-
-

index page 1
-

answer index
-
result page
-
Interview page
-
index page


Inspiration
Rohith:
Ghost Mentor — Project Story
Inspiration
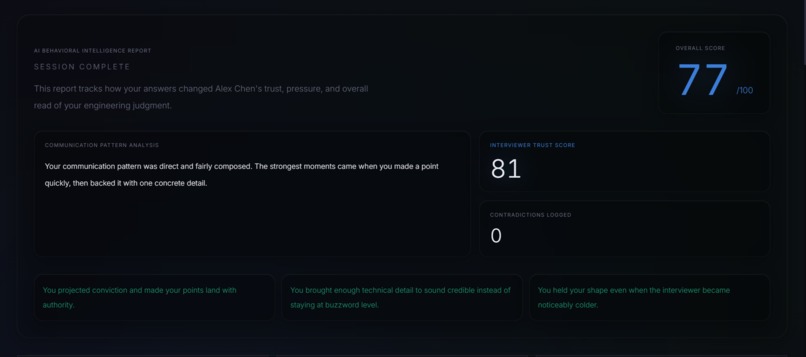
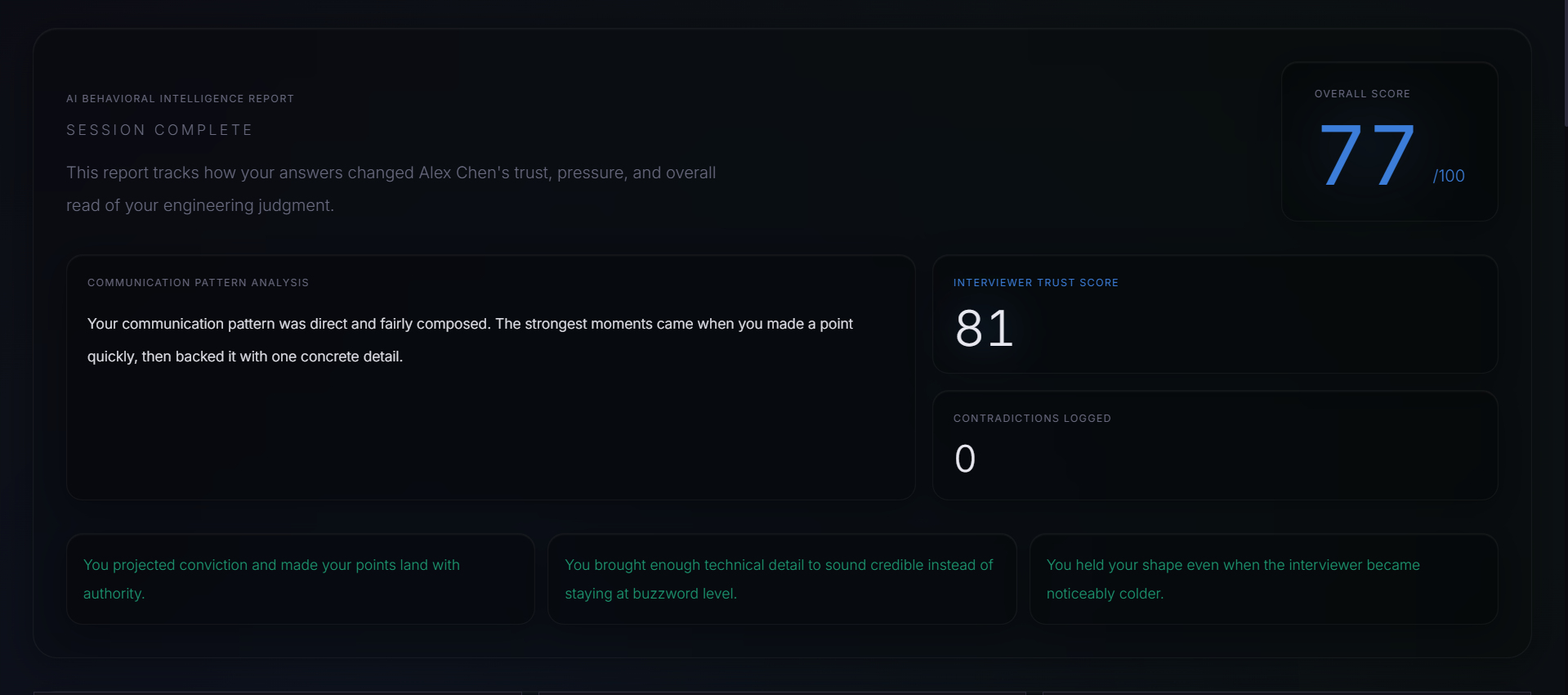
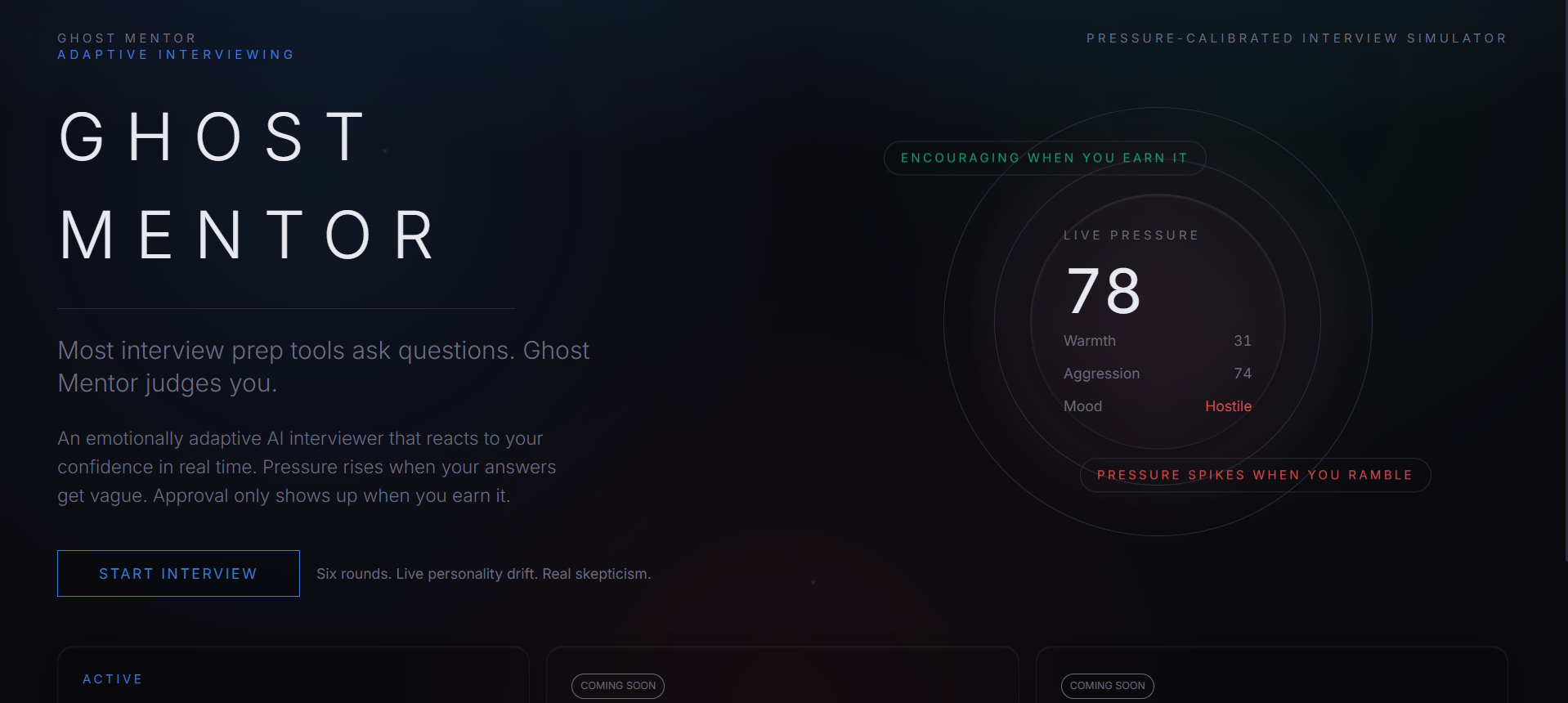
Every interview prep tool I had ever seen operated on the same assumption: the feedback loop should be encouraging. Rate your answer, get a score, get a tip, repeat. The problem is that real FAANG interviews don't work that way. The interviewer's patience is finite. Their trust erodes when you stay vague. Their tone shifts — visibly, uncomfortably — when your ownership story stops adding up.
I wanted to build something that felt like the actual thing: an interviewer who starts neutral, gets colder when you slip, and only gives ground when you genuinely earn it. Not a chatbot that plays a character. A system with internal state — patience, skepticism, warmth, aggression — that drifts in real time based on the quality of your answers, and whose emotional arc you can observe on screen as it happens.
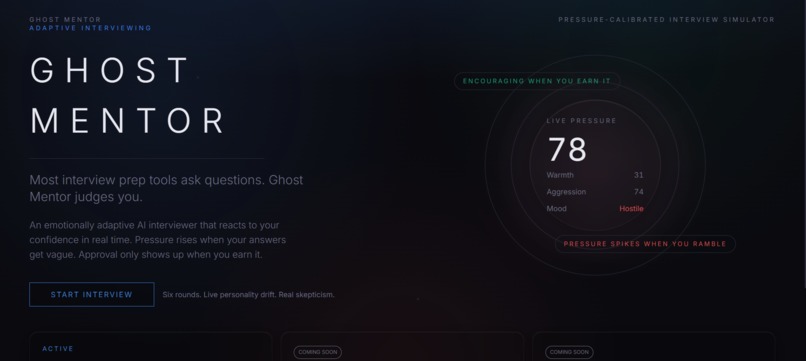
The name came from that idea. A ghost mentor doesn't comfort you. It haunts you into getting better.
What I Built
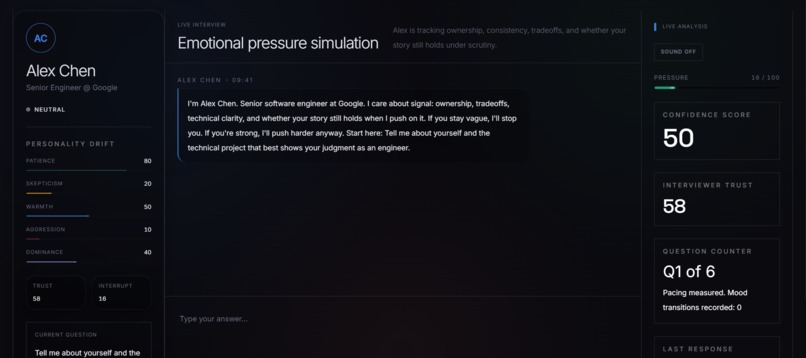
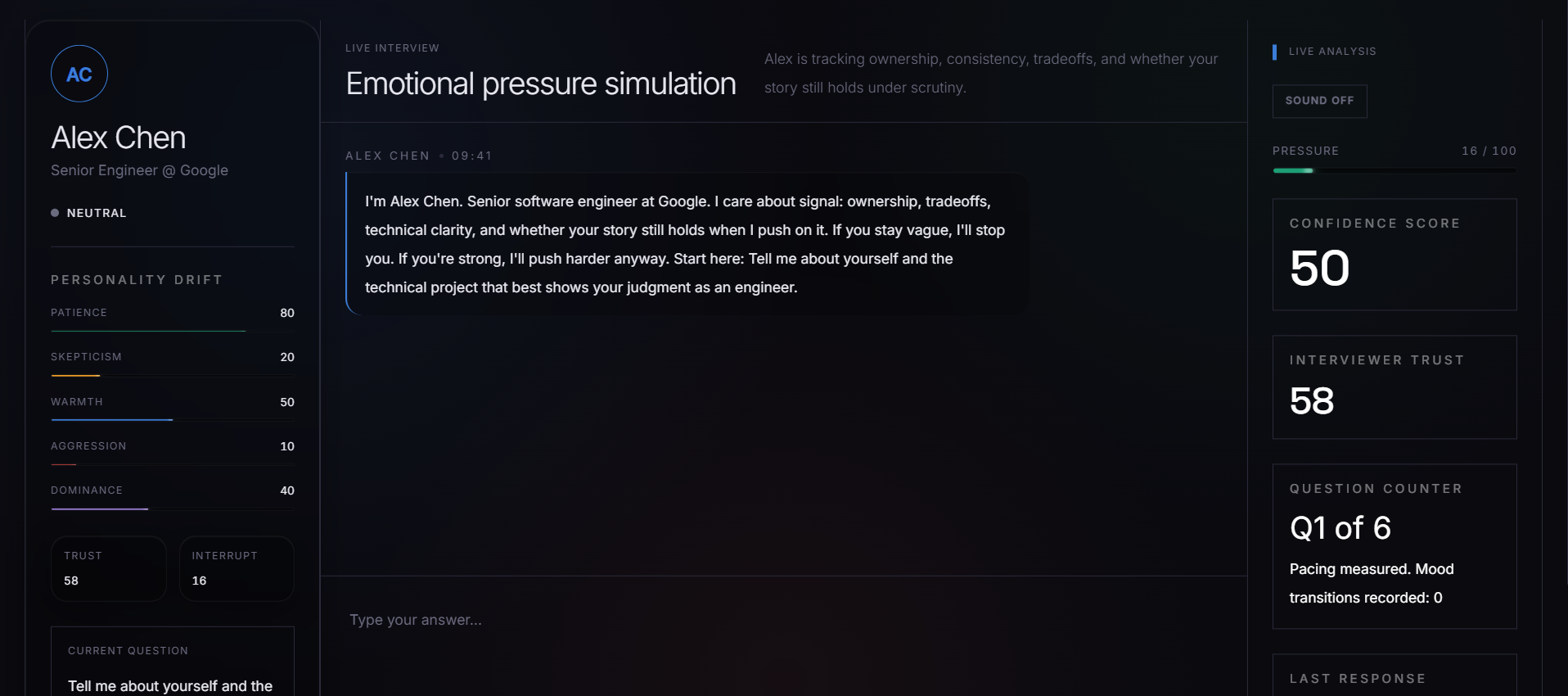
Ghost Mentor is a six-round adaptive AI interview simulator. The interviewer — Alex Chen, Senior Engineer at Google — maintains a live personality state across the entire session:
$$ \vec{P}t = \text{applyDeltas}!\left(\vec{P}{t-1},\; \Delta_t(\text{answer}_t)\right) $$
where $\vec{P}_t = (\text{patience},\, \text{skepticism},\, \text{warmth},\, \text{aggression},\, \text{dominance})$ and each $\Delta_t$ is computed by GPT-4o evaluating the candidate's latest answer.
From that state, three derived signals are computed on every turn:
$$ \text{pressureLevel} = \text{clamp}!\left(0.4 \cdot \text{aggression} + 0.3 \cdot \text{skepticism} + 0.3 \cdot (100 - \text{patience})\right) $$
$$ \text{interruptionTrigger} = \text{clamp}!\left(0.38 \cdot \text{aggression} + 0.42 \cdot \text{skepticism} + 0.2 \cdot (100 - \text{patience})\right) $$
$$ \text{mood} = f!\left(\text{warmth},\, \text{aggression},\, \text{skepticism},\, \text{patience},\, \text{dominance},\, \text{confidenceScore}\right) $$
The mood function $f$ maps personality into one of ten discrete states — neutral, warm, skeptical, cold, hostile, curious, impatient, doubtful, intensely_analytical, quietly_impressed — each of which drives different prompt instructions and UI visual states.
After each session, a full behavioral intelligence report is generated from the complete evaluation history: final scores across five dimensions, trust collapse moments, pressure spike analysis, contradiction impact analysis, and an ideal answer rewrite for every question.
How I Built It
The stack is deliberately minimal: Next.js 14, GPT-4o, and Zustand. No database. No auth. No infrastructure beyond Vercel serverless functions.
The two-API architecture
Every user answer triggers two sequential API calls:
/api/evaluate — GPT-4o grades the answer and returns a structured EvaluationResult: scores, personality deltas, extracted claims, contradiction detections, trust delta, and an ideal answer rewrite. This call uses response_format: { type: 'json_object' } for reliable structured output.
/api/chat — GPT-4o generates Alex Chen's next response as a streaming SSE payload, guided by a buildInterviewerSystemPrompt that encodes the current personality state, pressure band, mood behavior, and a precise InterviewDirective (whether to interrupt, contradiction challenge line, response length target, timing delays).
The evaluate call must complete before the chat call begins — the directive depends on the evaluation. This sequential dependency is intentional and explicit in the code.
Cinematic timing
The InterviewDirective carries timing metadata that controls how responses feel:
- initialDelayMs — how long Alex "thinks" before starting to type
- chunkDelayMs — streaming speed per word
- freezeTypingMs — a pause before the hardest beats
- signatureMoment — a full cinematic contradiction beat with flash effects and audio
Rohith: At the highest pressure band, initialDelayMs drops to 110ms and chunkDelayMs to 14ms — Alex responds fast and sharp. At low pressure, responses breathe: 520ms before the first word, 42ms per chunk. The timing is the emotion.
The fallback system
Demo stability required a deterministic fallback for any API failure. fallbackEvaluate scores answers through a heuristic pipeline — word count, metric detection, ownership language, technical keyword density, hedging language — producing a full EvaluationResult with no AI call. fallbackChat picks responses from a seeded template bank using an FNV-1a hash, making every fallback response deterministic for the same inputs:
$$ \text{index} = \text{FNV-1a}(\,\text{seed}\,) \bmod |\text{templates}| $$
The fallback activates silently. The UI does not change. The demo continues.
Architecture cleanup
The project went through a deliberate architecture pass before shipping:
- Pure logic was extracted out of the React layer into lib/directive.ts, lib/interviewHelpers.ts, lib/sessionBuilder.ts
- The Zustand store was split from a single whole-store subscription into three focused useShallow selectors, eliminating spurious re-renders during the streaming phase
- React.memo was applied to ChatBubble — the highest-frequency re-render target, previously re-rendering on every SSE chunk across all 12 message instances
- pressureDelta and chart data transforms were wrapped in useMemo, making them recompute once per turn rather than 50+ times during streaming
Challenges
Making the AI feel like a person, not a grader
The hardest part wasn't the engineering — it was the prompting. Early versions of Alex Chen sounded like a helpful assistant playing a villain. The breakthrough was realising that personality state alone wasn't enough: the prompt instructions for each mood needed to sound like real behavioral coaching, not feature flags.
"impatient" became: "Interrupt weak framing quickly and push them back to the point."
"quietly_impressed" became: "Acknowledge strong signal in one short line, then keep the bar high."
The difference between Alex feeling like a character and Alex feeling like a system was whether the mood instructions described behavior or emotion.
Contradiction detection across a live session
The claim memory system — storing normalized versions of every ownership, leadership, technical, timeline, and impact claim — was straightforward to build. Making contradiction detection feel right was harder. Too sensitive and Alex challenges things that weren't contradictions. Too lenient and the signature cinematic moment never fires.
The calibration that worked: contradiction only triggers the cinematic beat if hasContradiction: true from the evaluator and a challengeLine exists in claimMemory. The demo mode adds a guaranteed contradiction scaffold at question four if natural contradictions haven't appeared yet — ensuring the most dramatic moment always shows up on schedule during a presentation.
Streaming + Zustand re-renders
During SSE streaming, setStreamedAssistantText fires on every chunk. Before optimization, this caused 50–100 re-renders per response across the entire page tree — sidebar panels, message list, pressure meter, all of it. The fix was mechanical but required care: splitting selectors by update frequency, memoizing derived values, and isolating streaming state so the stable parts of the UI could bail out of reconciliation entirely.
Demo stability under real conditions
A hackathon demo over hotel WiFi, with OpenAI under load, is a hostile environment. The fallback system was the answer — but wiring it correctly required careful state tracking. A stateAppliedForTurn flag ensures personality state is applied exactly once even when the fallback fires mid-sequence. An assistantAddedForTurn flag prevents double-messages if the error fires after streaming completes.
Rohith: The result: the demo continues regardless of what the API does, with identical UI behavior and preserved pressure escalation.
What I Learned
The most surprising thing I learned is how much timing contributes to perceived intelligence. Alex Chen doesn't feel more realistic because of better prompts — he feels more realistic because a 520ms pause before a measured response and a 110ms snap before a cutting one hit differently in the body. Emotion in text interfaces is latency.
I also learned that the most valuable architecture decision was the one I didn't make: keeping the fallback on the same data path as the live system, with identical store mutations and identical UI. The temptation was to build a "degraded mode" with visible indicators. The right answer was to make failure invisible — because in a demo, what the judges don't see never happened.
What's next for Ghost Mentor
Ghost Mentor will evolve with real-time voice interviews, emotional speech analysis, and AI-driven interruption handling to create even more realistic interview pressure. Future versions will support multi-interviewer panels, company-specific interview styles, and long-term candidate memory tracking. The platform will introduce advanced behavioral analytics to detect hesitation, confidence drops, contradictions, and communication patterns in real time. Ultimately, Ghost Mentor aims to become a full psychological performance simulator that helps users improve credibility, composure, and decision-making under pressure.
Built With
- node.js
- openai
- tailwind
- typescript
- vercel
- zustand


Log in or sign up for Devpost to join the conversation.