-
-
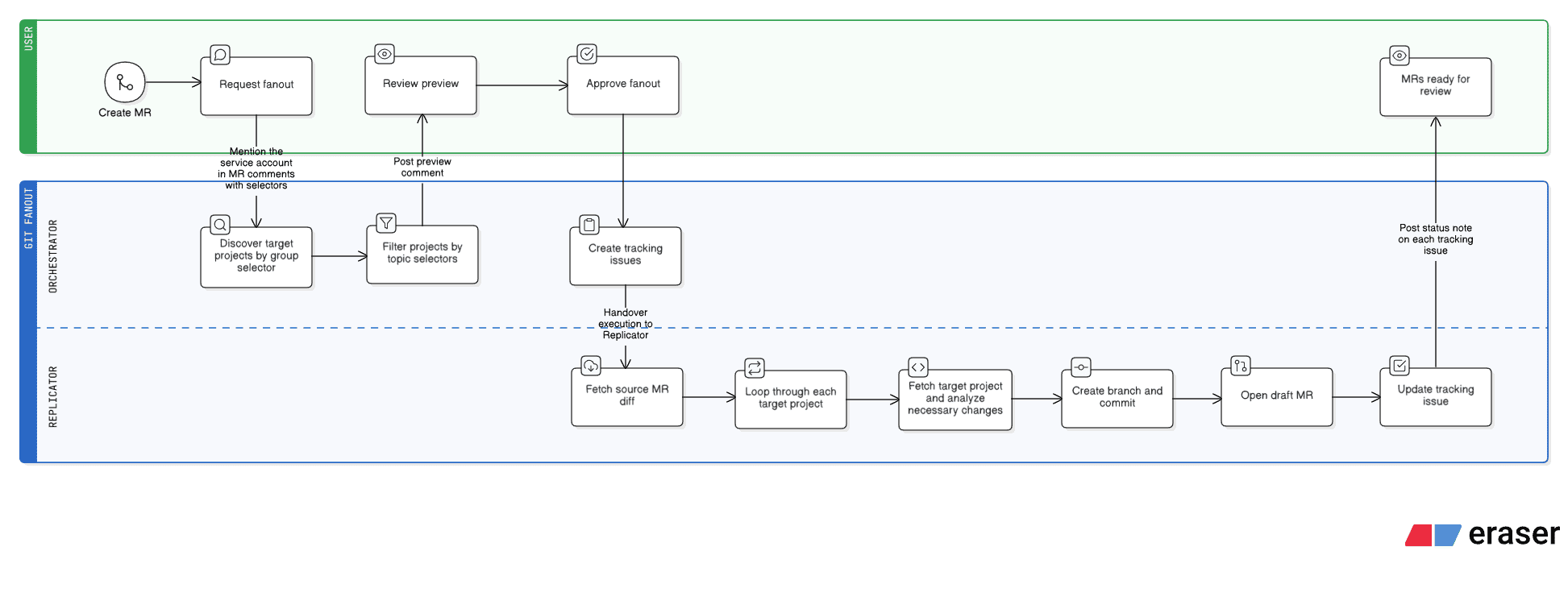
swimlane diagram
-
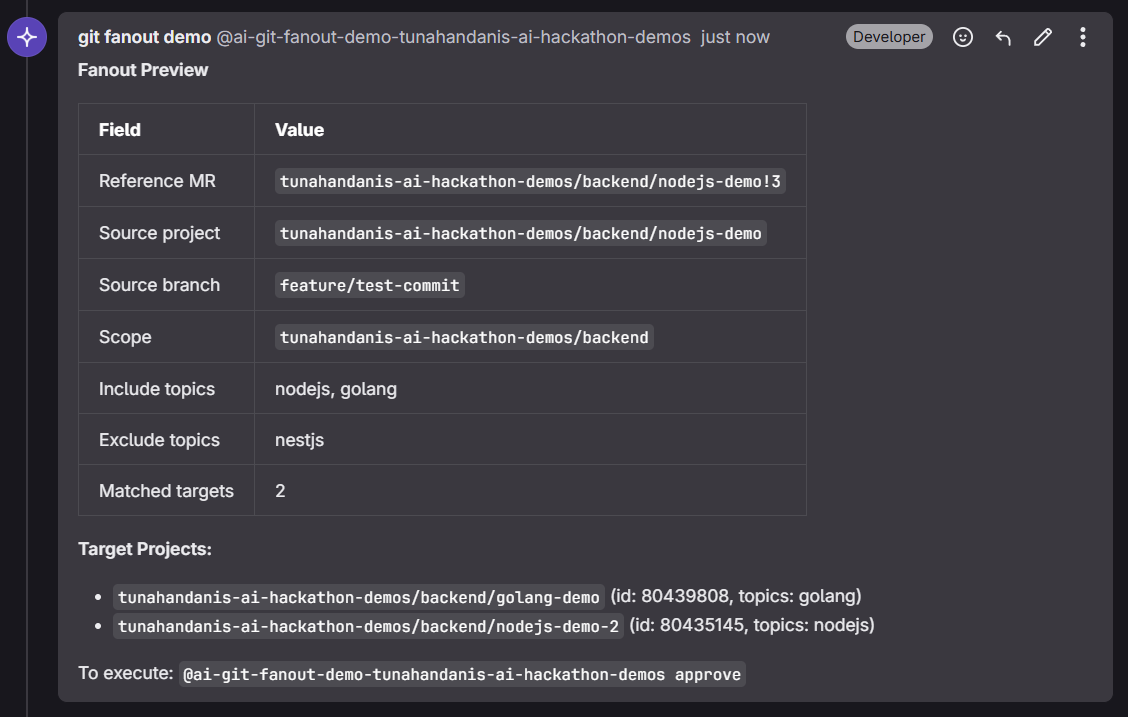
preview
-
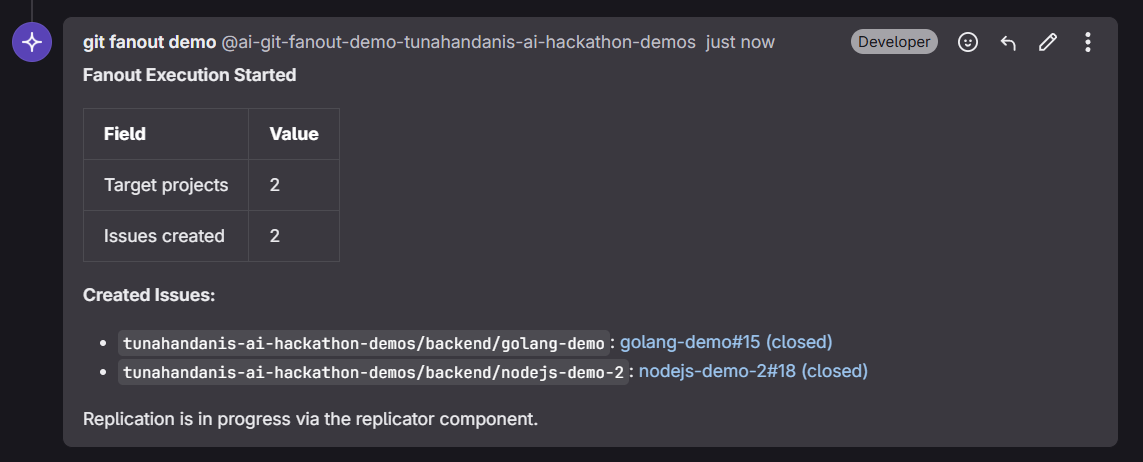
issues
-
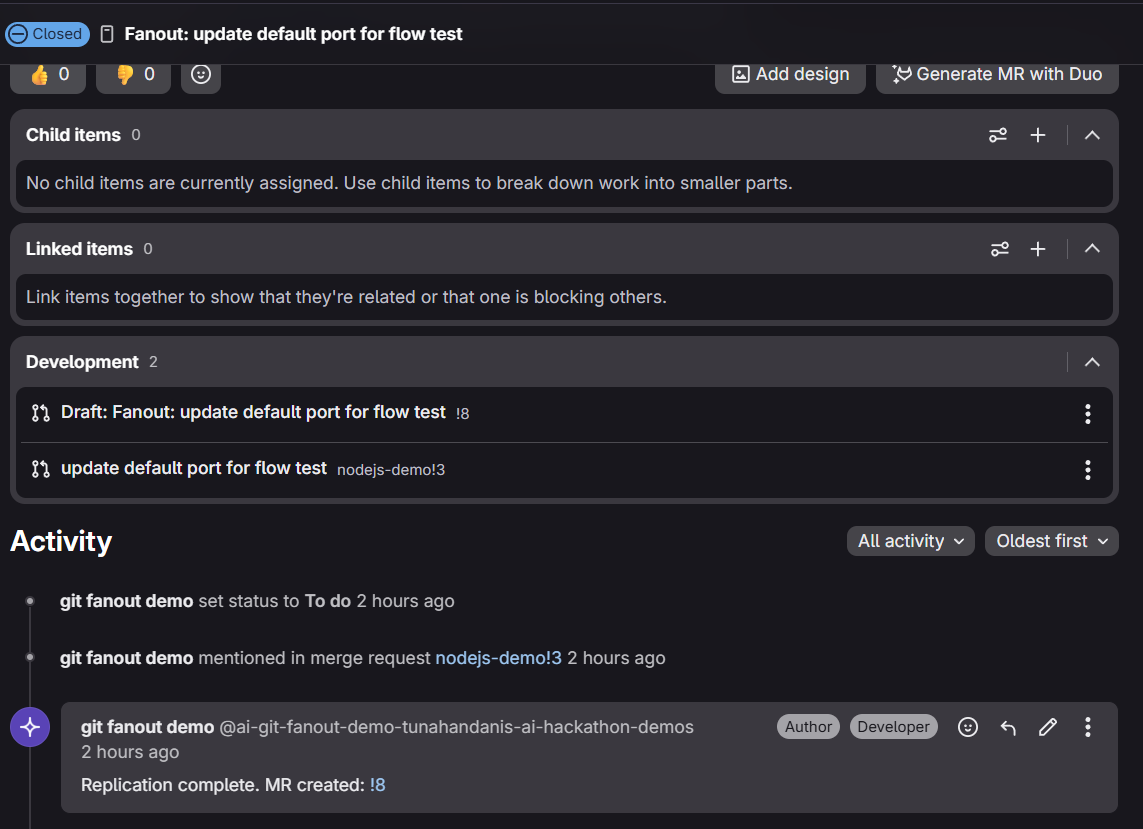
fanout complete
git fanout
💡 Inspiration
In any organization that has a multi-repo setup, a single change like updating a base Docker image, bumping a dependency or renaming a shared environment variable often needs to land in dozens, if not hundreds, of repositories. Doing this manually is tedious and error-prone.
Copy-pasting diffs across projects ignores language differences, file naming conventions, and the ripple effects a change has on documentation, Dockerfiles, CI configs, and more.
I wanted to build a tool that understands what a change means, not just where it was made, and propagates it intelligently across an entire project group — with human oversight at the right moment.
🚀 What It Does
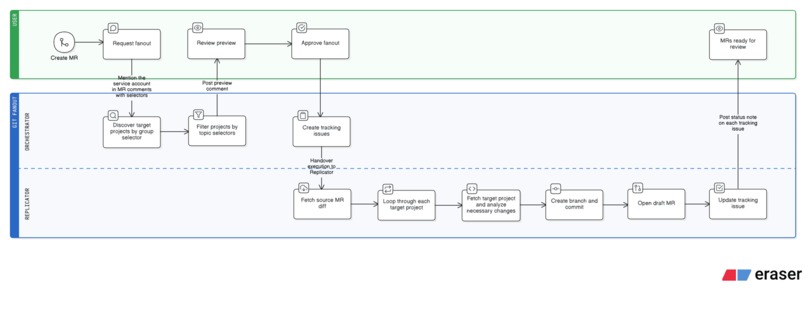
git fanout is a GitLab Duo flow that contextually replicates a merge request across multiple projects in a group.
It chains an Orchestrator (discovery and coordination) with a Replicator (change analysis and MR creation), connected by a structured data handoff. It operates in two phases:
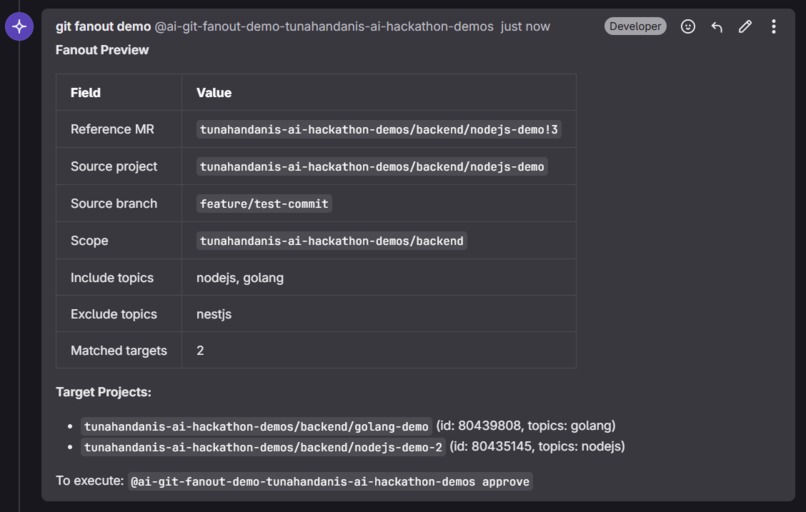
1. Preview — A user comments on a merge request with target scope (group, topic filters). The Orchestrator discovers matching projects and posts a preview summary for review.
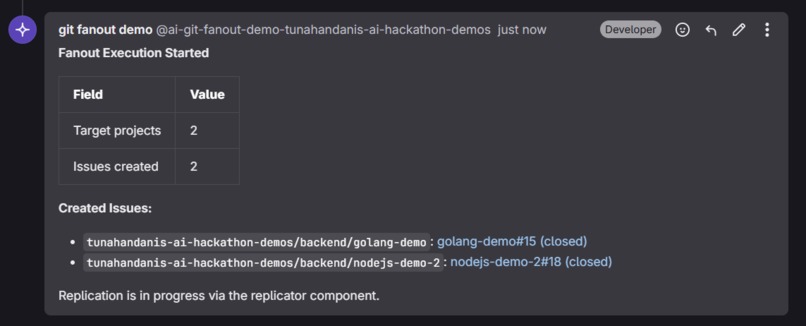
2. Approve & Replicate — The user approves, and the Orchestrator creates tracking issues in each target project. The Replicator then takes over: it fetches the source diff, reads every file in each target project, and performs a full analysis — applying direct matches, adapting changes for equivalent files, and scanning all remaining files for consistency updates that reference the same concept.
Changes can be replicated across projects regardless of programming language or framework. A default port change in a Node.js server.js can be adapted to a Go main.go and propagated to the corresponding Dockerfile and README in the latter, even if the former didn't need that change.

🛠️ How I Built It
Platform: GitLab Duo AI Agent Platform (flow YAML, v1 spec)
Architecture: The Orchestrator and Replicator are both
AgentComponents (AI-driven). ADeterministicStepComponentruns before them to inject source project metadata without LLM involvement — this feeds both agents with hallucination-free project context.- Orchestrator — Handles discovery, filtering, preview, approval, issue creation, and produces a structured handoff (
FANOUT_DATA) for the Replicator. - Replicator — Parses the handoff, fetches the diff once, then loops over each target: reads all files, classifies changes into tiers (exact match, high-confidence adaptation, skip), performs a consistency scan, and creates a branch, commit, and draft MR per target.
- Orchestrator — Handles discovery, filtering, preview, approval, issue creation, and produces a structured handoff (
Tools: GitLab-native tools —
get_merge_request,list_merge_request_diffs,gitlab_api_get,create_commit,create_merge_request,create_issue, and othersAnti-hallucination strategy: Critical identifiers (project IDs, paths) go through deterministic steps and template variables — never parsed from LLM-generated text. The inter-component handoff uses a structured format with verbatim-copy instructions.
🚧 Challenges I Ran Into
- Demo environment setup: The hackathon project provided by GitLab is the canonical source for the flow definition, but testing requires actual target projects with real code. I had to create a separate group with demo projects, add a mirror flow definition there, and keep the two in sync throughout development. Recording the demo video required this parallel setup to work end-to-end.
Demo repositories:
- demo-mirror-flow — mirror of the official hackathon project's flow definition, used for testing
- nodejs-demo — source project (reference MR lives here)
golang-demo, nodejs-demo-2, nestjs-demo — target projects for replication
- Topic filtering limitations: The GitLab Groups API only supports filtering by a single
topicparameter. I wanted to support multiple topics with OR semantics (e.g., "target all Node.js OR Go projects"). Since the API couldn't handle this natively, the Orchestrator fetches all group projects and performs multi-topic filtering client-side through LLM-driven logic.
- Topic filtering limitations: The GitLab Groups API only supports filtering by a single
Native topic filtering through GitLab Groups API without any client-side work would've been a much better choice, but I had to work with what I got for demo purposes.
- Flow-to-flow communication: The ideal architecture would separate the Orchestrator and Replicator into independent flows — the Orchestrator would trigger the Replicator per target project, each running in its own project context with isolated failure handling. However, GitLab's composite identity mechanism prevents one service account from programmatically triggering another (via assignment, mention, or API). I explored multiple approaches —
assignee_idon issue creation,update_issuewith assignment,/assignquick actions. All failed silently or returned 500.
The working solution chains both as components within a single flow, which sacrifices per-target isolation but achieves fully automated end-to-end execution with zero human intervention after approval. If I could, independent flows for Orchestrator and Replicator would've been the better choice.
🏆 Accomplishments That I'm Proud Of
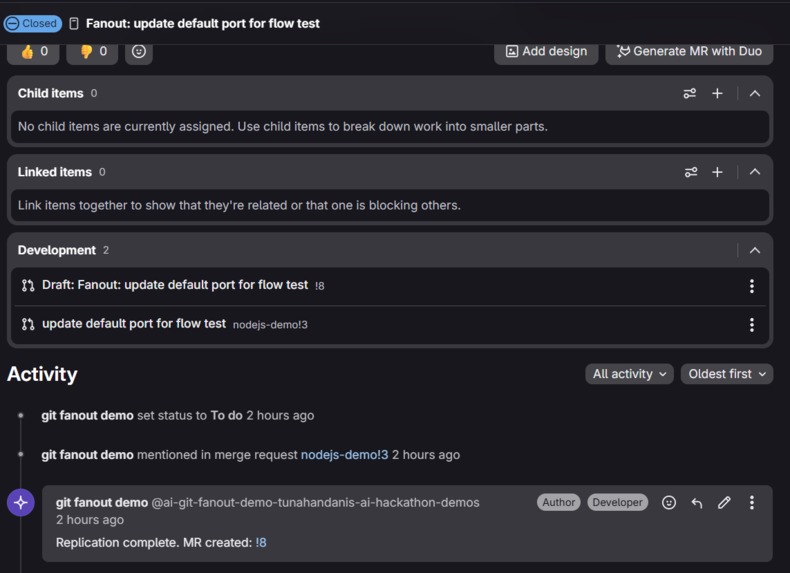
Zero human intervention after approval: Once the user approves the fanout execution, the entire replication pipeline — issue creation, diff analysis, cross-language adaptation, consistency scanning, branch creation, MR opening, and issue closure — runs autonomously.
Consistency analysis that actually works: The Replicator doesn't just apply the diff to matching files. It reads every file in the target project first, then catches the ripple effects — if a port number changed in code, the same value likely appears in config files, Dockerfiles, docs, and CI pipelines. By having all file contents loaded before analysis, these cross-file references are spotted and updated in a single pass.
Cross-language replication: The Replicator doesn't require target projects to use the same language or framework as the source. It understands the intent of the change and adapts it to the target's stack — a config change in JavaScript can be replicated as the equivalent change in Go or Python.
📚 What I Learned
LLM reliability requires structural guardrails: Prompt instructions alone aren't enough. Anti-hallucination rules frequently get ignored. Moving critical values (project IDs, paths) to deterministic pipeline steps was the real fix.
"Read everything first" beats "scan later": Having the Replicator read all project files upfront before analysis produced far more reliable consistency detection than a separate post-classification scan step. When the LLM has full context loaded, it naturally spots cross-file references instead of shortcutting.
The GitLab Duo Agent Platform has a lot of potential. This was my first time building on it, and being able to wire up deterministic steps and AI agents in a single YAML file was a nice surprise. It took some trial and error to get the hang of it, but once it clicked, iterating was fast.
🌱 What's Next for git fanout
Parallel target processing: The Replicator currently handles targets one by one. Ideally, each target would be processed concurrently — something that becomes possible if I can find a workaround or GitLab adds support for flow-to-flow triggering in the future so I can build independent flows for Orchestrator and Replicator.
Dry-run mode: A mode that shows what changes would be made to each target without creating branches or MRs — useful for auditing the AI's reasoning before committing.
Conflict detection: Before creating a branch, check if the target project already has pending changes to the same files and flag potential merge conflicts.
Built With
- gitlab

Log in or sign up for Devpost to join the conversation.