-
-

Initial prompt from bot for GIF processing
-
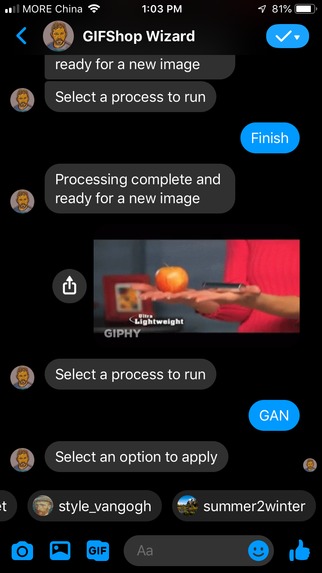
Sample quick reply options for CycleGAN
-

Sample quick reply options for style transfer
-

More sample quick reply options for style transfer
-

Quick reply options for selecting an effect to apply
-

The bot processing the GIF as the user waits for a response
-

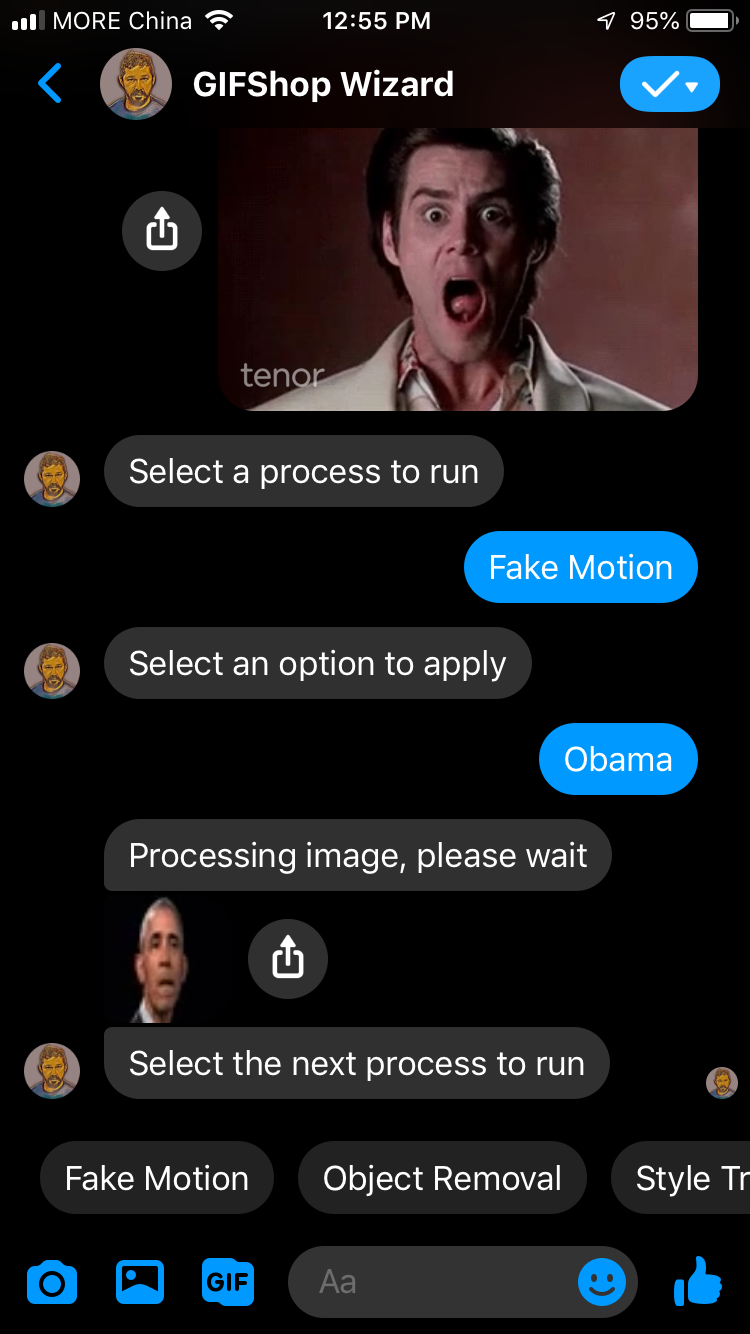
Quick reply options for selecting a source image to apply fake motion onto
-

Finish processing GIF
-

Quick reply options for next effect to apply after showing results of previous effect being applied
-
 GIF
GIF
Our logo was inspired by the very first test image we used with the "tripping" style mask









Inspiration
We felt that modern computer vision techniques such as style transfer and object removal were only accessible to those who are well versed in machine learning and have sufficient computing resources. The average person does not have access to either of these which means that it is difficult for an average user to try out these techniques on their GIFs or images. We want to alleviate both of these problems and provide a platform for users to easily manipulate their GIFs or images using techniques from computer vision and receive instant feedback.
What it does
GIFShop Wizard is a Messenger bot that applies computer vision techniques on GIFs and images sent by users.
The bot receives images or GIFs and prompts users for an image processing technique to apply using Quick Replies. The bot processes the image according to the user's specification and returns the processed image to the user. The image processing techniques currently supported include fake motion, object removal, style transfer, GAN, and segmented style transfer. We drive the dialogue flow with Quick Replies to minimize communication errors and keep the interaction as close to GIF-to-GIF as possible.
- Foreground Object Removal: Objects may appear in images that we wish to remove (i.e. photobombs). It takes long enough to photoshop objects out, but this is even more challenging for videos, where a manual process presents itself as a major obstacle. Thus we provide an object removal function, where we first detect what objects are available in the entire GIF, then return a list of detected objects for the user to selectively remove, and consecutively execute the removal of the specified object.
- Fake Motion: This vision function enables users to transfer the motion in their GIF into one of our available source images. Motions can be transferred to faces or body postures using the first order of motion model. For example, if a user has a GIF of a person talking or moving their head, this motion can be transferred to images of faces that we provide. The main prerequisite from the user is that their driving image is as closely cropped to the object (e.g. the face).
- Fast Style Transfer: When one GIF or meme is not enough, why not make more? To increase variations of the same content GIF, we can apply a style mask via neural style transfer. We trained on several style images to return style mask weights, such that when a user passes a GIF through, they can select from a variety of masks to apply onto their content image. To minimize latency is retrieving a stylized image, we pre-trained models rather than training on a new style each time (and thus this also means a user is not currently permitted from passing a custom style image to train on the spot).
- CycleGAN: Though quick to train and perform inference, style transfer applies the style to the whole image and not selectively. Therefore a generative adversarial network comes in handy, selectively applying the style of the target object onto the source object. For example, for the mask
horse2zebra, if a user passes in an image with a horse in it, CycleGAN would selectively stylize horses to possess stripes of a zebra. It should be noted thathorse2zebrameans that the GAN was trained on a pair of datasets (horse, zebra), but it does not mean that inference is limited to horse GIFs alone. In fact, users can pass in other images (e.g. people) and the stripes of a zebra can often be transferred as well, though just not as accurately as horse images. - Segmented Style Transfer: While CycleGAN is selective to specific objects, we use instance segmentation to target significant scene components and apply style transfer on those segments (i.e. scene-specific, not object-specific). We use FCN to detect instance segments, identify the largest one, extract that segment as an image, perform style transfer upon this image, and stitch it back onto the original image.
How we built it
We interface with the Messenger API and Webhooks using a Flask server and a custom bot interface. The models used in the various computer vision techniques are trained in PyTorch and TensorFlow.
Chatbot server
We built a convenience interface bot that takes in data from the server and automatically builds the correct POST request and sends it to the Messenger API. The actions currently supported include sending text, sending images, sending quick replies, and sending typing sender actions.
Vision functionality
- GIF extraction/stitching: When the user sends a GIF, we first parse GIF into its individual frames. We then apply the vision function selected by the user with its corresponding arguments and perform inference frame by frame. After all the frames are processed, we stitch the frames back together, compress the file to minimize latency, and send it to the user. Images are treated as a GIF with a single frame and are thus compatible with our bot.
- Fast style transfer: Based on the work of Johnson et al., we implemented their real-time style transfer architecture that uses a perceptual loss function to measure model perceptual differences between the content image and the style image. The loss functions are capturing semantic differences between the original image and stylized image through image classification, based on a 16-layer VGG network pretrained on ImageNet. Stylized images are generated from in-network downsampling and upsampling, and the resulting image is passed as an argument to the perceptual loss function. We store pretrained style mask weights, and when a user selects the quick reply button to select a specific mask, we perform inference on each frame.
- Segmented style transfer: For this function, we use fast style transfer as a boilerplate to perform style transfer. The main difference is that we first perform instance segmentation using Fully-Convolutional Networks to compute whether each pixel is semantically different from another, and thus return a list of segment masks. We detect the largest mask, obtain its pixel coordinates in an array, export it as an image with a single color fill background, perform fast style transfer upon this mask image, then transpose the pixel coordinates from this stylized mask image onto the original image, thus selectively performing style transfer onto a specific mask in the image.
- CycleGAN: For this image-to-image translation architecture (Zhu et al.), the generator network transcribes perturbations upon the source image with features from the style image. The discriminator network evaluates the class of the stylized image; if the label is identical to the ground truth label, then the image-to-image translation is a success. This is somewhat similar to the perceptual loss function in FST, but we instead use a discriminator network to measure perceptual differences.
- First order of motion: Based on Siarohin et al., our implementation of the First Order Motion architecture enables users to pass their GIF file as the driving image (image that contains the motion), and we provide the source images (images that users would want to transfer motion from their GIF into). The model works by first computing the first order motion representation by using a keypoint detector (identifying points of motion within a face/body). Using a motion network, we generate optical flow from the motion representations, and perform pixel transformations onto the source image based on the calculated flow of each pixel.
- Foreground removal: For this implementation, we remove foreground objects by performing YOLOv3 object detection, and sending the detected objects to users (objects based on those from the MSCOCO dataset). The object selected by the user via quick replies is passed as an argument to the object removal function, where we first apply a bounding box to the objects detected (if the object is equal to the one selected by the user), then remove pixels within the bounding boxes, then passing the resultant image to
pix2pixto fill the missing pixels (supposedly with a selection of the surrounding background pixels).
Challenges we ran into
Model inference for image processing usually takes a while. Since we are processing each GIF frame by frame, this means model inference for GIFs takes even longer. Because Messenger requires a response within 20 seconds, this meant that we needed to find a way to work around the constraint. We tackle this problem by continuing to process the image on the server and keeping track of the fulfillment status of the request rather than allow Messenger to timeout our process.
Because we implement several external computer vision architectures, we pull source code from multiple different projects. This means that they could potentially use different versions of PyTorch or TensorFlow. PyTorch and TensorFlow 1 turn out to be incompatible due to TensorFlow 1 using outdated libraries. To remedy the situation, we had to migrate all the TensorFlow 1 code to TensorFlow 2 code.
When we tried sending multiple GIFs to the bot, the GPU would sometimes run out of memory. To address this issue, we allocated memory carefully for each vision function and reduced parallelism to decrease the strain on our GPU.
Trying to maintain and update the state of the user is difficult as the Messenger API uses webhooks. This was solved by creating and implementing a clear organization and structure of the user flow.
Since only one of our members had a GPU, we had to distribute tasks carefully and separate our logic accordingly so that certain features could be tested independently.
Accomplishments that we're proud of
Since the Messenger API does not have an official Python API, we had to use a bot interface to send requests to the API from Flask. Since the bot interfaces we found were insufficient for our purposes, we wrote our own.
We were able to aggregate a bunch of different computer vision models from different projects and both make them compatible with each other and integrate them together into one coherent experience. To do this, we had to modify and rewrite a good amount of the source code and train our own models with our own source images.
What we learned
We got to experiment with various Messenger API functions such as Quick Replies and Sender Actions through Flask. We also got to play around with webhooks and use localhost tunneling to test our code. We learned how to modify existing bot interfaces and deprecated wrappers/libraries in order to customize them to our needs.
Furthermore, we got the chance to play around with various different computer vision models and tinker with different image processing techniques. It was a good opportunity to bring computer vision to the chatbot space, which has traditionally been dominated by NLP literature. We explored state-of-the-art models, made modifications to improve them and generate novel functionality, and exercised proper software engineering and documentation practices with the extended time granted by the competition.
What's next for GIFShop Wizard
There are several directions that we could have taken this project if we had more time to work on it.
Additional Techniques
Some additional things we would like to see as features in our bot include super resolution of GIFs and images, increasing the resolution of each image, and frame interpolation for GIFs, creating intermediate frames in between consecutive frames.
Custom Source Images
We would like to allow users to input custom source images for various features such as fake motion and style transfer. The main concern for implementing this feature is that in order to be able to apply an effect with a source image, the model must be trained with the source image which could potentially take a long time.
Video Processing
GIFs are essentially short videos so extending our bot to videos is not too difficult. The only concern with this is that it may take a long time to render on the server. Since Messenger expects a response within 20 seconds, this could be hard to implement depending on the length of the video.
Model Improvements
Even though our features produce pretty good results, they could always be improved. Some of the things we could do include running more iterations, finding other interesting source images, and investigating other state-of-the-art models.



Log in or sign up for Devpost to join the conversation.