Inspiration
Organizing developer events and hackathons, I constantly see talented peers struggling to land their first real-world freelance projects. They have the coding skills, but lack the sales pipeline to find clients. At the same time, local mom-and-pop shops are falling behind because they lack a basic digital presence. I wanted to build a bridge. GigHunter was born from the idea that finding these "digital gaps"—like an unclaimed Google listing or a missing website—shouldn't require expensive, enterprise-grade sales software.
What it does
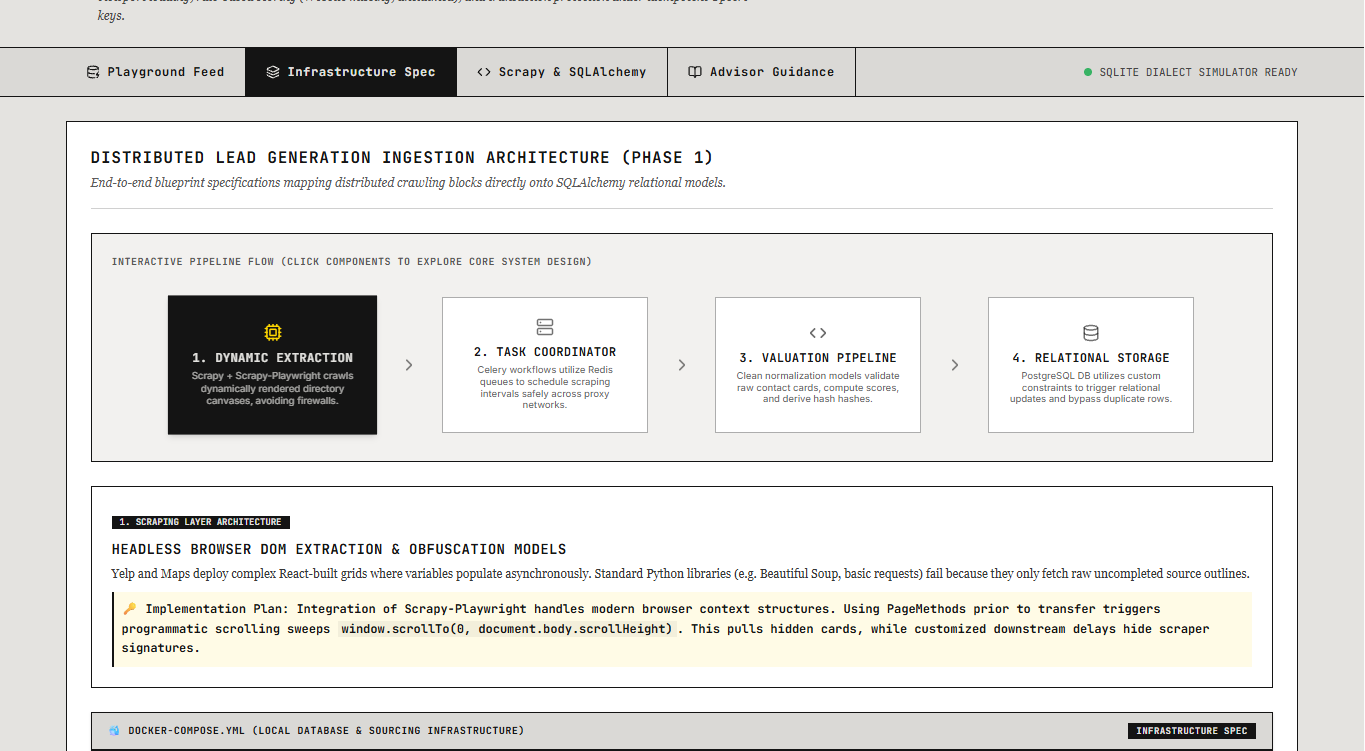
GigHunter is a hyper-local lead generation engine wrapped in an interactive educational sandbox. At its core, it crawls local business directories and evaluates them, assigning an "Opportunity Score" based on missing digital elements.
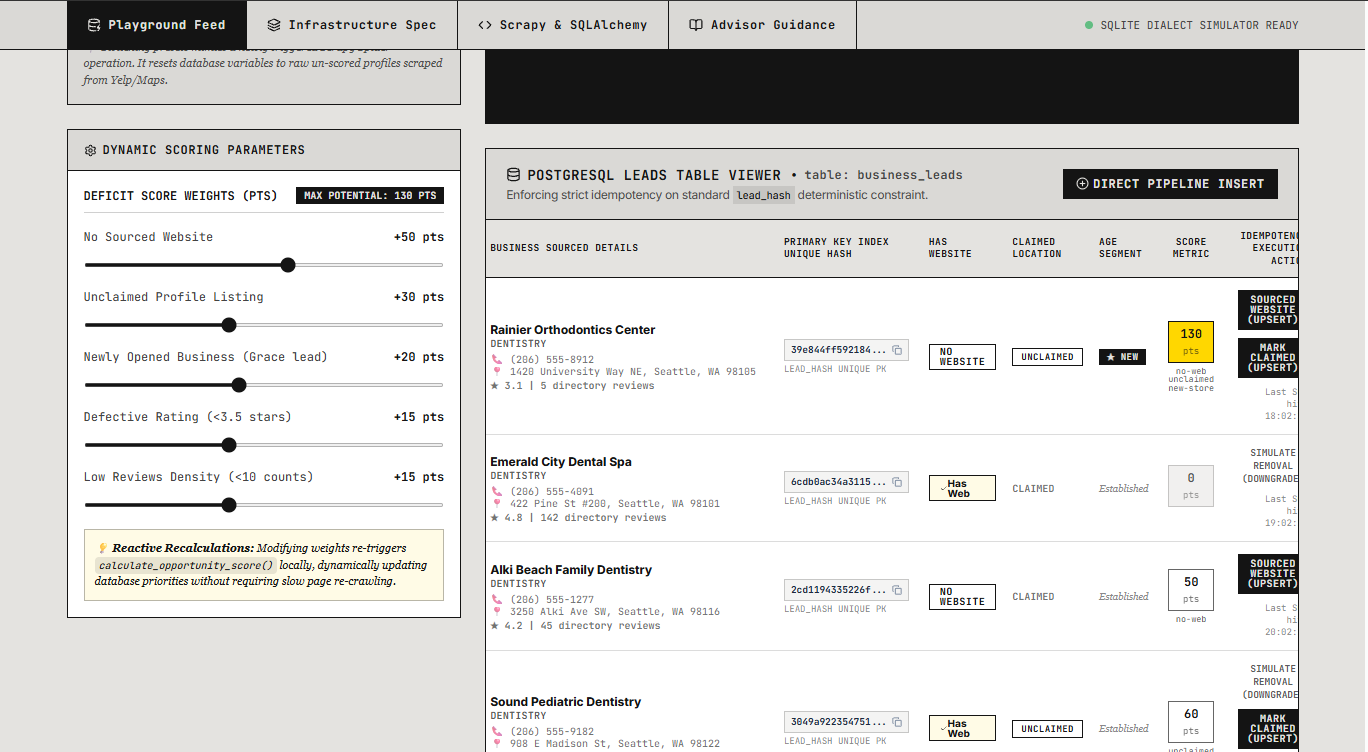
However, rather than just running a script in the terminal, I built a Systems Engineering Mentorship Board. The interface visually demonstrates how the backend works. Users can slide parameter weights (e.g., making a "Missing Website" worth +50 pts) and watch the database recalculate priorities dynamically. It teaches beginners how data aggregation, asynchronous scraping, and database idempotency actually work under the hood.
How we built it
I built the core engine using Python 3.11+. The extraction layer utilizes Scrapy coupled with Scrapy-Playwright to handle Single Page Applications (SPAs) that require heavy JavaScript rendering.
To manage the data ingestion safely, I used SQLAlchemy 2.0 (with strict PEP 484 type hints) and PostgreSQL. Task queuing for the scrapers is orchestrated by Celery with a Redis broker, all containerized via Docker. Approaching the pipeline with a proactive security and reliability mindset, I integrated residential proxy rotation and randomized politeness delays to navigate Web Application Firewalls (WAFs) safely.
Challenges we ran into
- Dynamic DOM Rendering: Standard HTTP requests failed to capture data on modern directory sites. I had to integrate headless browser contexts using
Scrapy-Playwrightand customPageMethodsto programmatically trigger infinite scrolls before capturing the DOM. - Cloud Protections & Anti-Bot: Navigating enterprise WAFs without getting IP blocked required carefully tuning proxy pools, randomizing User-Agent heuristics, and hiding automation traces.
- Concurrency Race Conditions: Running multiple asynchronous Celery workers created race conditions that led to duplicate database entries. Doing existence checks in Python was too slow and unreliable. I solved this by pushing the idempotency logic directly down to the PostgreSQL layer using an atomic
INSERT ... ON CONFLICT DO UPDATEstatement tied to a deterministic SHA-256 hash of the business name and phone number.
Accomplishments that we're proud of
I am incredibly proud of transforming a purely backend scraping utility into an interactive learning tool. The "Advisor Guidance" modules within the UI successfully demystify complex concepts like SQL concurrency and WAF bypassing for beginner developers. Additionally, engineering a perfectly idempotent data ingestion pipeline that seamlessly updates lead scores in real-time without duplicating records was a major technical milestone.
What we learned
I deepened my understanding of SQLAlchemy 2.0's declarative mapping and asynchronous database sessions. I also learned how to intricately balance system performance with network stealth when rendering heavy JavaScript payloads through headless browsers. Most importantly, I learned how to visually communicate abstract, complex backend architectures to a broader audience.
What's next for GigHunter
The next evolution involves integrating a locally hosted Large Language Model (LLM) to perform sentiment analysis on a business's existing directory reviews. This will refine the Opportunity Score by factoring in qualitative data, modeling the evaluation as:
$$Score_{total} = \sum_{i=1}^{n} (W_{i} \times D_{i}) - \lambda(S)$$
(Where $W$ is the weight of the digital deficit $D$, and $\lambda$ is a penalty factor applied to the positive sentiment score $S$.)
I also plan to implement a robust CI/CD pipeline utilizing DevSecOps principles to automate security testing and container deployment for the distributed Celery workers.


Log in or sign up for Devpost to join the conversation.