-
-
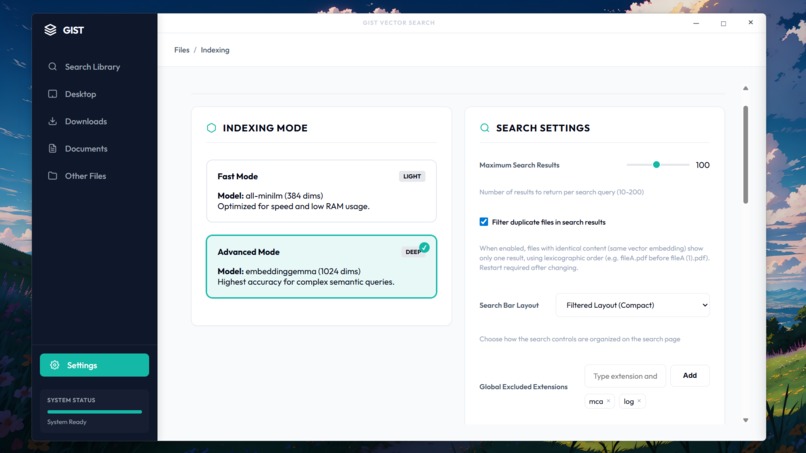
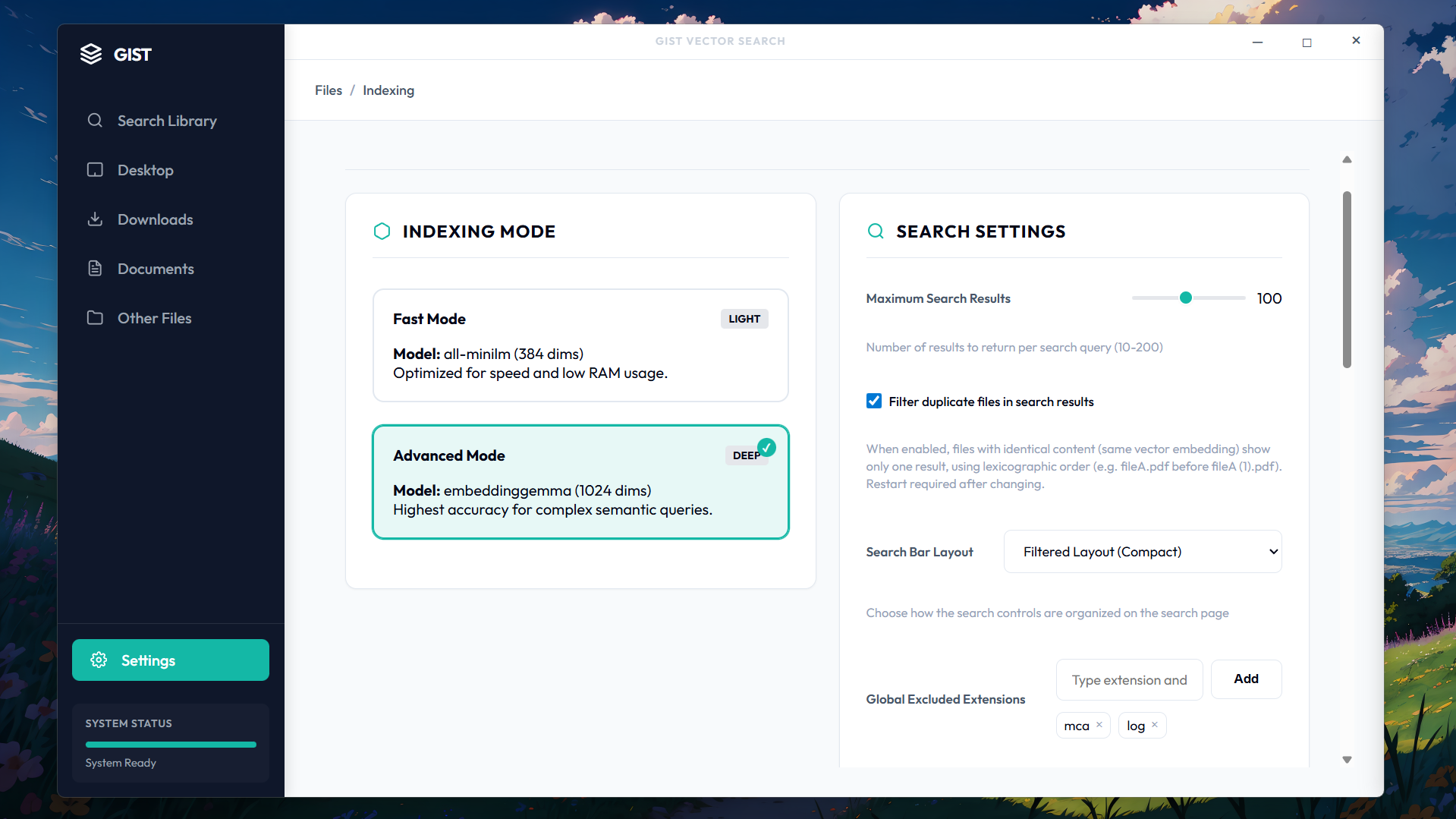
Settings page
-
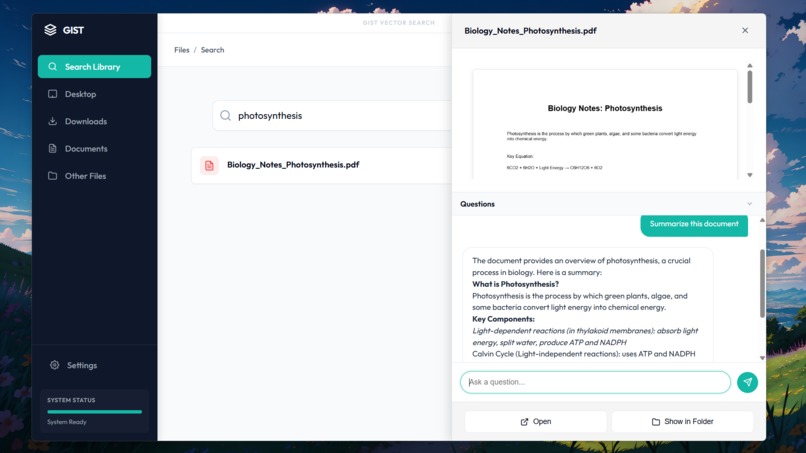
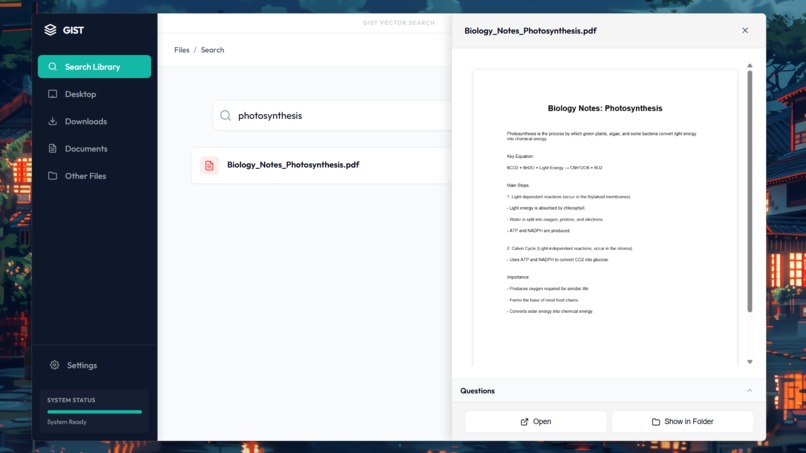
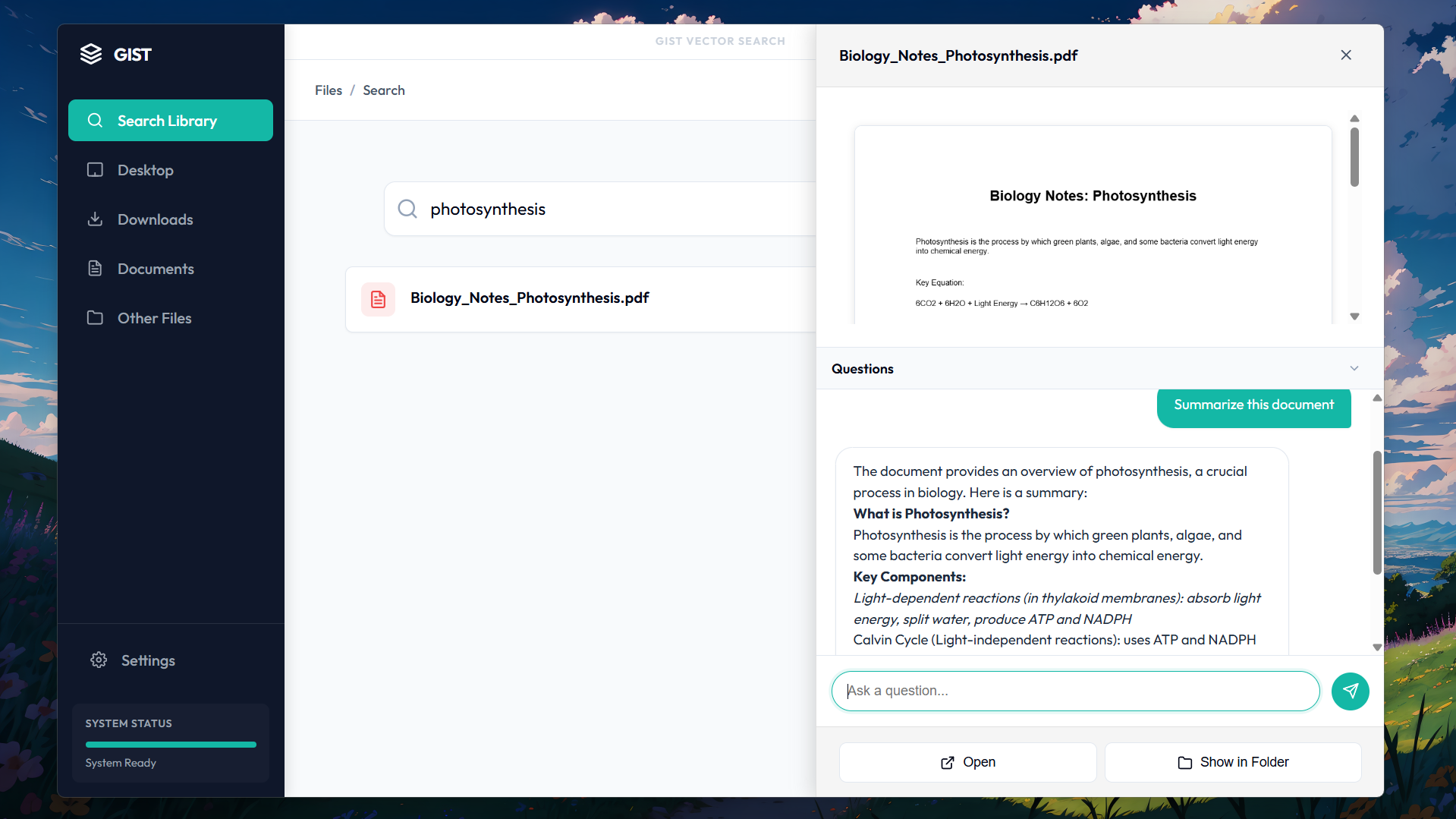
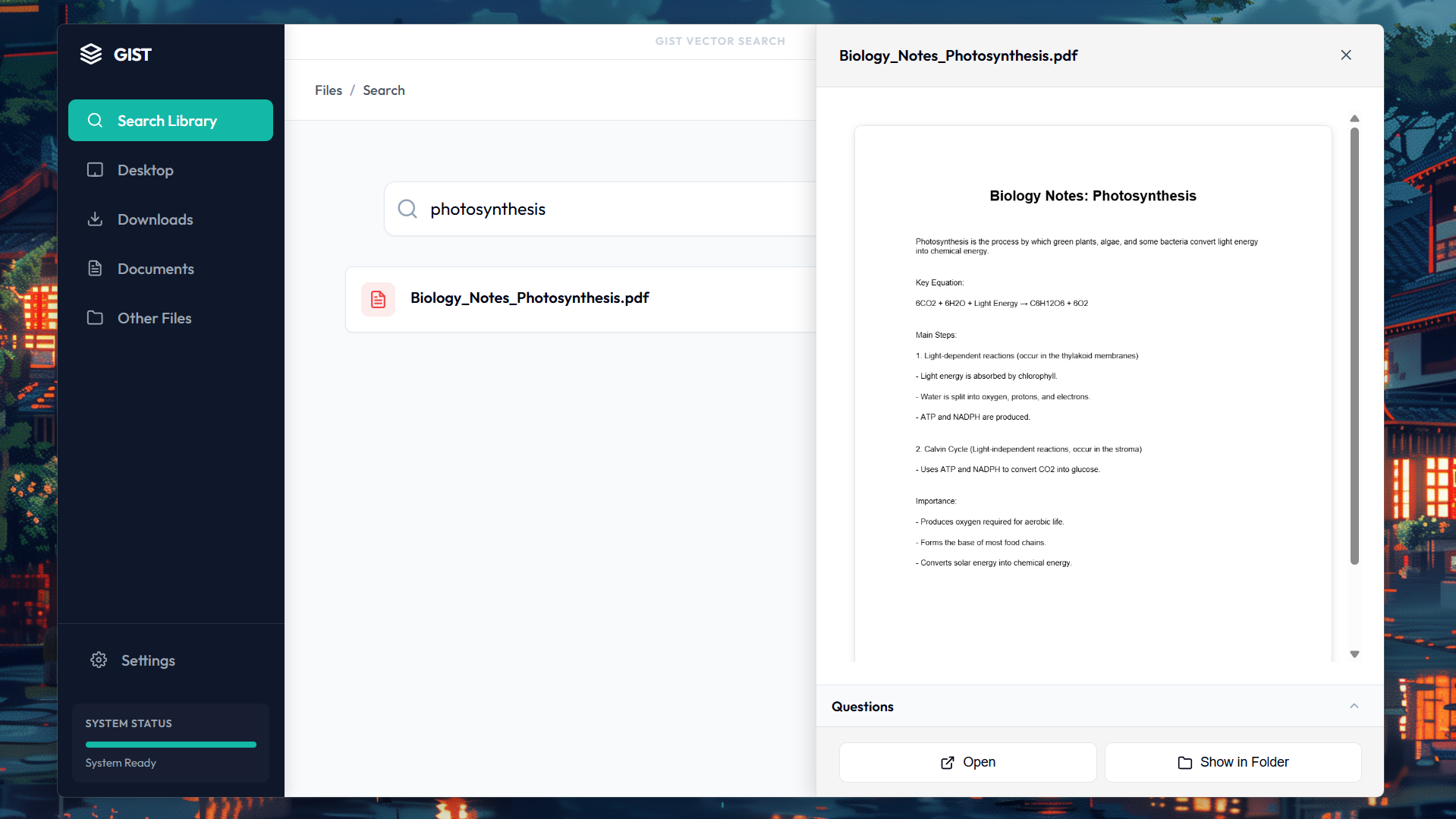
Preview window with AI features
-
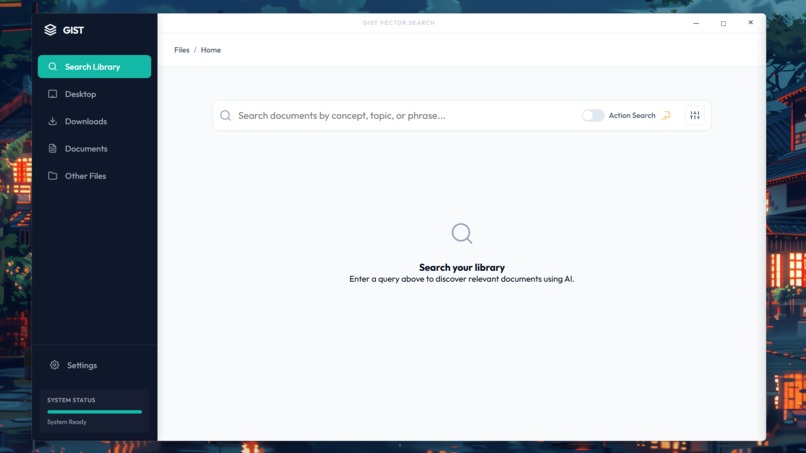
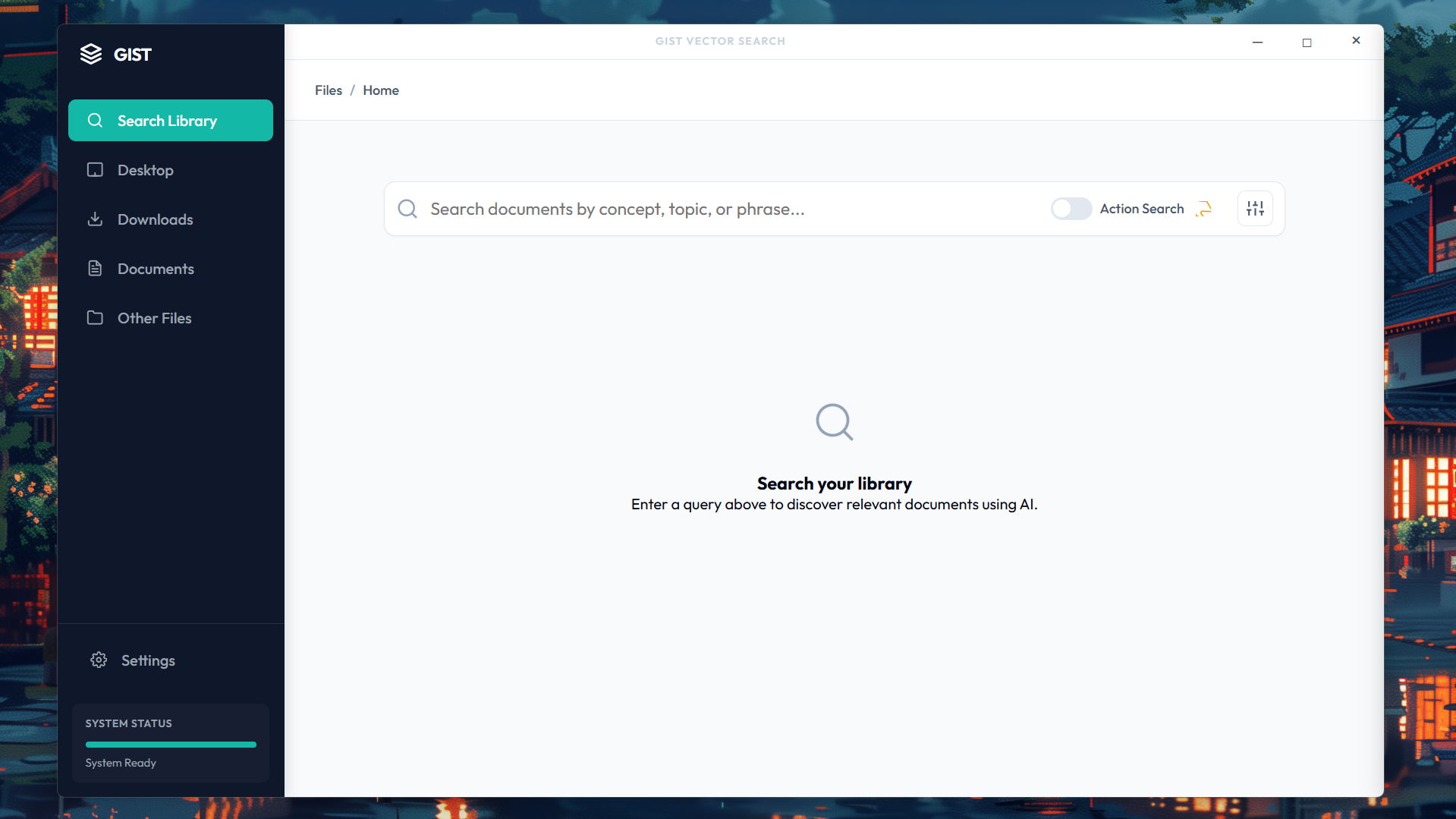
Home search page
-
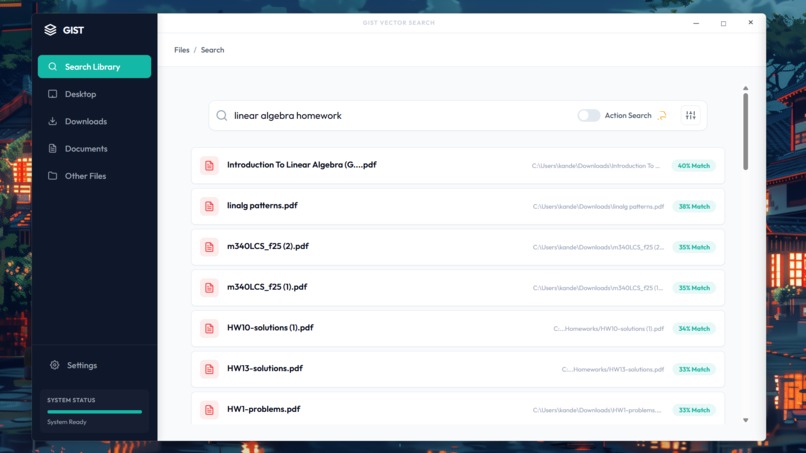
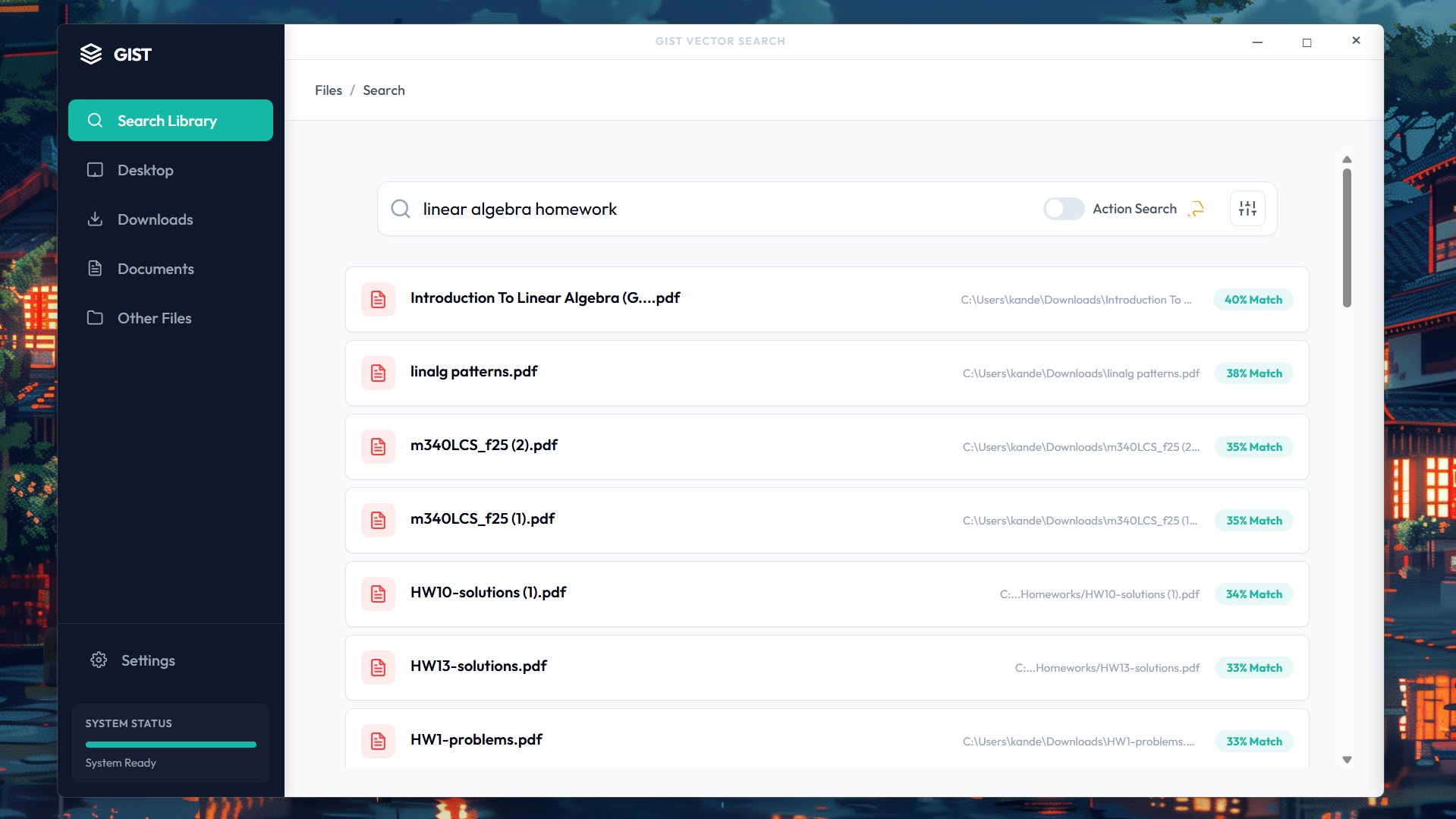
Search result
-
Base preview window
-
Built In File Exploerer
-
Built in file explorer
Inspiration
My friend asked for my linear algebra homework, which I had on my desktop, but I couldn't find it because it was named hw#. The issue with that is that my calculus, discrete math, and statistics were also named the same way, so I spent 15 minutes just going through my files trying to find them; it was just frustrating. I was wishing I could just search "Linear Algebra Homework," and the file explorer would just understand. That was how the idea behind GIST came to be.
What it does
The application vectorizes all your files using a small local Ollama model that can run on almost any laptop, and then when you go to search for the file you want, it compares your search to the vectorized embeddings, giving you the item based on what you asked for. On top of that, by utilizing filter detection parameters, we can also detect more complex prompts. "Photos from my trip in December" will filter for both the image file type along with items created in December.
How we built it
We used a Rust backend to handle the Ollama models and an Electron frontend to create an application that can run on your desktop.
Challenges we ran into
There were no shortcomings when it came to challenges or roadblocks. I've listed two below, but I could keep listing 10 more. The best part of this project was thinking through all the edge cases and the issues and building solutions that work. -Large PDF Context Length Errors Problem: Very large documents (100+ pages, 230K+ tokens) exceeded embedding models' 2K token context windows, causing indexing failures even after 50% and 25% truncation attempts. Solution: We implemented log-based region sampling that divides documents into ~6 intelligently sampled sections instead of ~50 sequential chunks, with each section staying under the token limit by sampling representative content from the beginning, middle, and end of each region.
- Hybrid Search Architecture with Multi-Modal Ranking Problem: Balancing semantic vector search with filename-based queries was difficult—simple queries like "homework.pdf" needed filename matching, while conceptual queries like "calculus derivatives" needed semantic understanding. Solution: We built a dynamic hybrid similarity scorer that detects query intent and adjusts vector/filename weighting accordingly (70% filename for specific file queries, 80% semantic for conceptual queries), with additional penalties for short filenames and small files to reduce false positives.
Accomplishments that we're proud of
Gist started as a simple frustration and turned into a full desktop application that can understand what a user means instead of what they literally typed. Getting a local embedding model to run smoothly, building a Rust backend that stays fast under load, and designing a hybrid search system that feels natural were all big wins. Solving the large‑PDF problem and building intent‑aware ranking made the system feel reliable instead of “demo‑only.” The biggest accomplishment is that Gist already works in real daily use and solves a problem that affects almost everyone who touches a computer.
What we learned
This project showed how much complexity hides behind something that seems simple like “search for my files.” I learned how embedding models behave with different file types, how to design chunking strategies that respect token limits, and how to balance semantic meaning with literal filename intent. I also learned how to structure communication between a Rust backend and an Electron frontend without blocking the UI. Most of all, I learned how important it is to think through edge cases early and build systems that stay fast, private, and predictable even when the inputs are messy.
How to use Gist
There are releases on the official GitHub page; download the most recent release and follow the instructions on the GitHub readme. Gist does require you to have Ollama installed, as that is where we get the embedding models from.
What's next for Gist?
I plan on adding another embedding model that can handle images. Currently images are vectorized based on their name, and I am not satisfied with that. Vectorizing images takes a while, so I am currently researching models and techniques to see if I can make it any faster. I have released a downloadable EXE file on GitHub, and I hope to put out a couple more releases before I feel this project would be complete. I want to get to a point where I can almost completely replace my normal file explorer.
Built With
- electron
- javascript
- ollama
- rust

Log in or sign up for Devpost to join the conversation.