-
-
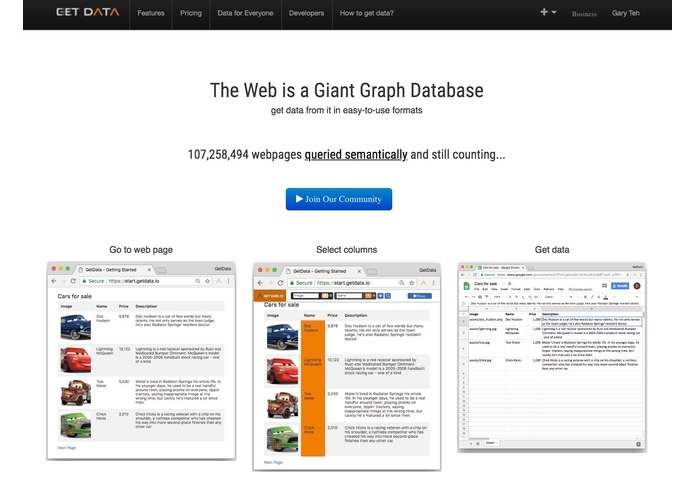
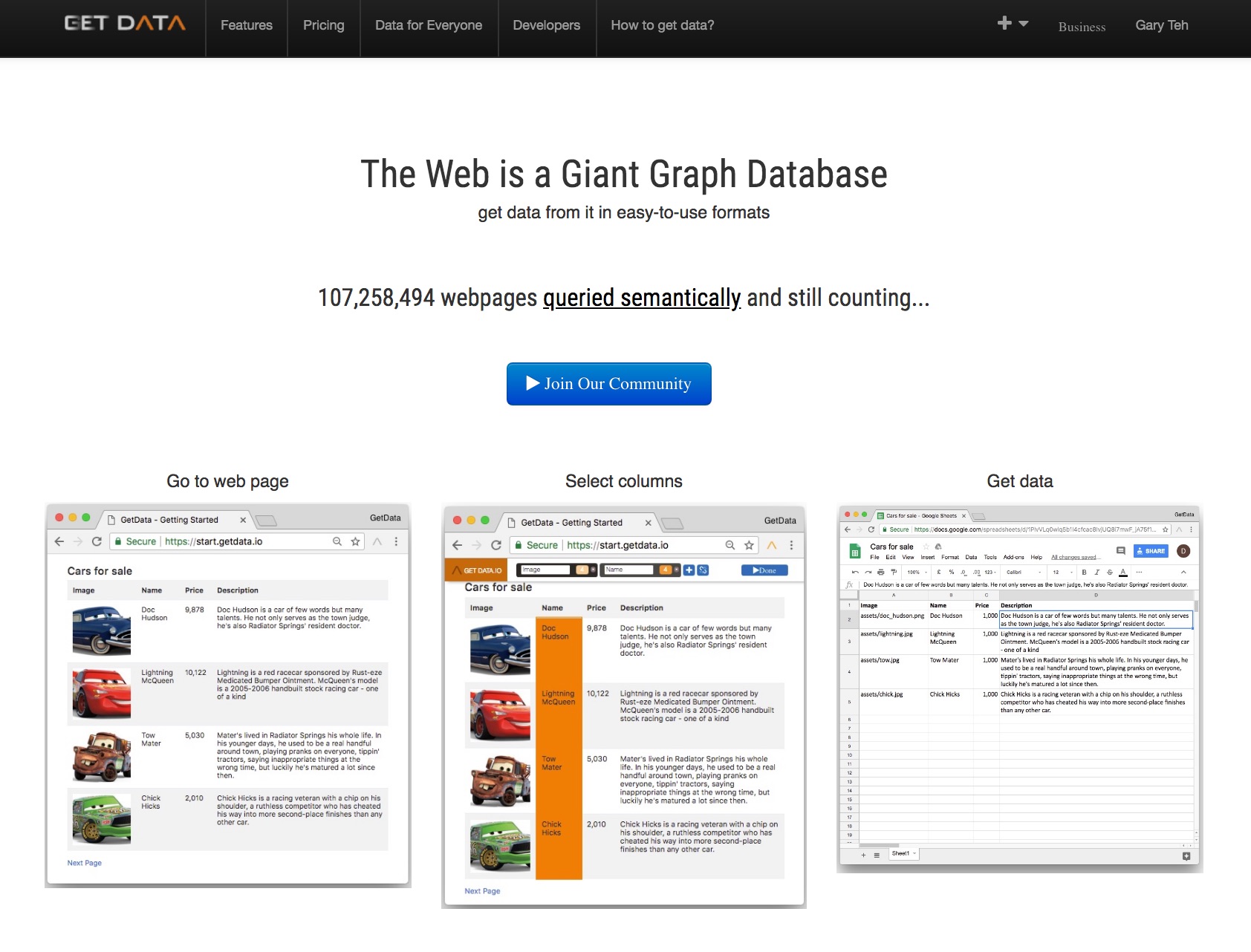
The query language for the web which turns it into a giant graph database
-
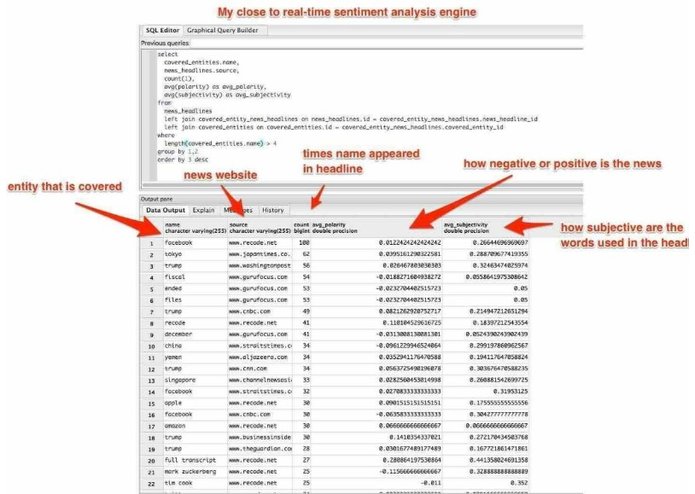
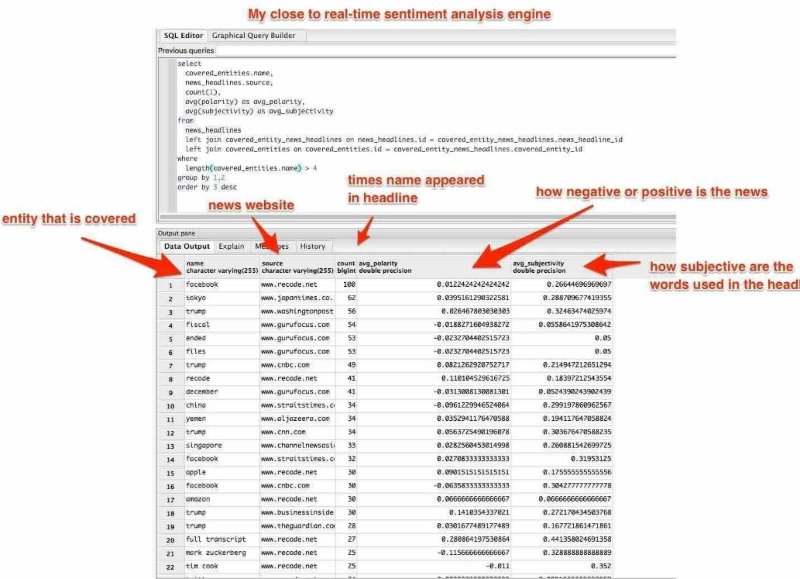
Worldwide news sites sentiment analysis supported by this semantic query language
Inspiration
We want to turn the Web into a properly functioning Giant Graph Database of Human Knowledge.
The current problem is that its query language is missing. We want to solve this problem by helping define a turing-complete query language as well as implement the decentralized engine which will interpret and gather the data.
// A query to fetch cast of Gattaca from IMDB and their date of birth from Google.com
{
"engine": "nokogiri",
"client_version": "4.0.20",
"origin_url": "https://www.imdb.com/title/tt0119177/fullcredits",
"columns": [
{
"col_name": "cast_name",
"dom_query": "table.cast_list tr td:nth-child(2).itemprop a span.itemprop",
"options": {
"origin_url": "https://www.google.com/search?q={{cast_name}}+date+of+birth",
"columns": [
{
"col_name": "date_of_birth",
"dom_query": "div[role='heading'][aria-level='3'].HwtpBd.kno-fb-ctx div:nth-child(1)"
}
]
}
}
]
}
What it does
Our project allows users the ability to create a recipe for the data they want from this giant graph database without having to worry about the underlying implementation details. The interpretation of the recipe and gathering of data is handled by a decentralized engine that is ran by our community members.
How I built it
I built the infrastructure from day one to be decentralized. I followed key design principles to ensure there was clean separation between the schematic declarations and the actual code which handles the gather gathering.
Challenges I ran into
Scaling the crawlers across a distributed network while tackling bottlenecks and weird corner cases due to implementation choices made by various developers for their own sites.
Accomplishments that I'm proud of
So far, the current iteration of our query language has allowed us the ability to query for data from more than 100 million webpages.
What I learned
While it takes a lot more time than necessary solving a problem at the fundamental level inevitably yields a clean and simple solution.
What's next for GetData.IO
Further decentralizing the engine to have it running off the blockchain instead of a queueing system.

Log in or sign up for Devpost to join the conversation.