-
-
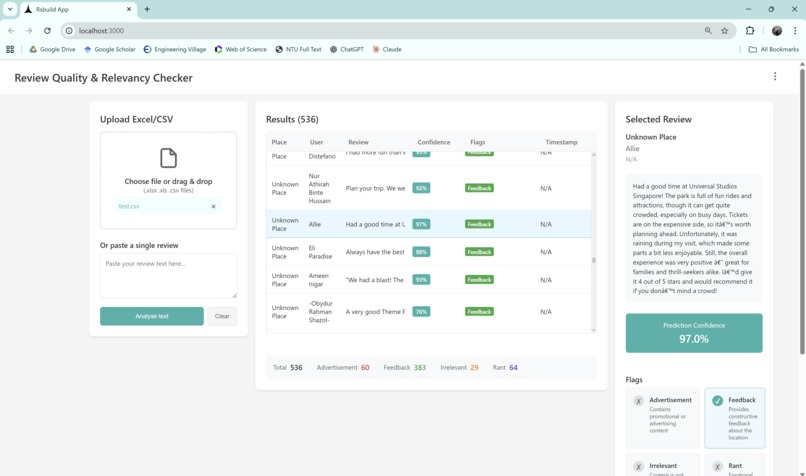
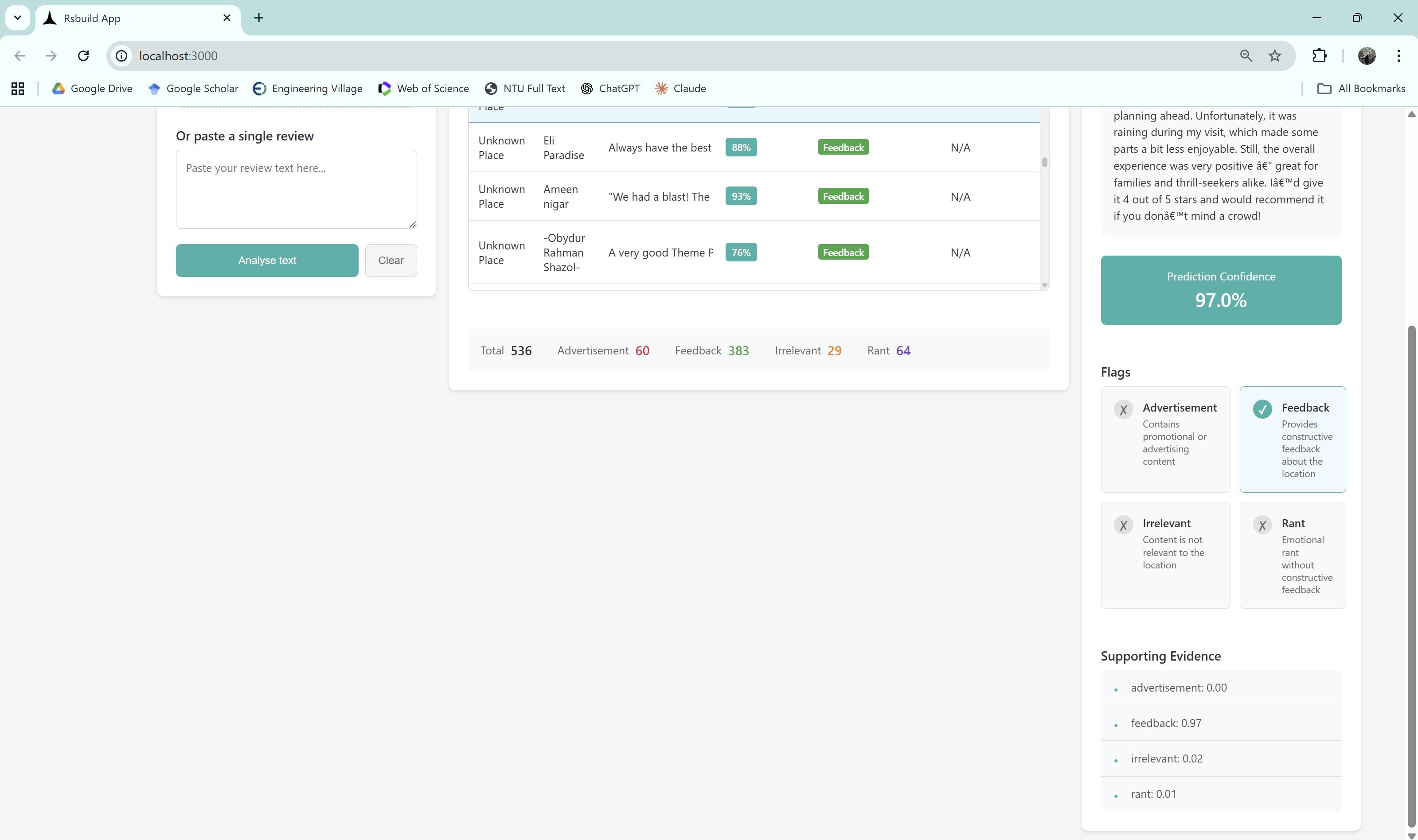
web app in action (upper half)
-
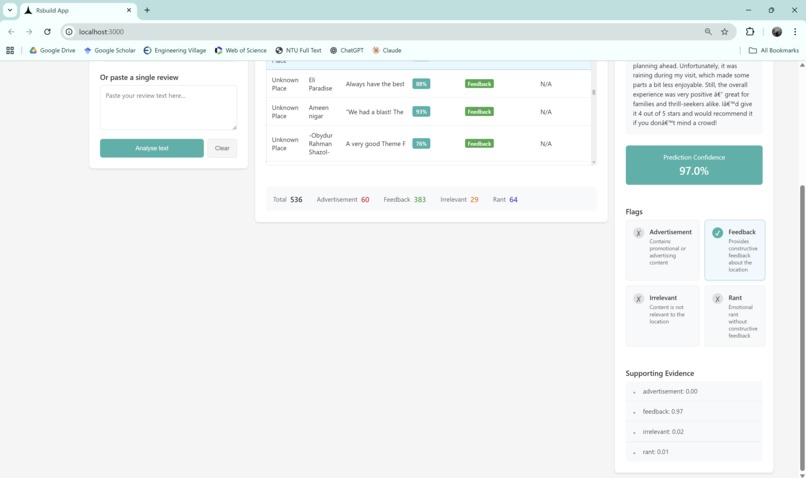
web app in action (lower half)
-
No Input
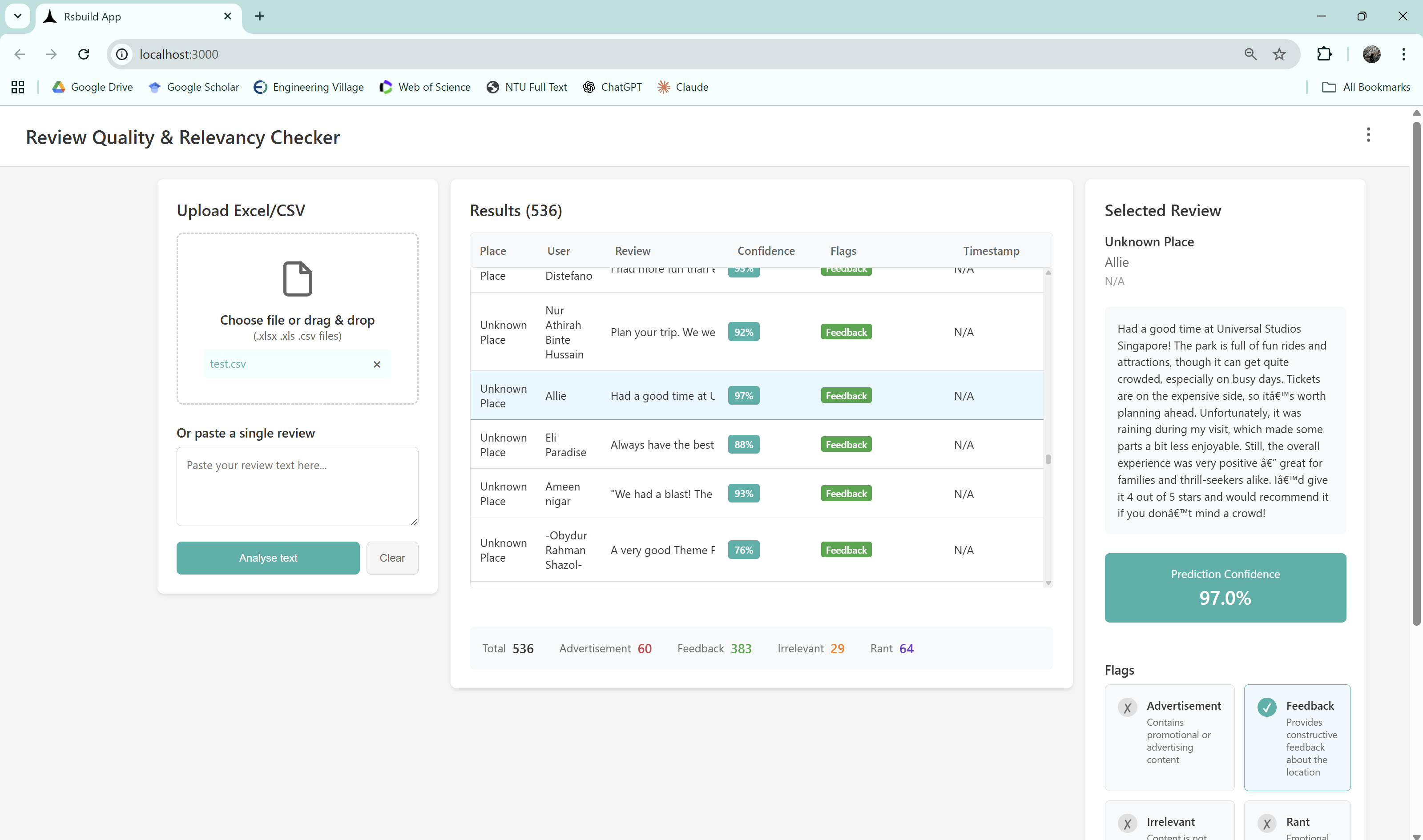
Inspiration
Online review platforms are flooded with advertisements, irrelevant content, and negative rants that do not provide meaningful insights. This makes it difficult for users to trust reviews and for businesses to receive fair feedback. We wanted to create a system that improves review quality and makes platforms more reliable for both users and business owners.
What it does
Our solution evaluates the quality and relevance of reviews by combining tailored NLP preprocessing with machine learning to highlight genuine reviews, thus making review platforms more trustworthy and useful for users
How we built it
Reviews are first cleaned to remove unnecessary noise while keeping important signals like negations (“not,” “never”) and promotional terms (“free,” “discount,” “deal”), since these directly change meaning (e.g., “not good” vs. “good”) and help in spotting advertisements. We then apply lemmatization and TF–IDF vectorization to capture meaningful language patterns. Using these features, we trained Logistic Regression and Random Forest models to classify reviews into four categories: Advertisement, Irrelevant Content, Rant, and Feedback.
- Advertisement consisted of reviews that are promotional in nature, often containing sales language, discount codes, links, or invitations to buy/visit, rather than genuine user experiences.
- Irrelevant Content consisted of off-topic reviews that do not provide meaningful feedback about the place, such as random comments, unrelated discussions, or cases where the reviewer clearly did not visit the location.
- Rant consisted of highly negative and emotionally charged reviews expressing dissatisfaction, often exaggerated or hostile in tone, and providing little to no actionable feedback for improvement.
- Feedback consisted of genuine, experience-based reviews that are on-topic and constructive.
While Logistic Regression achieved slightly higher accuracy in our tests (95% vs. 91%), Random Forest proves more reliable overall. It captures non-linear feature interactions, manages noisy high-dimensional TF–IDF data better, handles class imbalance more effectively, and offers interpretability and scalability for real-world use.
Challenges we ran into
One challenge was finding a suitable dataset to train on — many available datasets didn’t fit our exact problem, so we had to adapt. Another was the steep learning curve with NLP: figuring out what preprocessing steps mattered and how to handle imbalanced classes was tricky.
Accomplishments that we're proud of
We achieved high accuracy (around 95%) and built a pipeline that handles noisy, high-dimensional text effectively. Random Forest was quite robust, capturing non-linear feature interactions and offering better real-world applicability.
What we learned
We learned the importance of preprocessing in NLP and how to evaluate models beyond just accuracy. In particular, we gained a deeper understanding of Logistic Regression, Random Forest, and how to properly assess them using metrics such as the F1 score.
What's next
Future improvements could include incorporating deep learning models for richer context understanding.
Built With
- css
- html
- javascript
- jupyter
- nltk
- pandas
- python
- randomforest
- react
- scikit-learn











Log in or sign up for Devpost to join the conversation.