
Inspiration
Every developer has been handed a codebase with no context. You open a file, see a function that looks wrong, and have no idea whether it's always been that way or whether three people tried to fix it last month and gave up. The context you need to understand why code is fragile doesn't live in the code itself — it lives in the Git history. Commit messages, author churn, repeated patches on the same lines. We wanted to build a tool that surfaces that history automatically and explains it in plain language, so a new developer can understand a codebase in minutes instead of months.
What it does
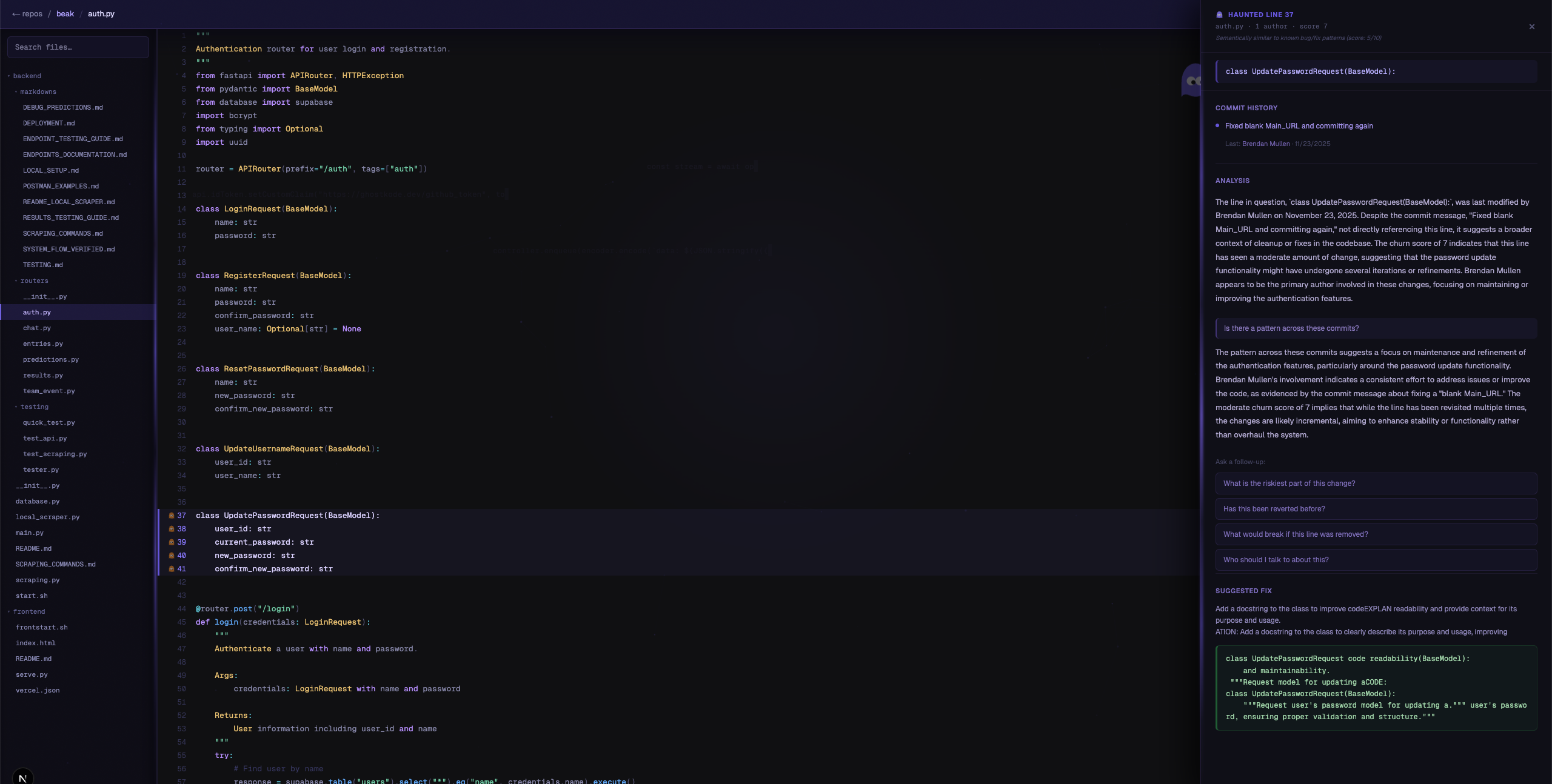
GhostKode analyzes the Git history of any file in your GitHub repos and identifies the most unstable lines — the ones with the most chaotic history. When you open a file and click Summon Ghosts, the app pulls blame data and commit history from the GitHub API, scores every line using a blend of semantic embedding similarity and keyword signals, and overlays ghost icons directly on the haunted lines. The brighter the glow, the more unstable the history. Clicking a ghost opens a side panel where an AI agent streams a forensic analysis — naming the real authors, quoting real commit messages, and explaining the pattern behind why that line keeps breaking. GhostKode then automatically streams a suggested fix. You can follow up with questions and the ghost maintains full conversation context across turns.
How we built it
How we built it Auth: Auth0 handles GitHub OAuth login. A Post Login Action forwards the GitHub access token into the session as a custom claim. Every API route extracts that token and makes GitHub API calls on the user's behalf — the ghost inherits your exact permissions. Built with @auth0/nextjs-auth0 v4 and Next.js 16 App Router. Repo and file access: /api/repos lists the user's repos via GitHub REST. /api/tree calls GitHub's Git Trees API with recursive=1 to get the full file structure in one request. /api/file fetches and base64 decodes file content server-side. Haunting engine: /api/haunt fires three things in parallel — GitHub's GraphQL blame API for line-level authorship (REST has no blame endpoint), the REST commits endpoint for file history, and a batch embedding call to OpenAI's text-embedding-3-small. Commit messages are scored against a reference corpus of instability patterns using cosine similarity, blended with a keyword signal and file churn bonus: (semanticScore × 0.6) + (keywordScore × 2) + fileChurnBonus. The frontend runs AST analysis before rendering to strip non-executable lines. Streaming analysis: /api/ask sends a forensics briefing — line content, authors, commit messages, churn score — to GPT-4o and streams the response back via SSE. A second request fires automatically in fix mode after the analysis completes. Follow-ups reconstruct the full conversation history on each request.
Challenges we ran into
GitHub's REST API has no blame endpoint. We had to switch to GraphQL mid-build to get line-level blame data, which required learning a different query pattern and response shape entirely.
Accomplishments that we're proud of
The semantic commit scoring approach is something we're genuinely proud of. Using embeddings to score commit messages against a reference corpus of instability patterns — rather than simple keyword matching — means GhostKode catches instability signals that are invisible to pattern matching. A commit that says "address edge case in token validation flow" scores high because it's semantically close to instability, even though it contains none of the obvious keywords. The streaming experience also came together well. Watching the ghost materialize its analysis token by token — naming real authors, quoting real commit messages — feels meaningfully different from receiving a static response. The SSE implementation is clean and the latency from click to first token is under 300 milliseconds. The Auth0 integration going beyond a login button was something we were intentional about from the start. The ghost agent inheriting the user's GitHub permissions through Auth0's delegated token model is a real agentic identity pattern, not just authentication for its own sake.
What we learned
Shipping something real in a few hours forces brutal prioritization. We cut vector databases, multi-file RAG, and several UI features that would have been nice but weren't core to the demo. The constraint made the product cleaner. We also learned that the GitHub GraphQL API is significantly more powerful than the REST API for this kind of use case — blame data, commit context, and author metadata are all accessible in a single structured query that would require multiple chained REST calls to replicate. On the AI side, the difference between a generic system prompt and a highly specific forensics briefing prompt is enormous. The ghost's output quality improved dramatically once we stopped asking it to "explain the code" and started asking it to "tell the story of what happened to this line."
What's next for GhostKode
IDE integration. The core haunting engine is model-agnostic and could run as a VS Code extension, surfacing ghost icons directly in the editor without leaving the development environment. Historical trend tracking. Storing churn scores over time would let GhostKode show whether a file is getting more stable or less stable sprint over sprint — turning it from a diagnostic tool into a continuous health monitor for the codebase.

Log in or sign up for Devpost to join the conversation.