-
-
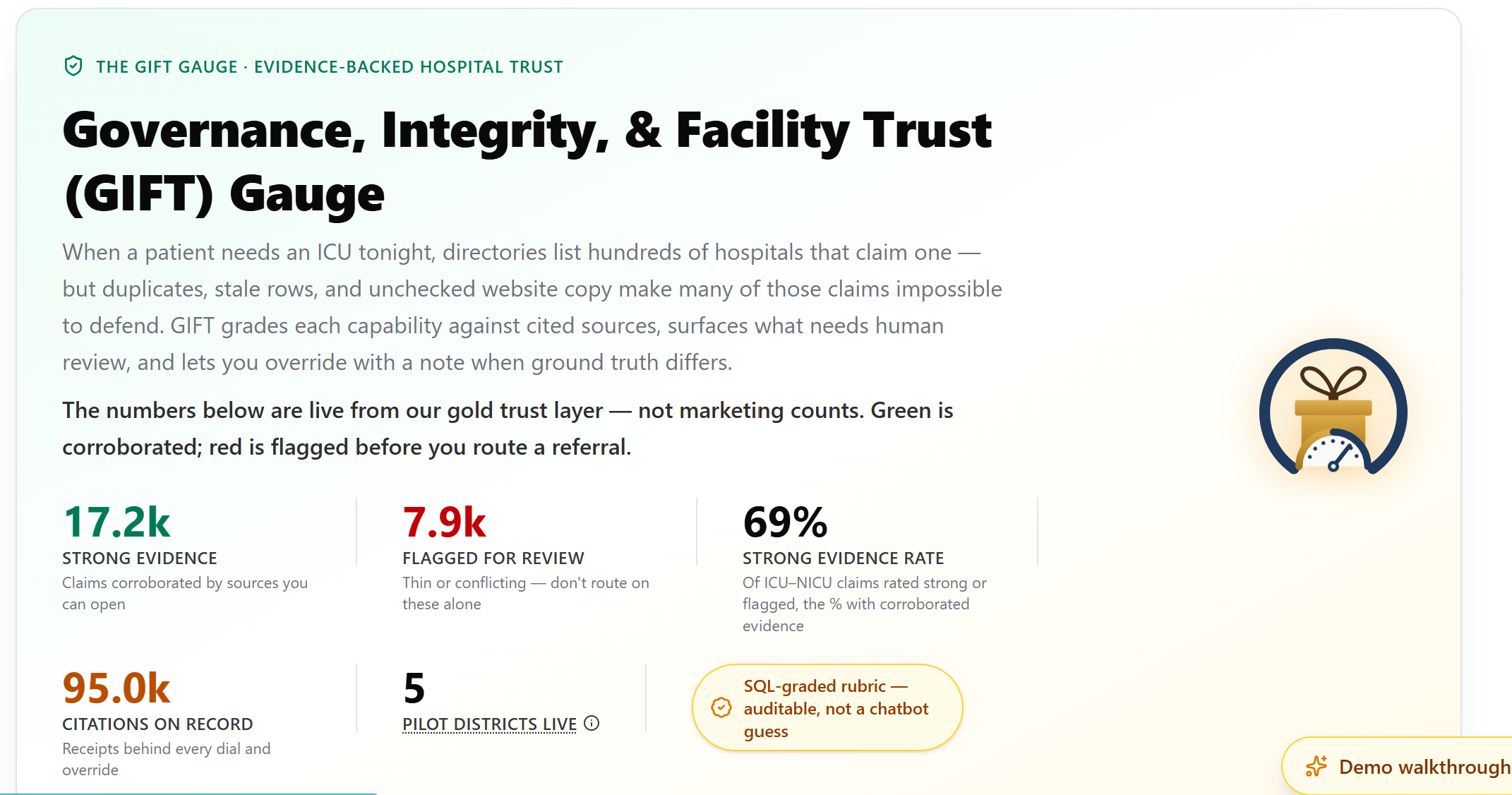
Gift Gauge
-
-
-
Inspiration
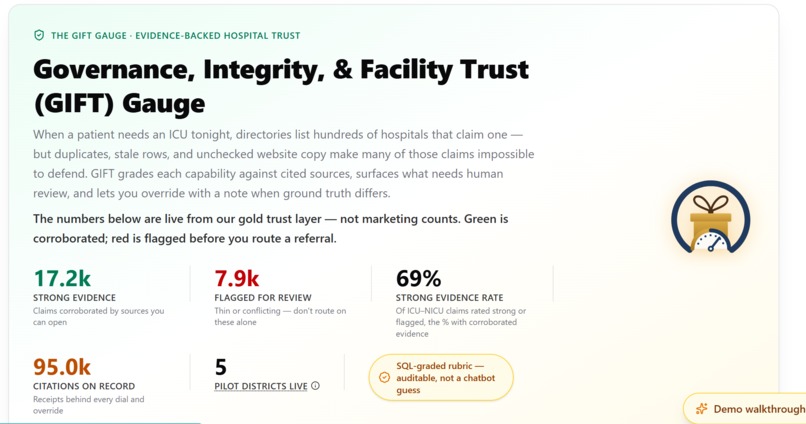
For years, we’ve observed nonprofit planners struggle with hospital directories that act as digital junk drawers. When a patient needs an ICU tonight, planners face hundreds of hospitals that claim to have one, but half those rows are duplicates, stale locations, or unverified self-reported website copy. We realized that for a patient in crisis, bad routing is not just a data quality bug—it is a patient-safety failure.
What it does
GIFT Gauge replaces opaque, unverified directories with an auditable, graded, and grounded trust layer. It provides:
- The "Trust Dial": A hard
evidence_strength_scorecomputed entirely in SQL, blending three auditable inputs: 45% supporting ratio, 25% evidence breadth, and 30% facility match confidence. - Defensible Evidence: We provide receipts for every referral, allowing planners to justify their decisions to district officers or donors.
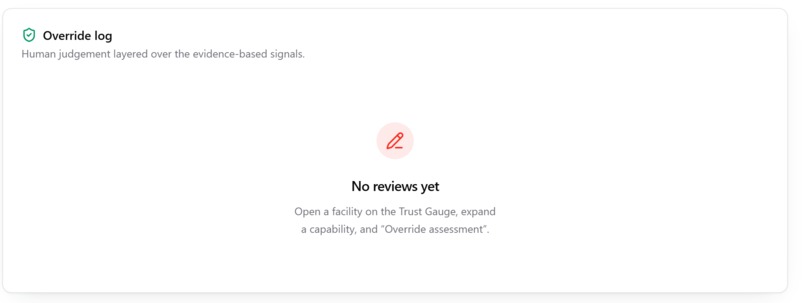
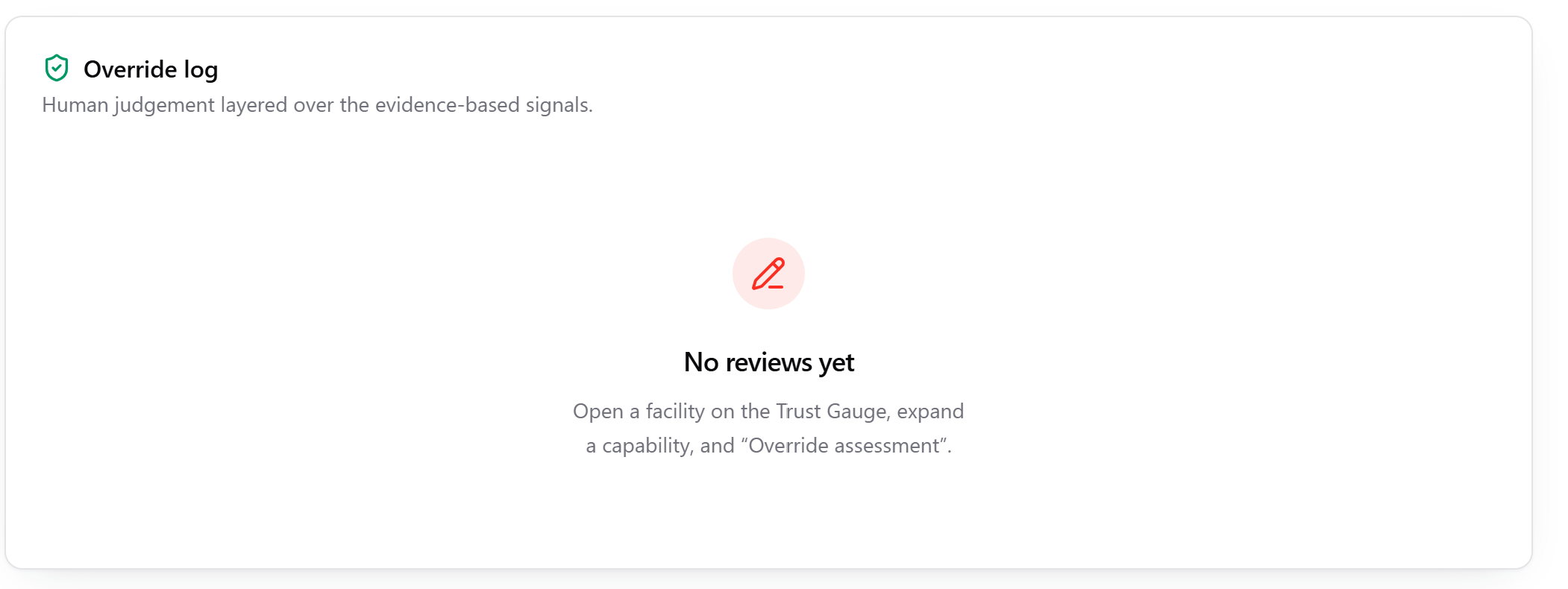
- Human-in-the-Loop Override: Planners hold the keys; they can override automated data with local ground truth that is logged in an auditable trail.
How we built it
We did not build on duct tape and prayers; we built on the Databricks Lakehouse.
- SQL-First Logic: We treat AI as an extractor, not a chatterbox. By forcing database-ready outputs using
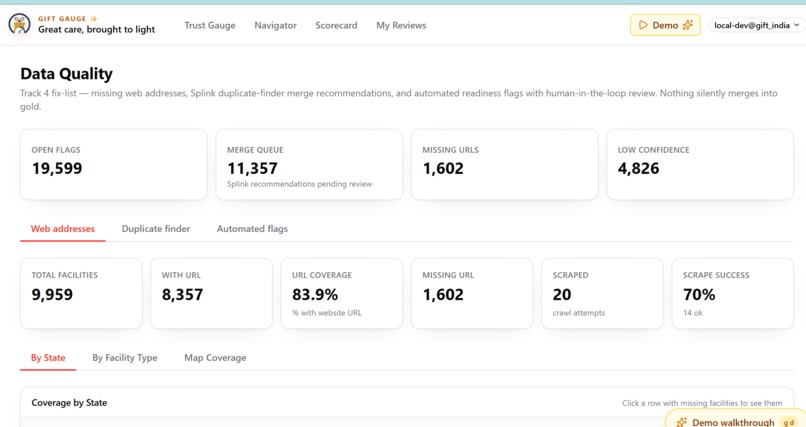
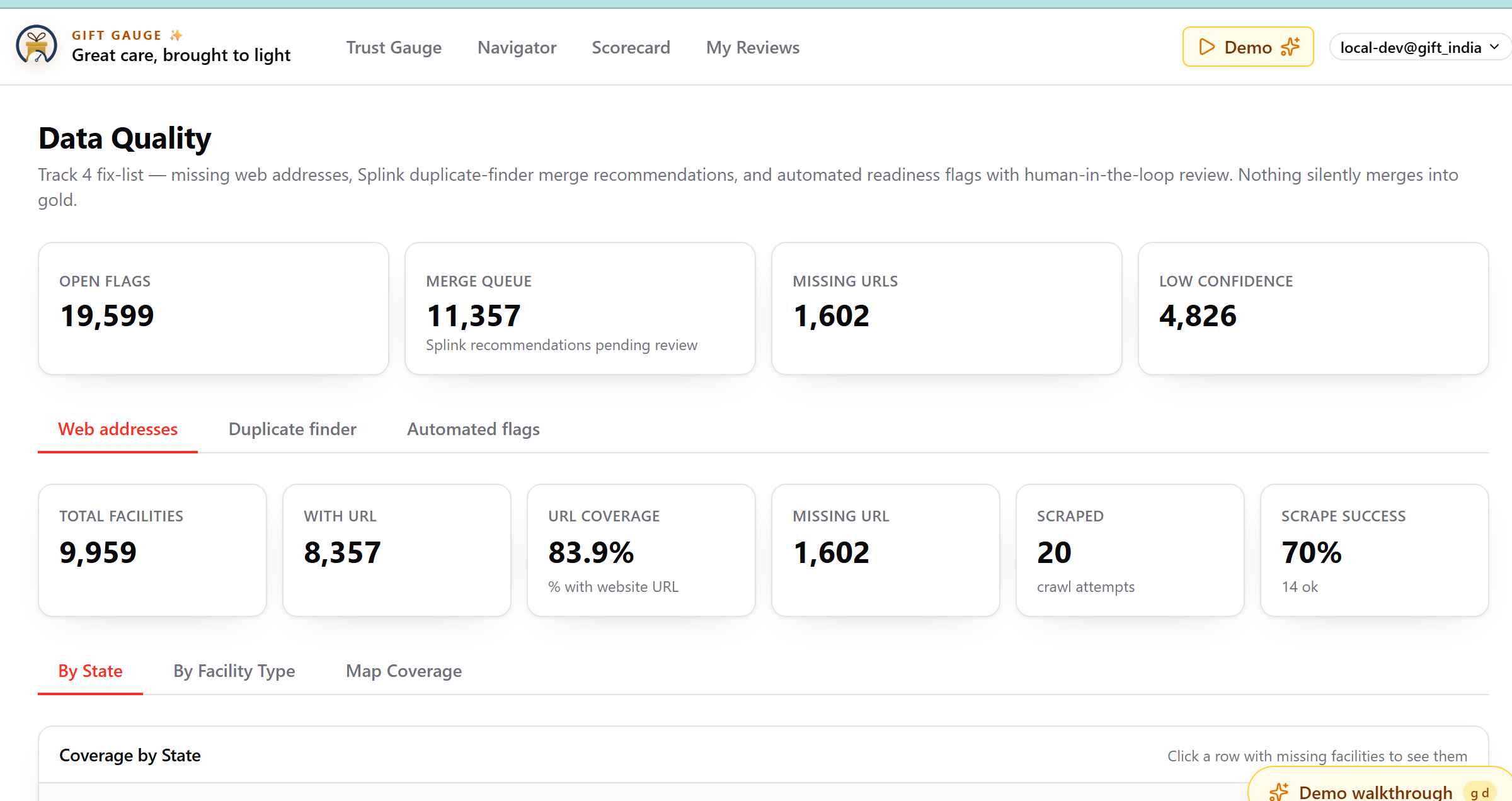
AI_ClassifyandAI_Query, we avoid hallucinated "answers" and conversational fluff. - Data Pipelines: We ingest raw data into a bronze
facilities_*schema, use Splink for probabilistic linkage to surface merge recommendations, and process the final, human-approved merges into a gold trust layer. - Platform-Native Infrastructure: We minimize "franken-coding" by relying on Dabs, Genie, and Lakehouse FTS for everything possible.
Challenges we ran into
- The "429" Reality Check: We hit the Databricks output-tokens-per-minute quota on our ~3,900-row batch. We pivoted by using real narrations for a subset and leveraging deterministic stub cards to keep the demo moving.
- The "Franken-code" Grind: Moving from custom scripts to platform-native infrastructure was a significant challenge, but it provided us with a clean paper trail that stands up in a hearing.
Accomplishments that we're proud of
- SQL-Supervised AI: We implemented a system where SQL supervises the LLM and the user supervises both, ensuring that rate limits or model swaps do not move the trust dial.
- Auditable Transparency: We created an override log that layers human judgment over evidence-based signals, turning learning into an ontology of decisions that planners can actually defend.
What we learned
- The Power of Storytelling: We learned that to make complex data actionable, we must capture the "why" behind the "what," allowing us to scale expertise that planners can actually defend.
- Design Thinking & Human-in-the-Loop: We confirmed that treating AI as an extractor is the only way to ensure database-ready outputs. By keeping humans in the loop, we ensure that identity guesswork is replaced by verifiable match scores.
- Cost-Optimized Routing: We found that sending simple tasks to small models and complex tasks to "heavy" models prevents model bloat and stops overspending on low-complexity routine tasks.
What's next for GIFT Gauge
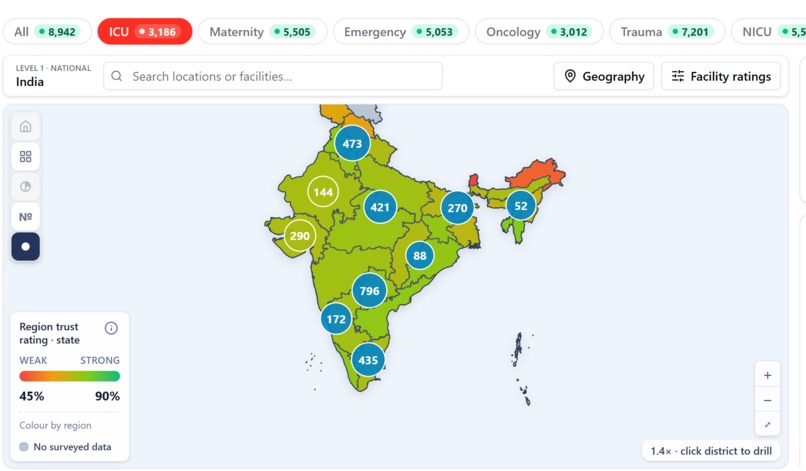
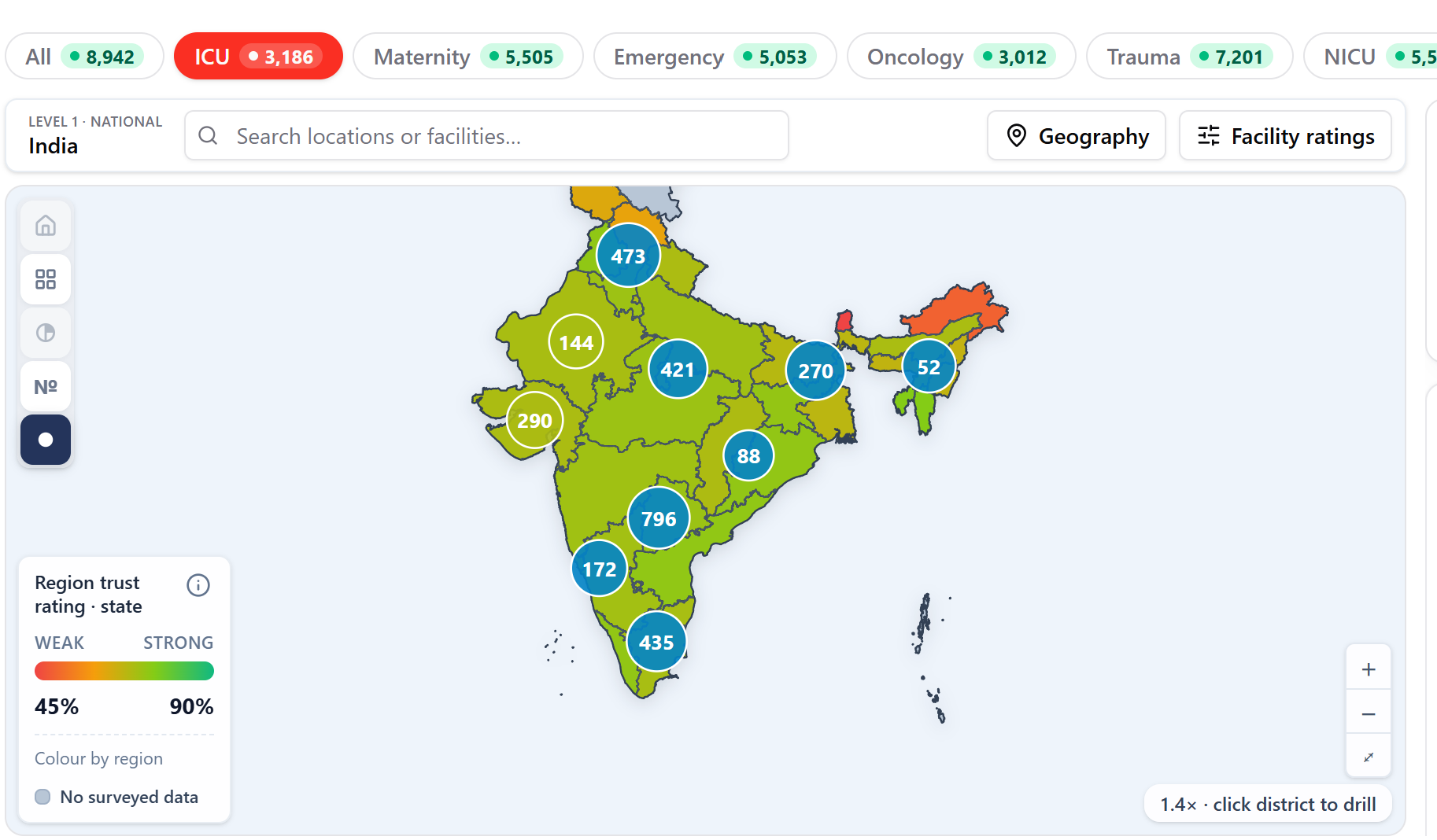
- Navigator + Beds & Population: Augmenting the map with population-weighted supply layered on trust scores to identify underserved areas.
- Medical Desert Planner: Creating composite gap scoring where weak trust and low beds overlap in the same district.
- Referral Copilot: Building tools to route patients to the nearest defensible facility once the capability is trusted.
- District Anomaly Radar: Scoring facilities gaming claims versus peers in the same region.

Log in or sign up for Devpost to join the conversation.