
Inspiration
Humans are able to compress long form narrative into sophisticated networks of interactions between characters mediated by the actions they take which causally evolve over time. We want to inspire from this approach and build a system that can do the same: goign from a collection of text to a structured object, in our case a graph of characters and their interactions.
What it does
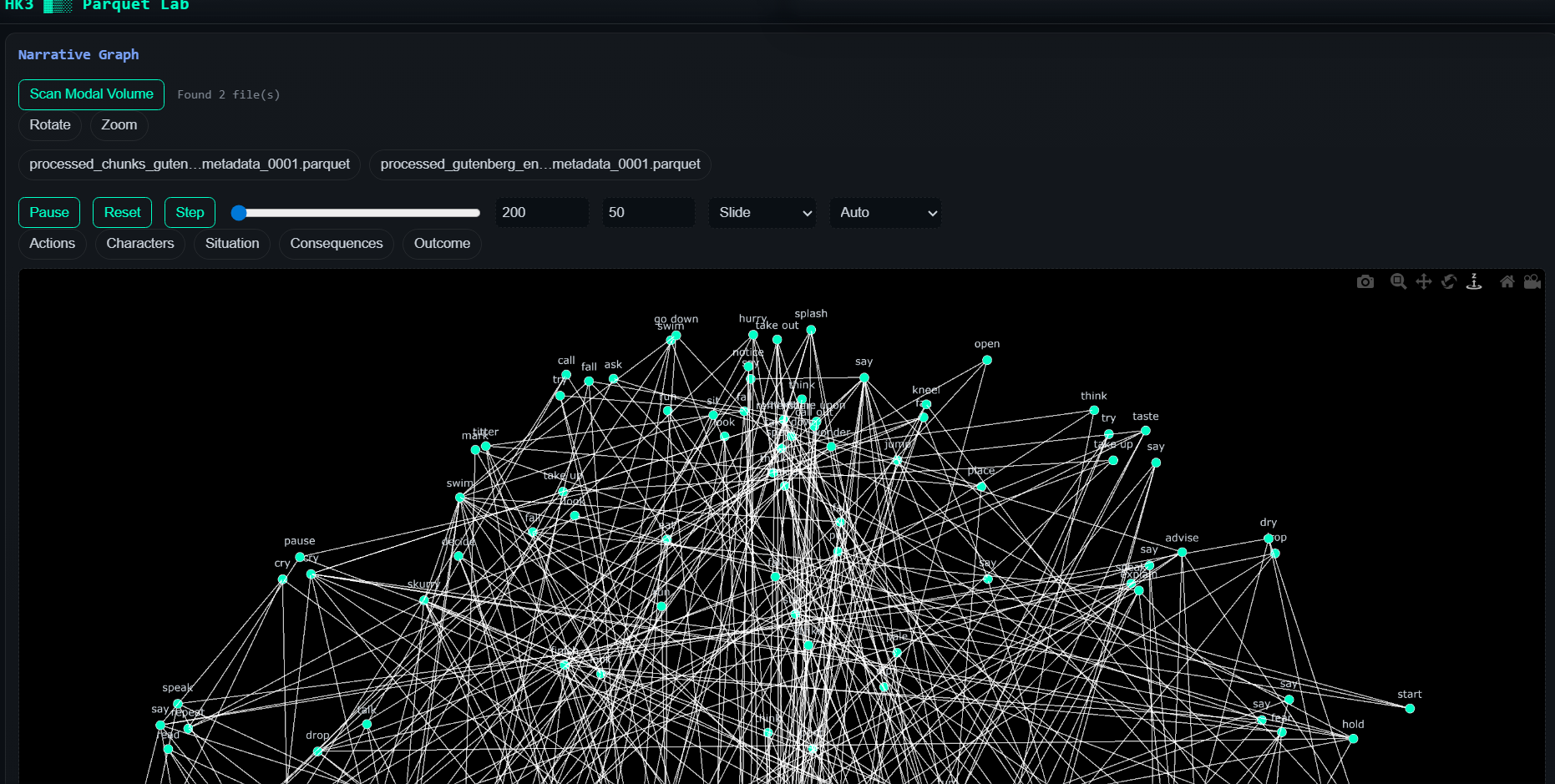
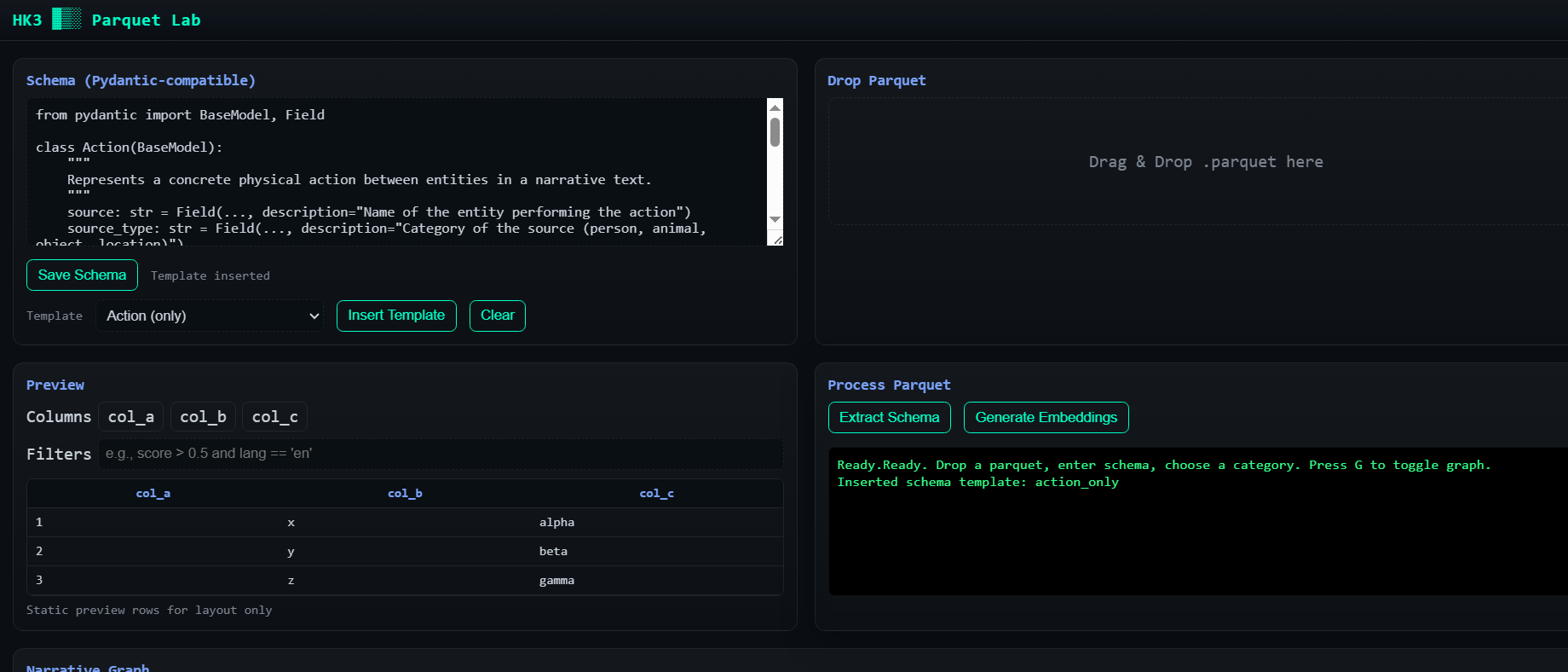
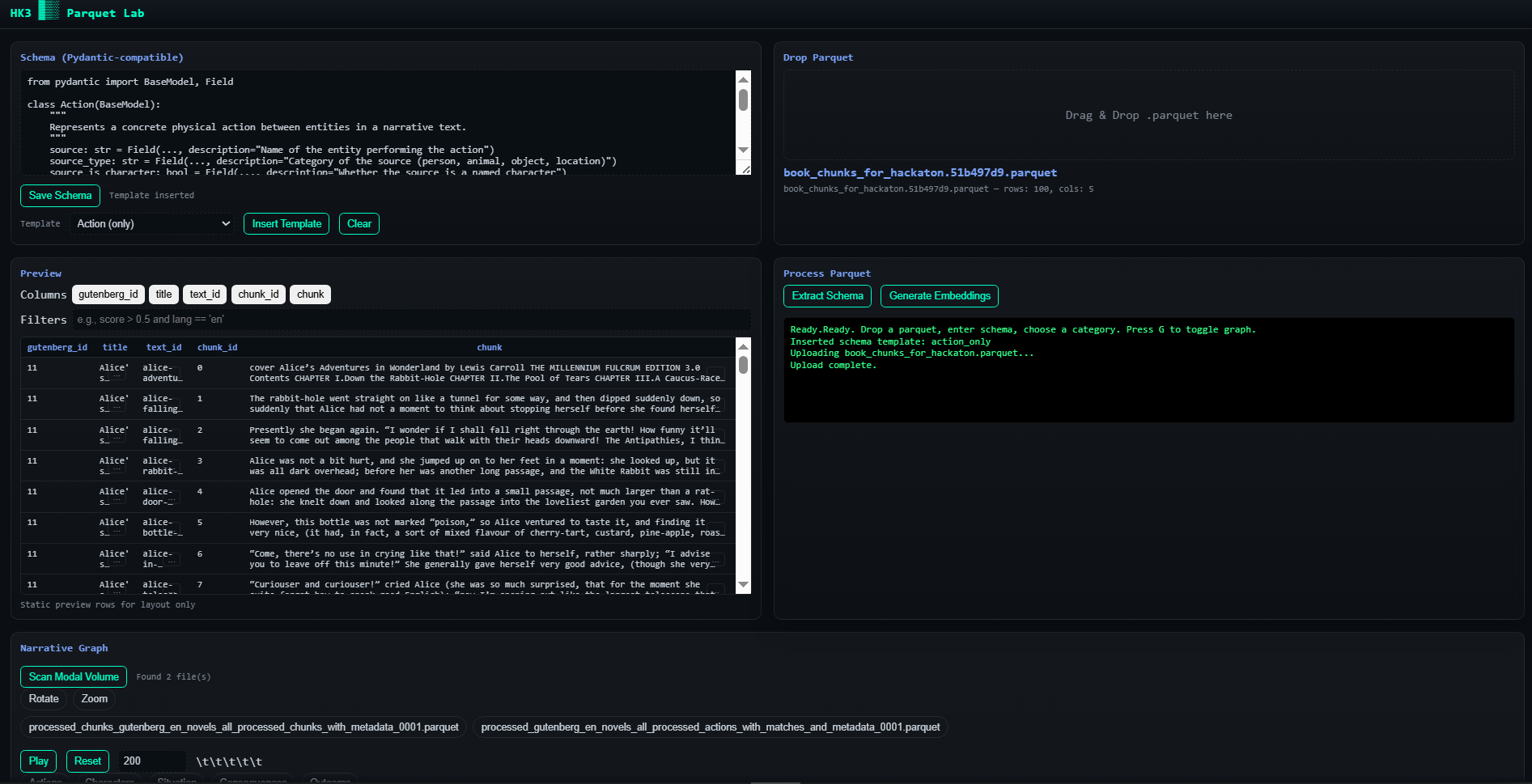
GigaStory is a end to end system which exploits modal horizontal scaling for emulating this process, through a scatter gather approach. The book is broken into small chunks each is processed with Qwen30b using structured generation to extract the characters and the actiosn between them. Finalyl the results are aggreagate into a graph where characters are nodes and the multidimensiona edges describe the type of interactions they had.
How we built it
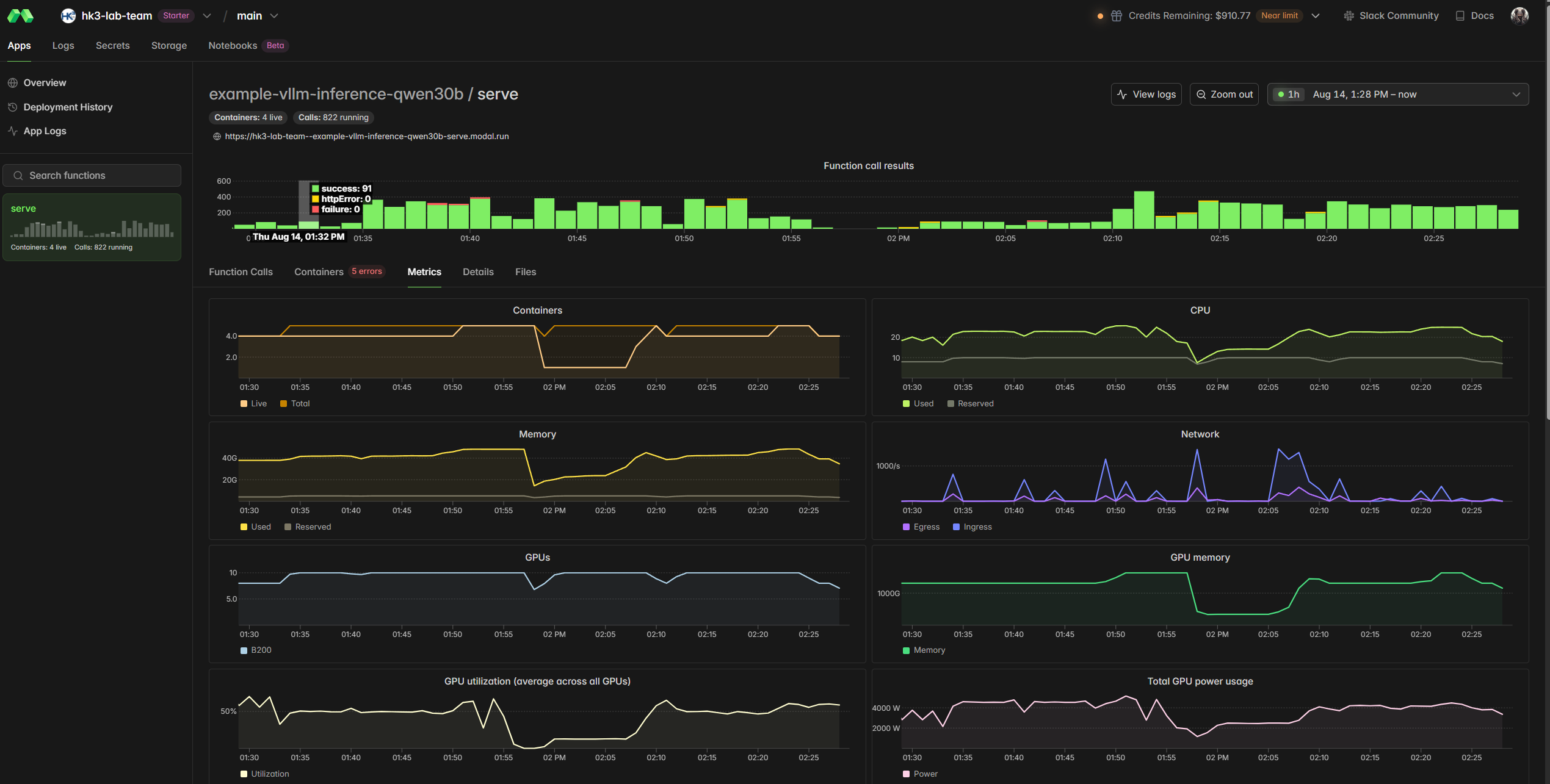
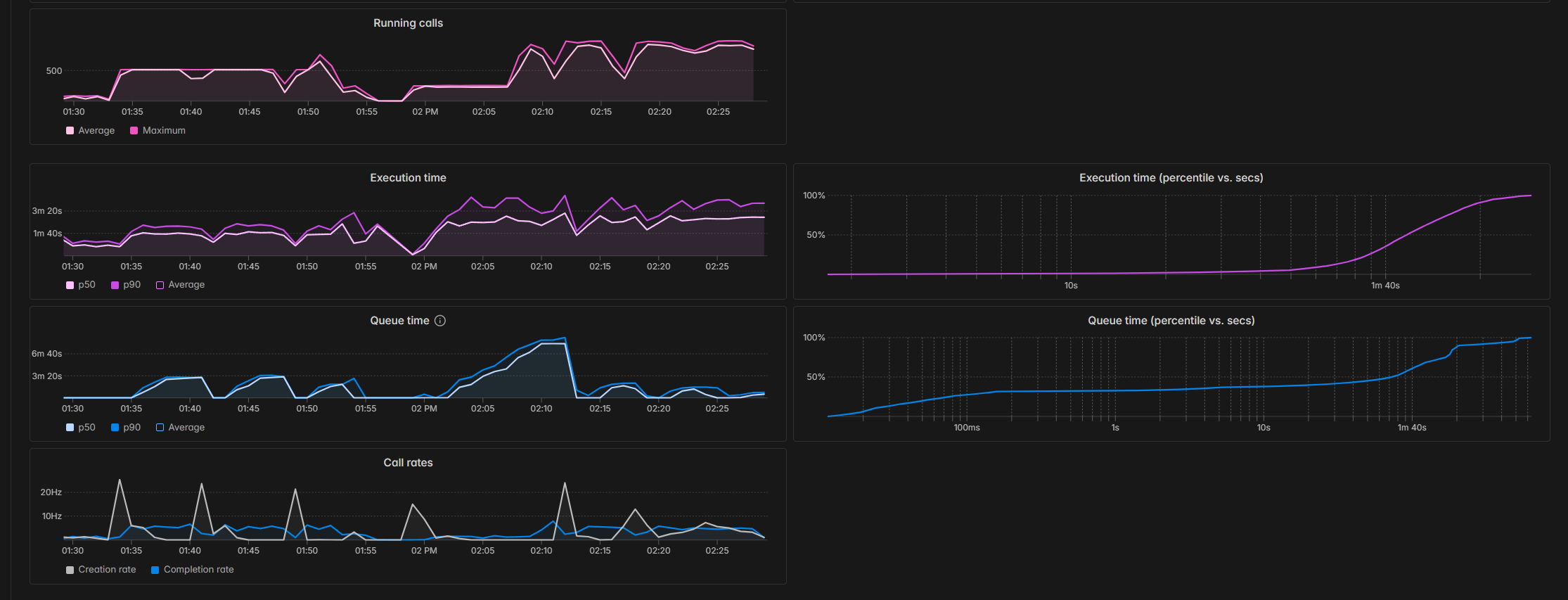
First we processed a subset of Gutenberg English books into adequate chunks of ~ 2000 characters each. Then prepared then in Polars data frame and stored as parquet file (in drive link). We use Modal to deploy an horizontally scaling VLLM server composed by a 2xB200 Node using Qwen30b and expose the OpenAI compatible endpoint. We use Minference (our own soloware - added to github) to orchestrate the requests via asyncio to the server and maximizer throughput without accrueing too much queue on modal. The results are then saved into Modal storage as parquet files and the app read from the storage and aggregate the results into a graph which can be dynamically explored.
Challenges we ran into
Because of the short amount of time we were not able to opt for the Modal batch-job feature and instead built upon the publicaly availabe open ai server endpoint. We had to severly adapt the script and spend conspicuous time on orchestration in order to avoid big queues which would result in a variety of http errors. We also had a multi step process that with a few more hours could be connected but we are still currently doing multiple inefficient data passage between local and modal which could be totally avoided with a full end to end modal solution.
Accomplishments that we're proud of
We have got beutiful graphs coming out of hundreds of books. Have a system that is running at stable at 5HZ each request ~3000 tokens written, each node running at 4/5k tokens per second in batched mode.
What we learned
a LOT - Modal is a game changer for horizontal scaling and we are excited to see what we can build with it once we nail a end to end system fully livin on the system. For now we made use of multiple apis but each independently.
What's next for GigaReader
Full end to end deployment and batch job execution directly from the ui. Exstension to other data types (e.g codebases) with appropriate schemas. A schema design ui and schema editor with git like features for tracking performacne across prompt.
Built With
- javascript
- modal
- pydantic
- python.
- qwen
- vllm

Log in or sign up for Devpost to join the conversation.