready metrics.
What We Learned
- Prompt Engineering is System Design: The quality and reliability of our autonomous engine are directly proportional to the quality of our prompt. Defining the available "tools" (automation actions) and constraints for the LLM within the prompt is just as important as writing backend code.
- The Power of LLMs is Reasoning, Not Just Generation: The true breakthrough with GitAIOps was shifting from asking the LLM to generate text to asking it to generate a plan. By instructing Gemini to produce a list of structured commands, we transformed it from a simple text utility into the core decision-making brain of our platform.
- A Professional UX Matters: Providing a clean, real-time dashboard was not an afterthought. It builds trust in the autonomous system by making its actions transparent and giving users a clear view of the value it provides, moment-to-moment.
GitAIOps is more than just a hackathon project; it's a blueprint for the future of intelligent DevOps. We're incredibly proud of what we've built and excited about its potential to redefine how software teams operate.
Built With
- fastapi
- gemini
- gitlab
- mcp
Log in or sign up for Devpost to join the conversation.