-
-

app's logo
-
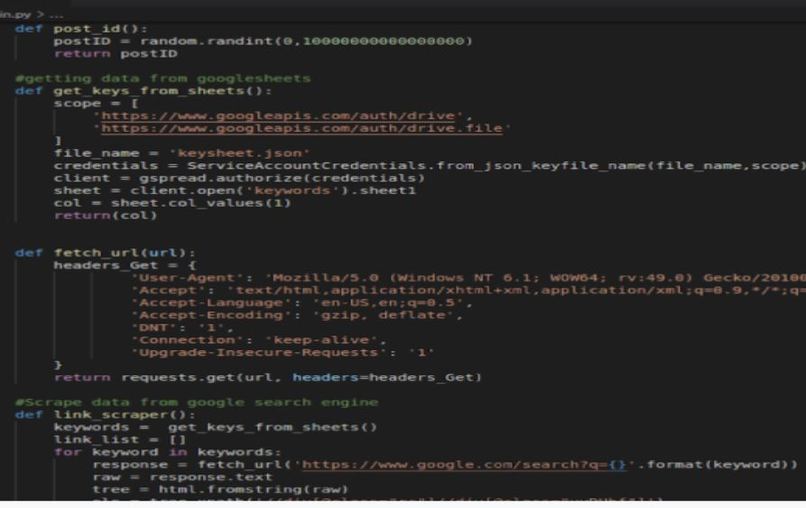
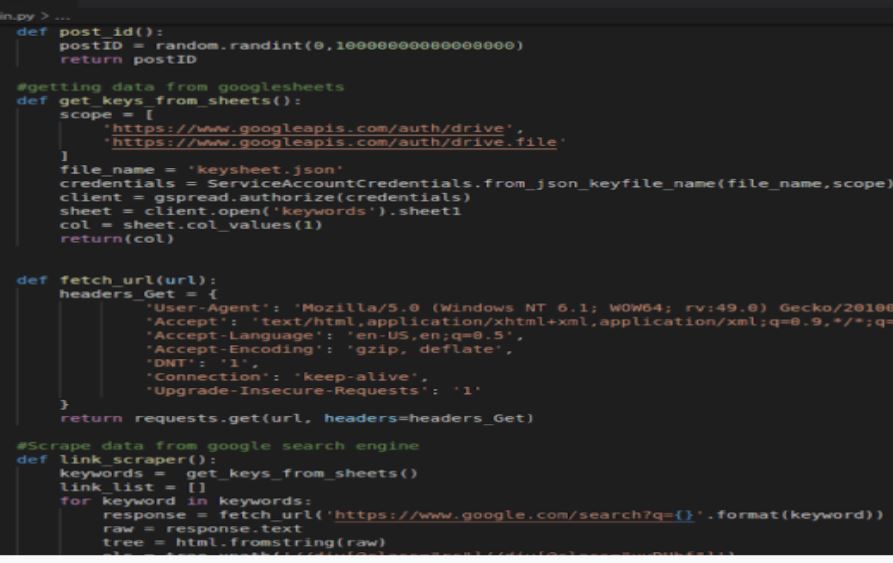
part of the code in scraping websites
-
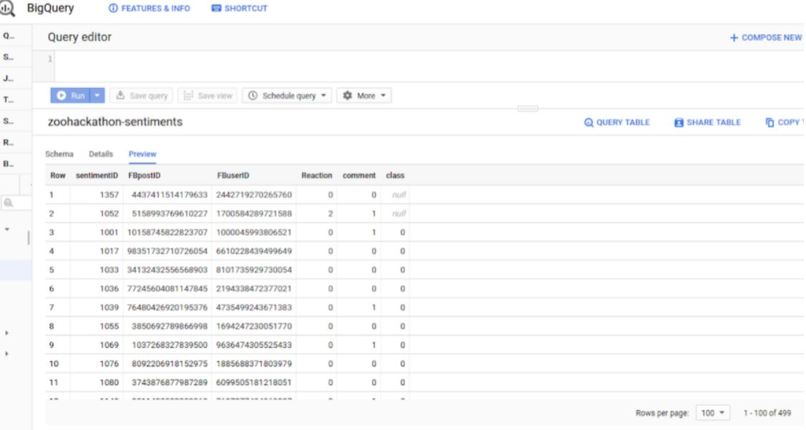
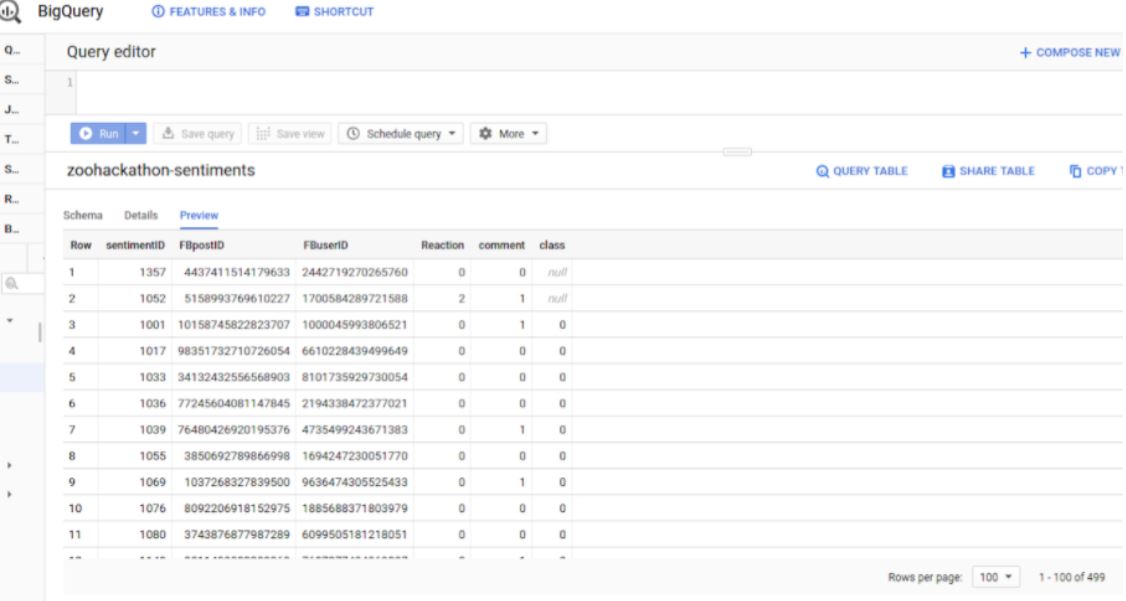
part of the dataset stored in bigQuery datawarehouse in google cloud
-

list of classification of users and their sentiment scores
-
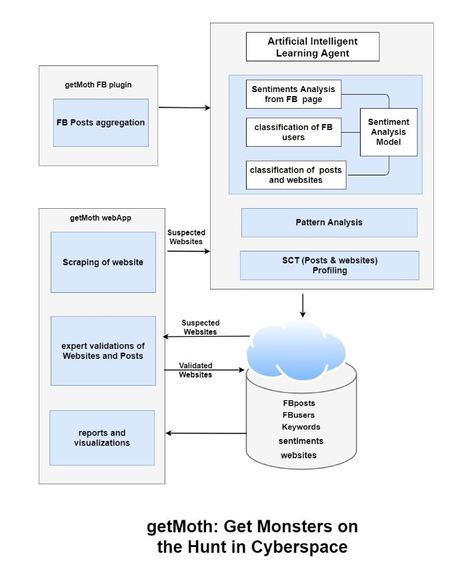
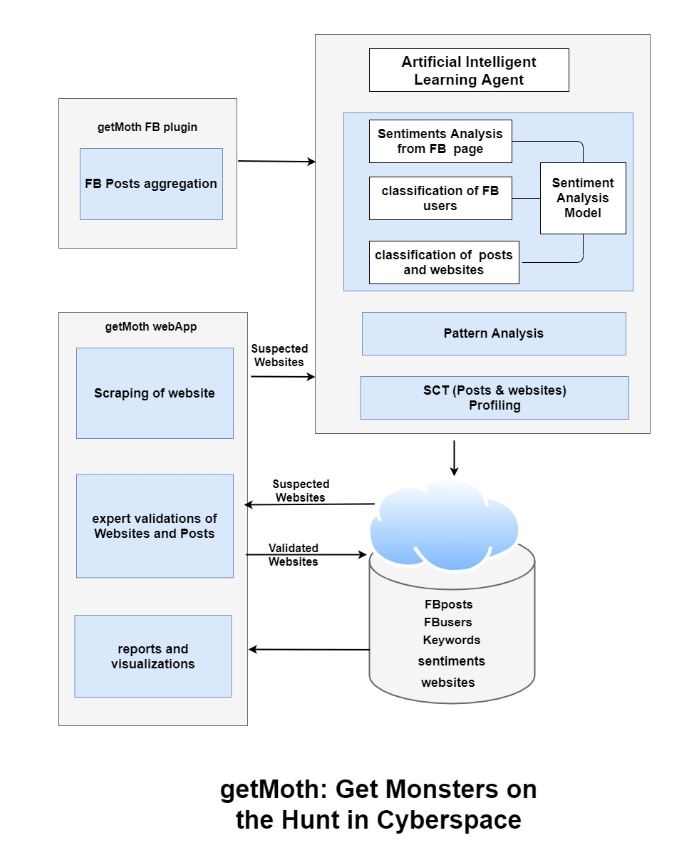
System Architecture
-
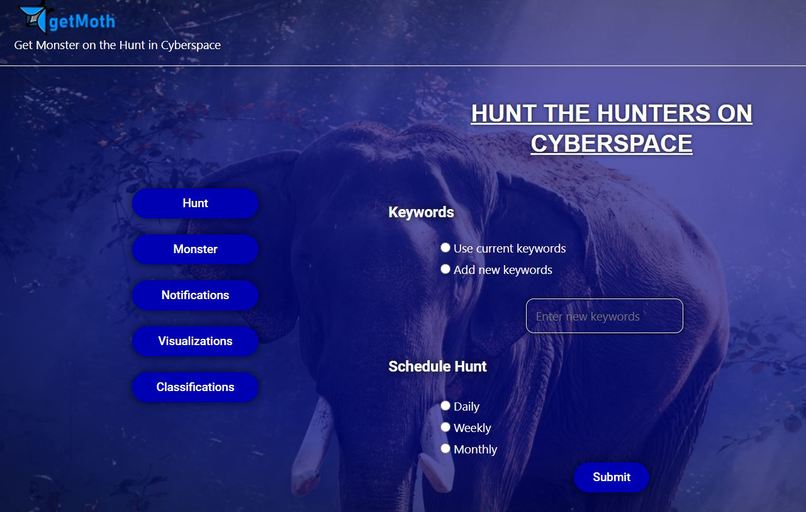
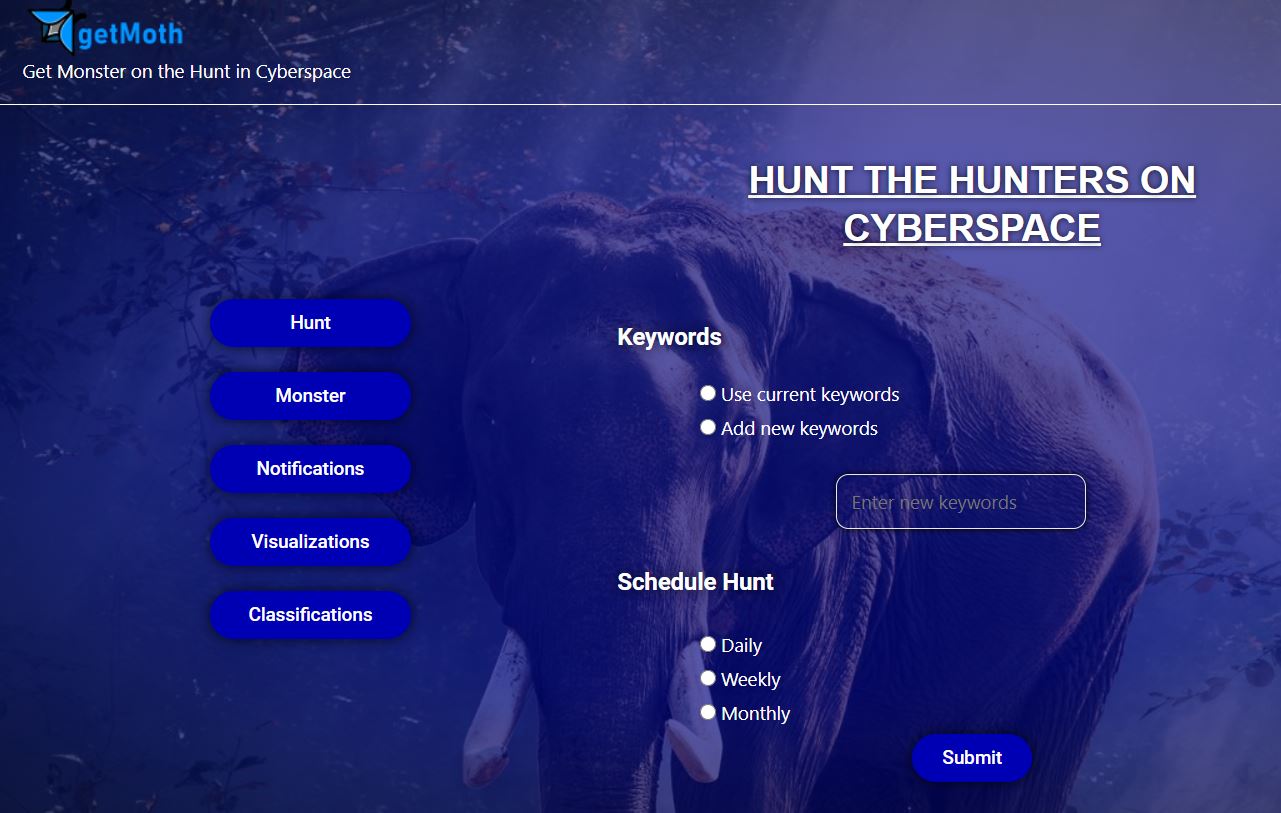
page of triggering the event of scraping website
-

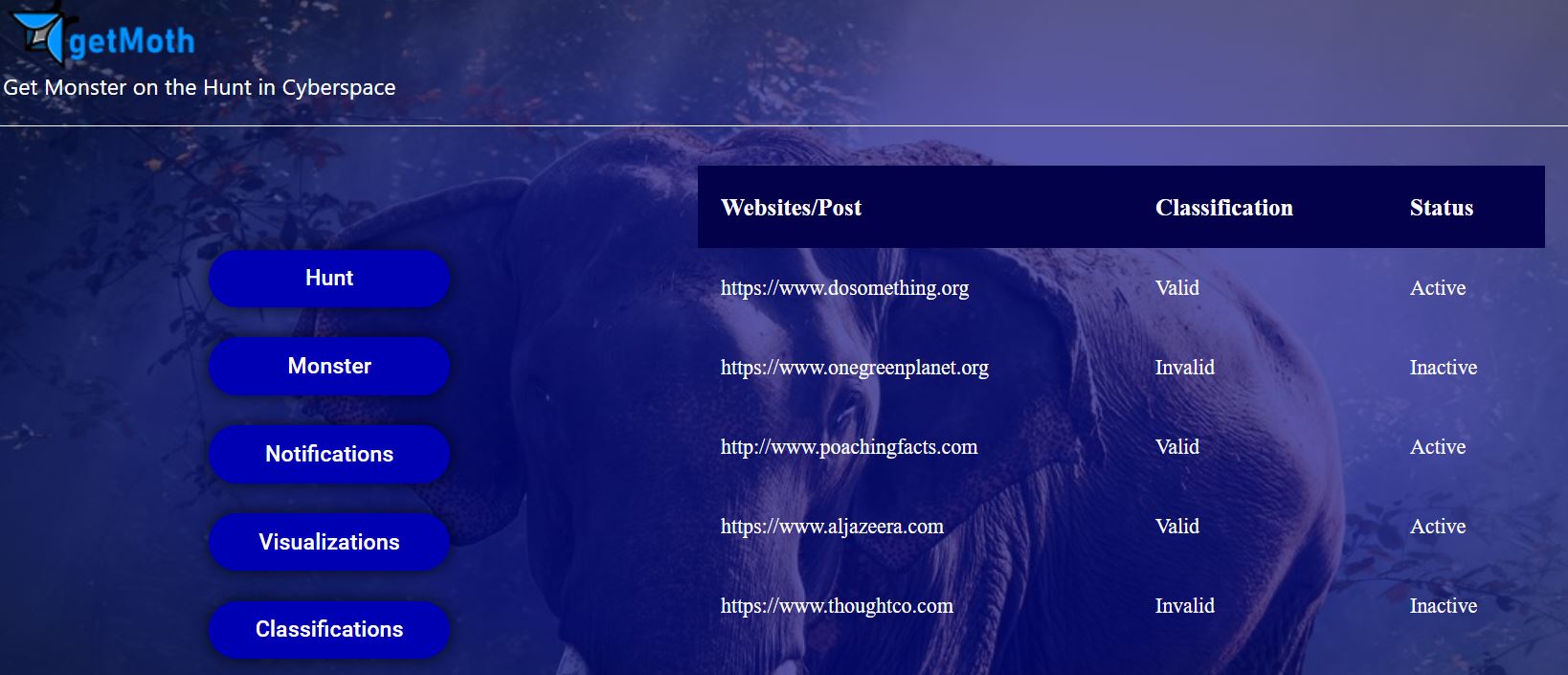
List of currently scraped websites
-
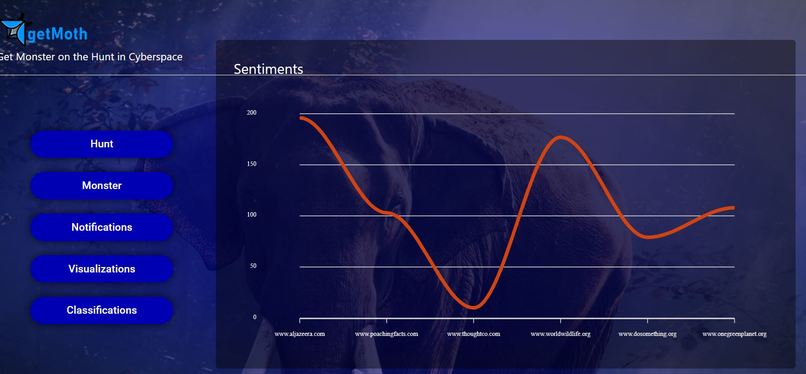
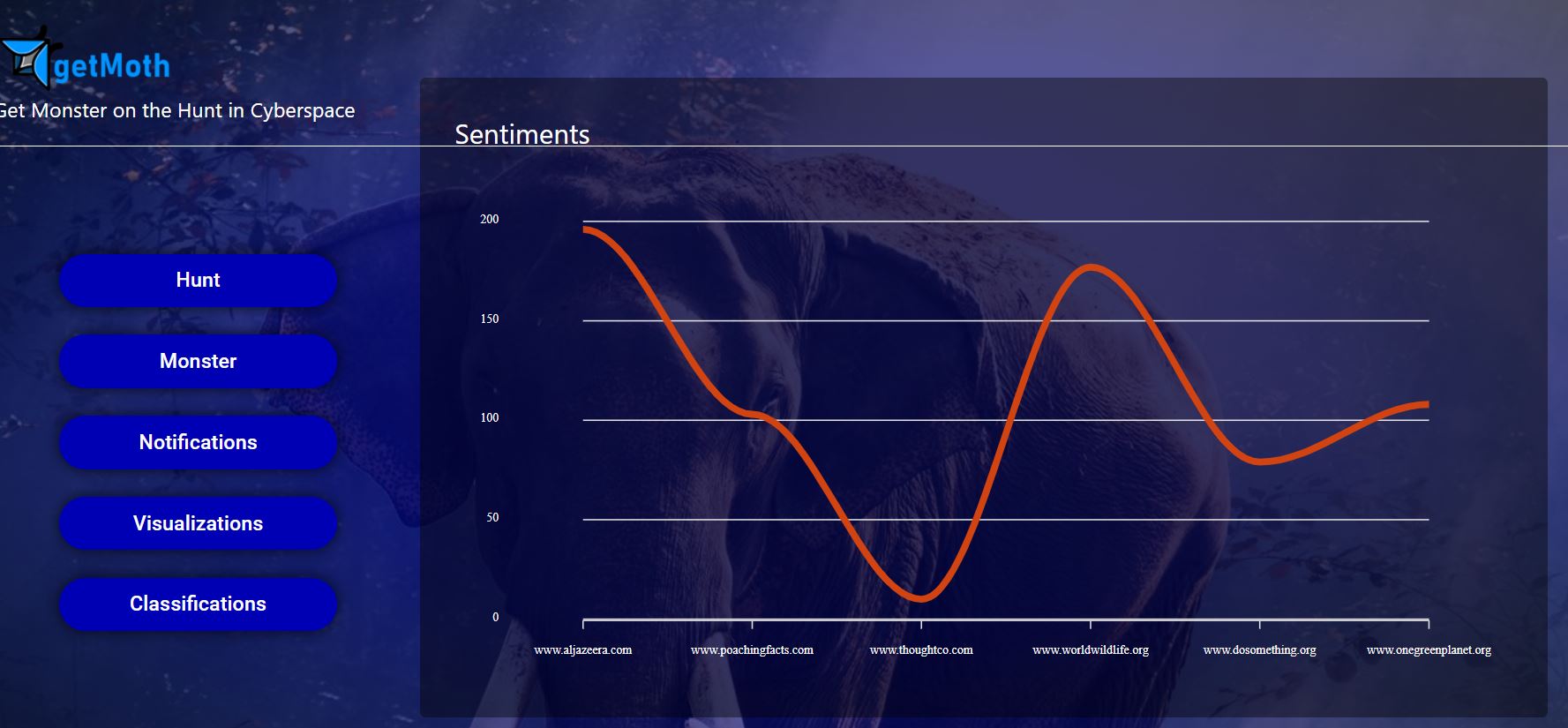
one of the visualizations
-
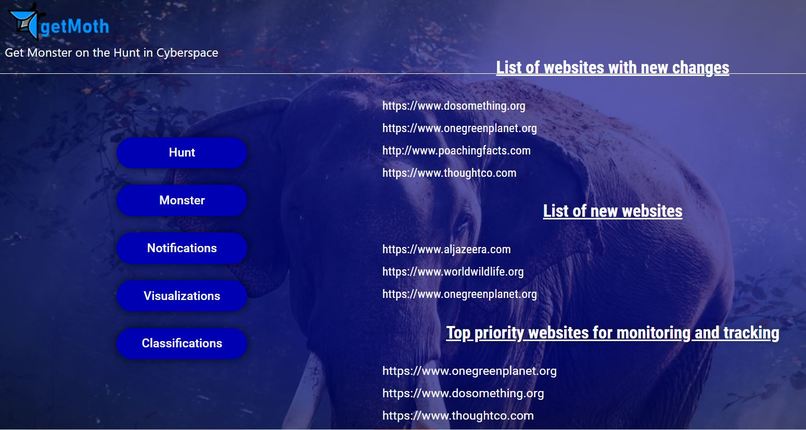
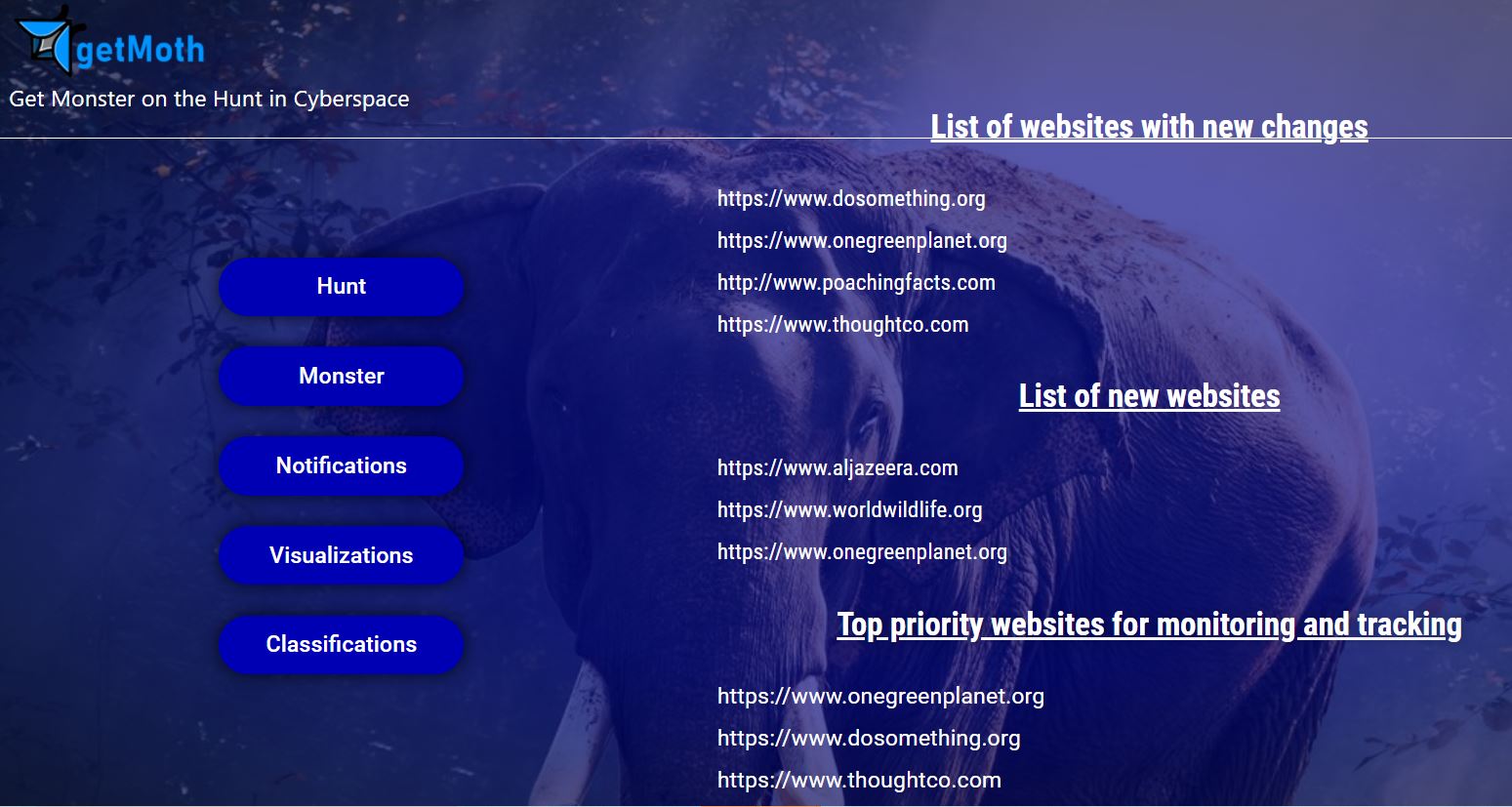
List of websites with new changes, list of newly added websites, and list of top priority posts and websites for tracking and monitoring


Inspiration: we are moved and saddened with a lot of news about online animal trafficking that became more prevalent during this time of pandemic.
What it does:
getMoth is an Artificial Intelligent and Content Aggregator application. It scrapes websites and aggregates posts from different pages, users, public groups, and marketplace into our FB page and performs sentiment analysis. It systematically identifies and extracts comments andr emoticons from facebook posts in a page, group, or market place. A sentiment analysis is performed on the gathered reactions to each post and scale the gravity of posts that need quick response from the law enforcement agency. The developed Artificial Intelligence (AI) will continuously learn from crowdsourcing in getting the sentiments on the posts.
How I built it:
we develop scraper using python and code in visual studio, AI engine was developed using Random Forest Algorithm (RF) and we also utilize nimbus. we created a dummy dataset to train our model for the sentiment analysis. We used wordpress for user interface of the web application.
Challenges I ran into:
communication with groupmates especially that face to face meetings are not yet allowed in our location. And also, internet connectivity problems.
Accomplishments that I'm proud of:
we were able to design an innovative solution that helps to prevent animal trafficking
What I learned:
open communication with team mates can help to do the tasks much faster and better
What's next for getMoth:
will integrate predictive analytics


Log in or sign up for Devpost to join the conversation.