-
voting system for audience
-
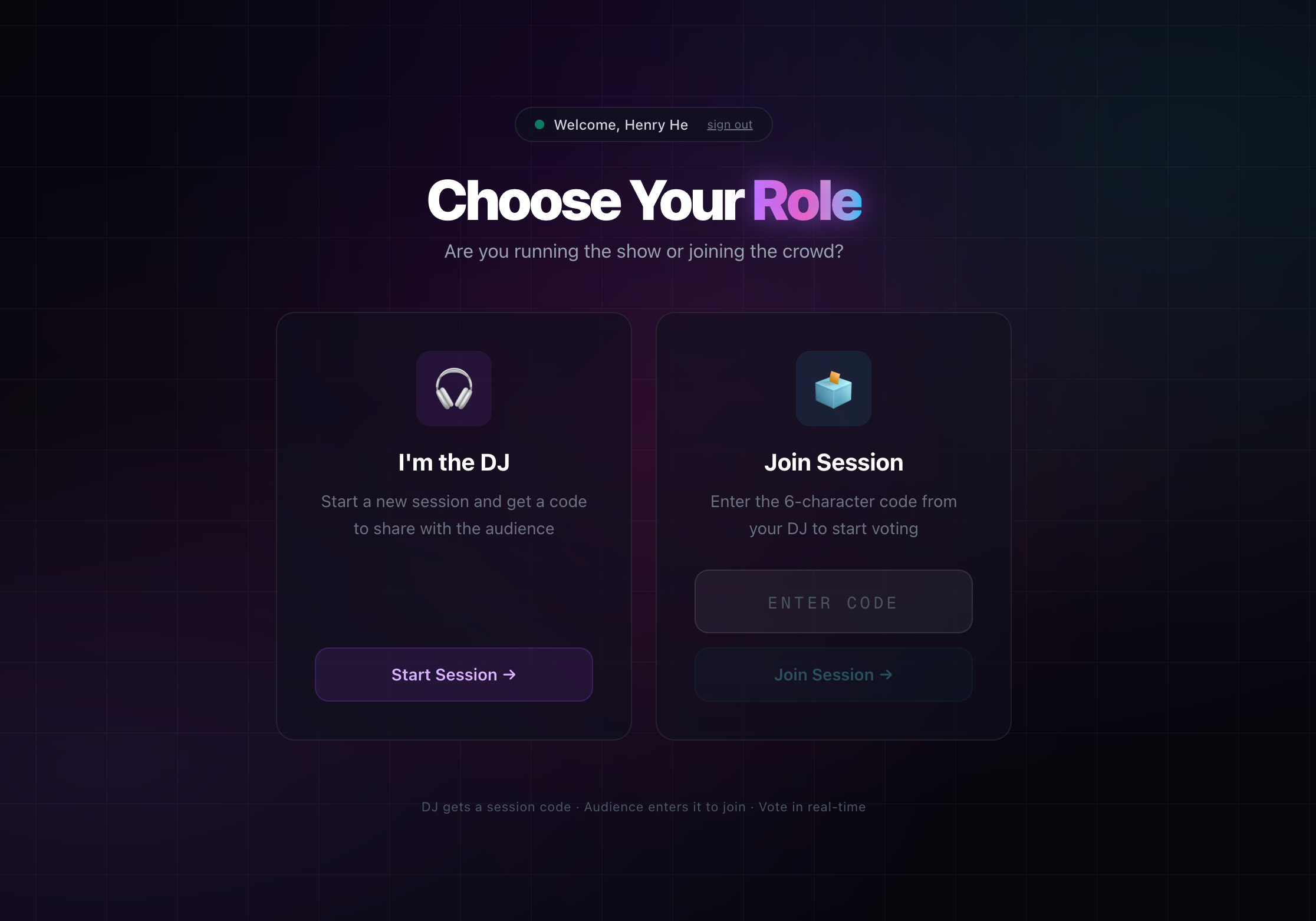
role selection page
-
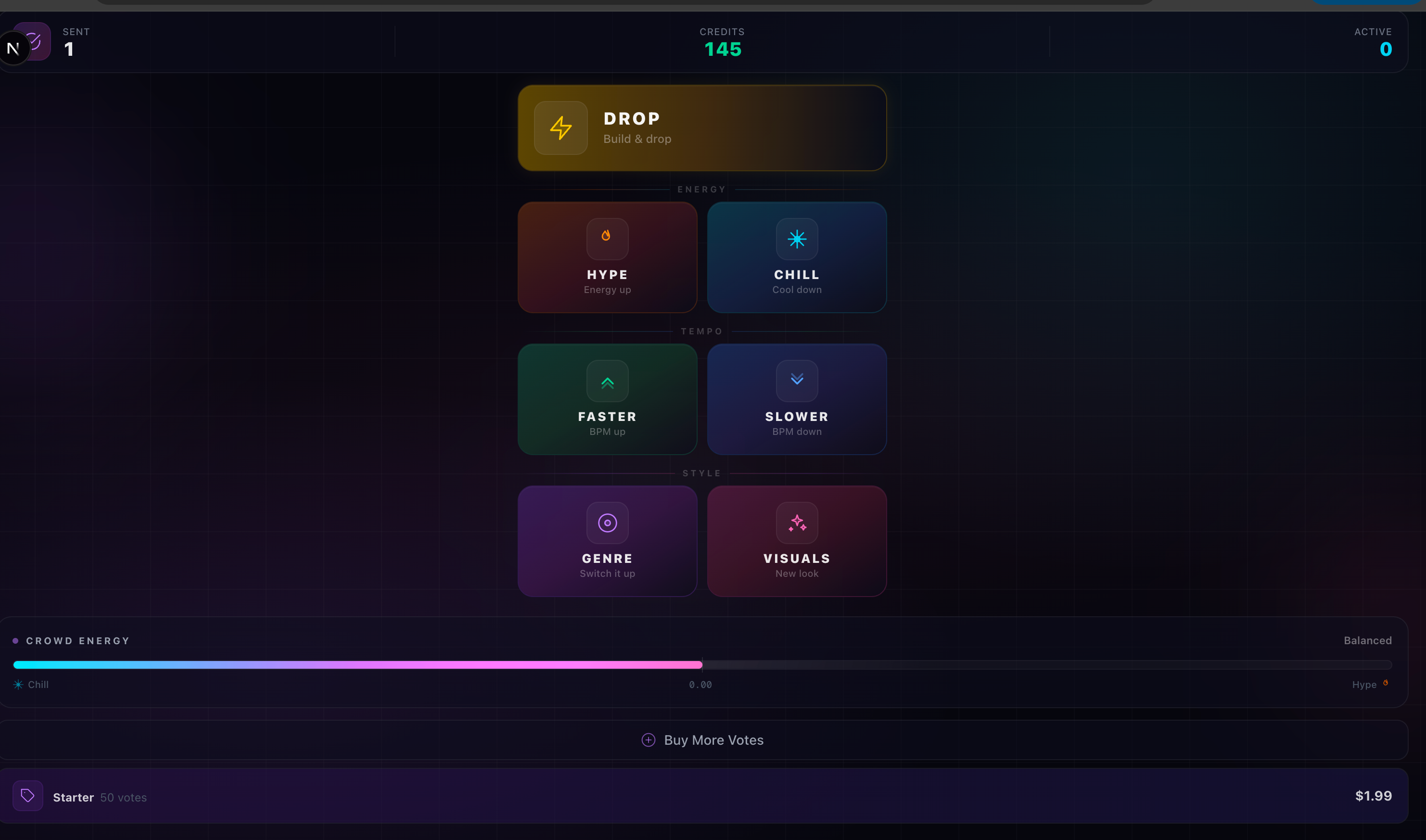
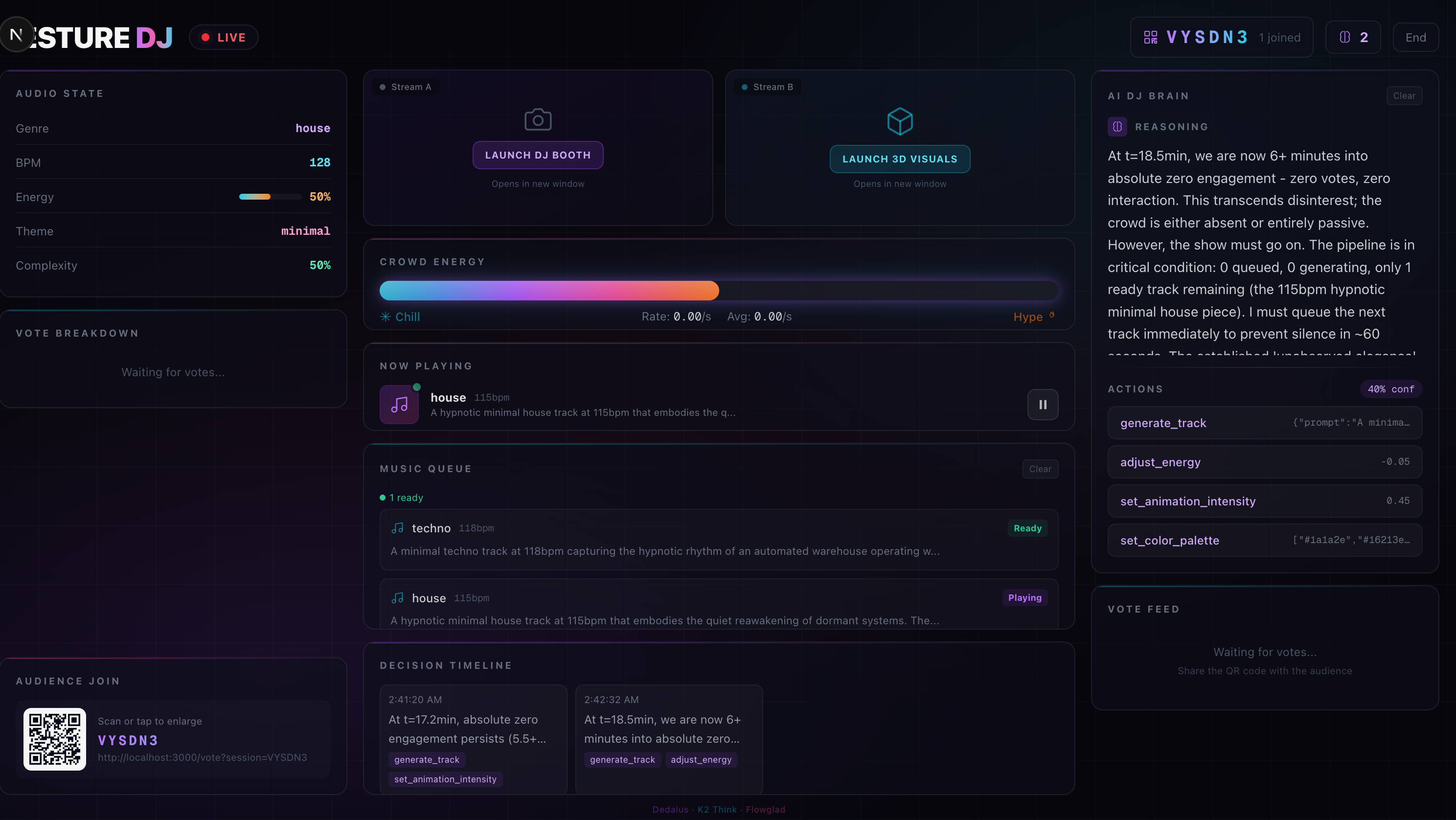
DJ dashboard
-
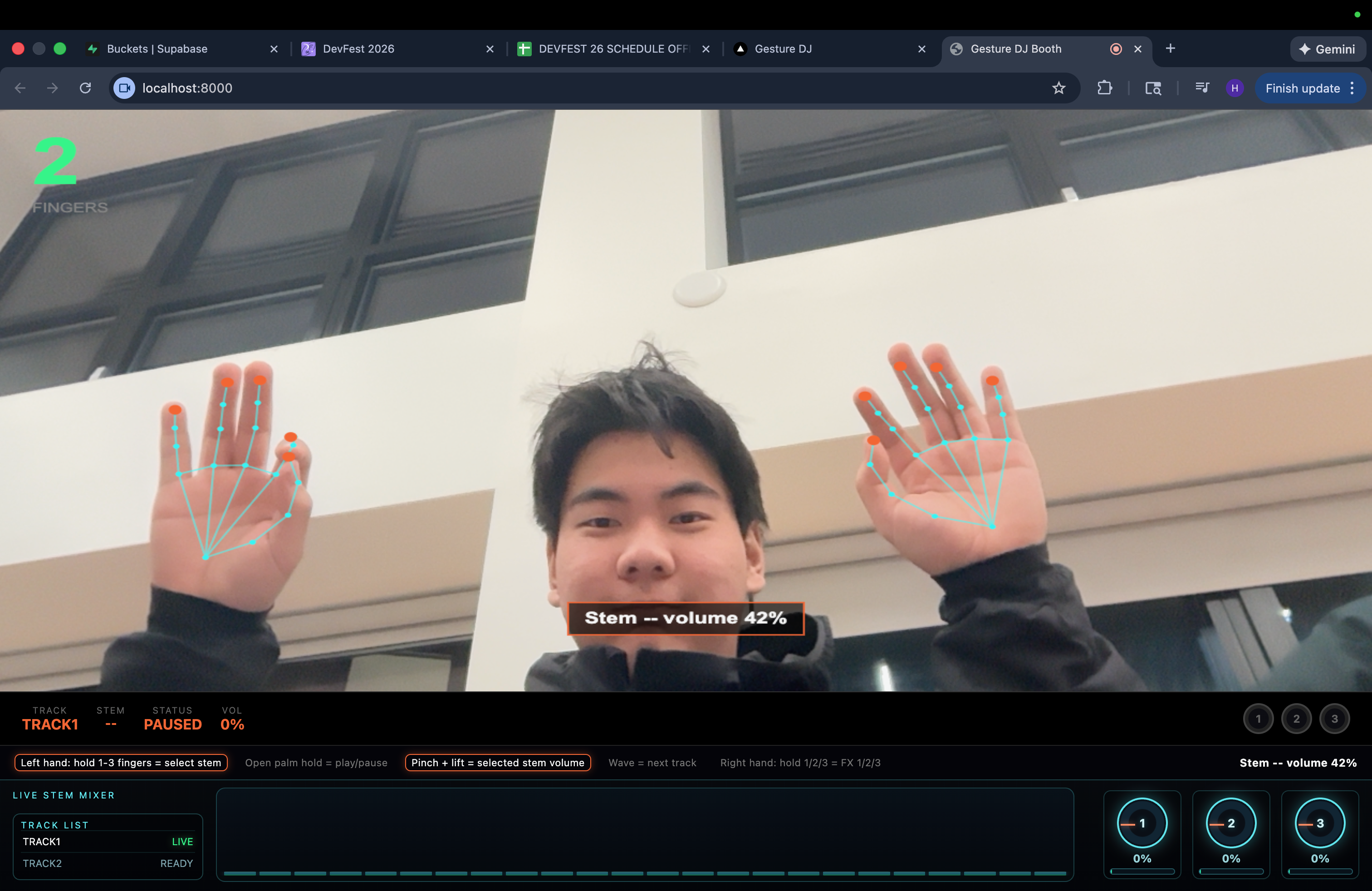
GestureDJ Computer Vision
-
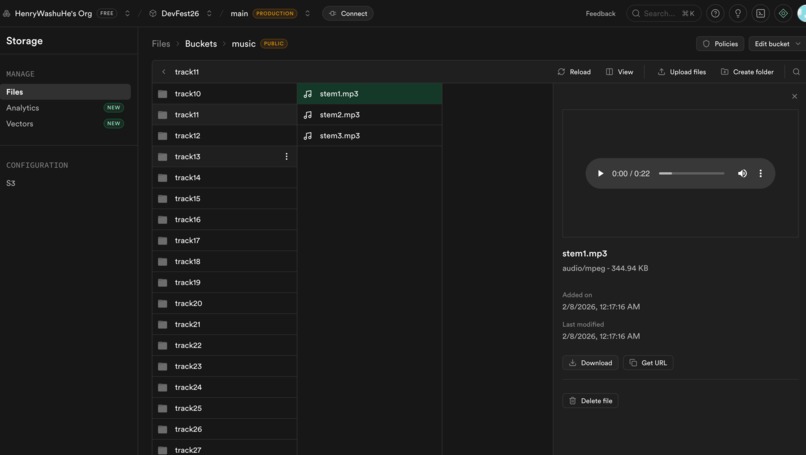
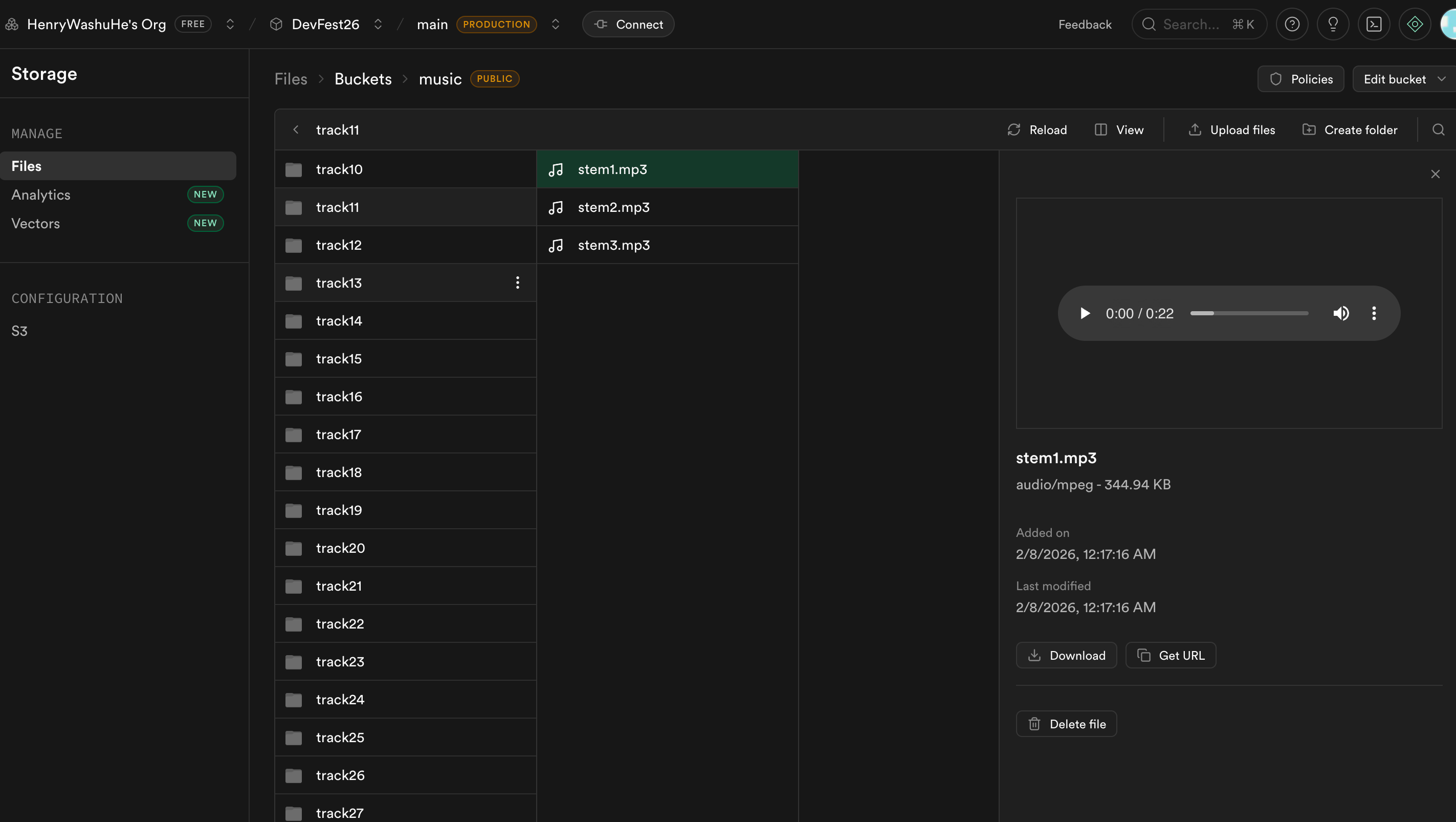
Elevens Lab generated videos stored in supabase
-
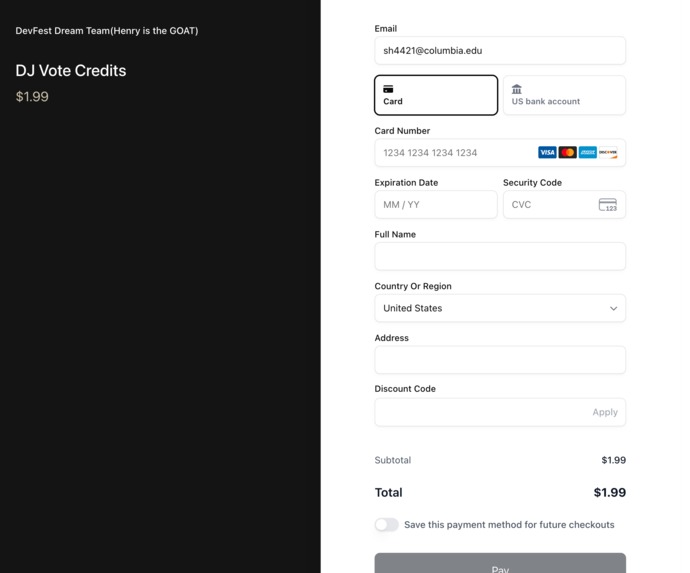
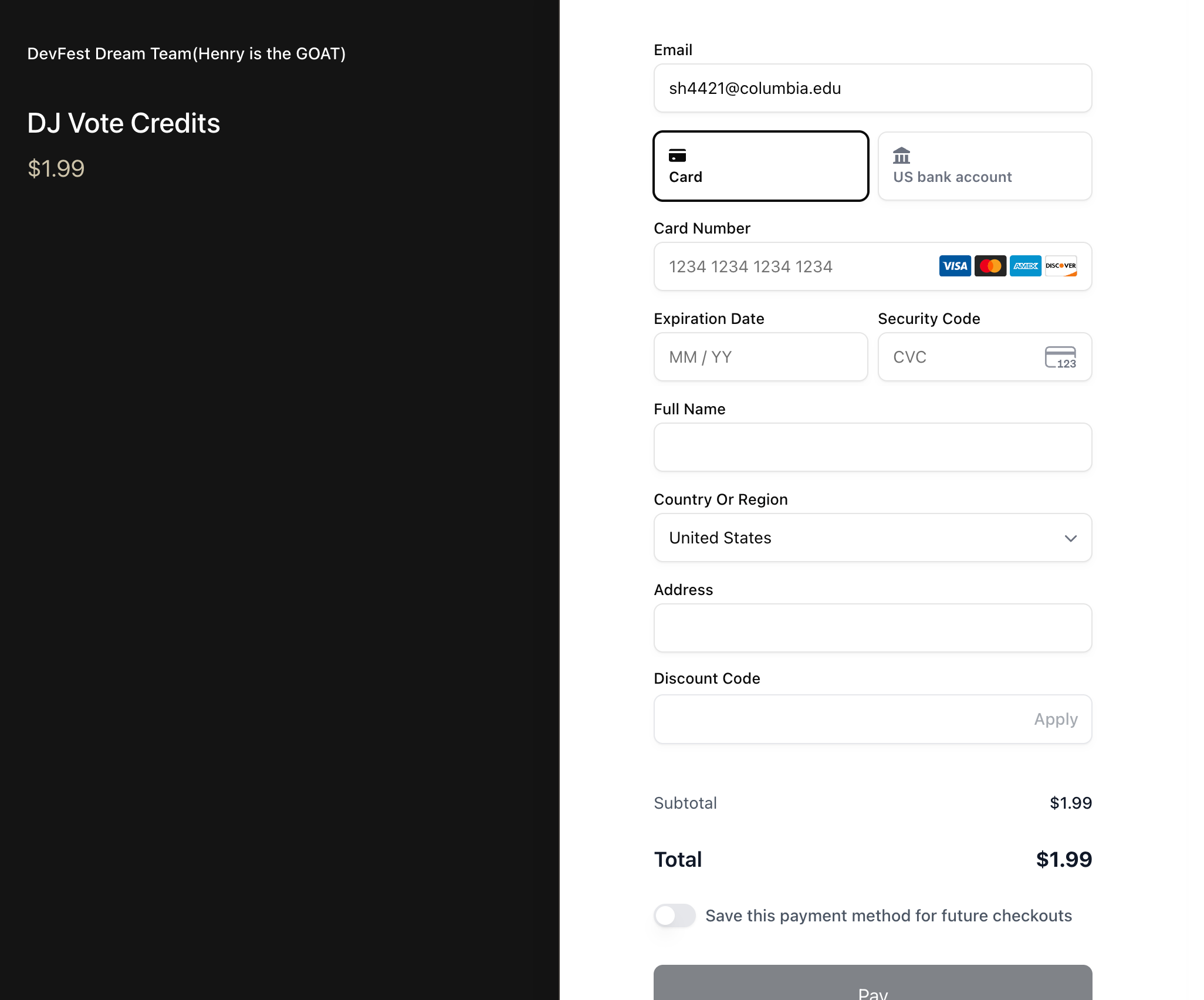
payment by Flowglad
-

3D animation

Inspiration
Every DJ booth costs thousands in hardware — CDJs, mixers, controllers. We asked: what if your hands were the controller? We wanted to build an experience where a DJ performs with nothing but a webcam, the crowd shapes the set from their phones, and an AI brain ties it all together — reading the room like a veteran DJ and making real-time creative decisions. The intersection of computer vision, generative audio, and agentic AI felt like the perfect hackathon challenge.
What it does
GestureDJ is a full-stack interactive DJ system with three layers:
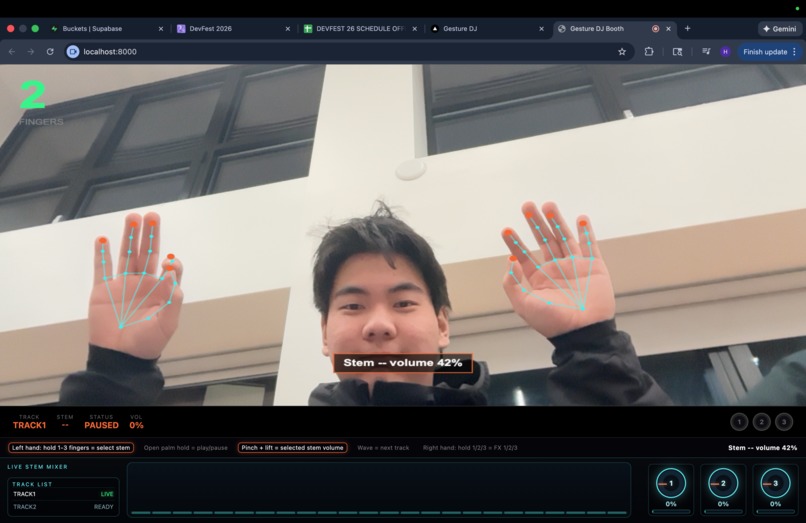
Hand-Tracking DJ Booth — MediaPipe detects hand gestures via webcam. Finger count selects stems, pinch height controls volume, open palm toggles play/pause, wave switches tracks, and right-hand fingers trigger effects. Kalman filtering makes it buttery smooth.
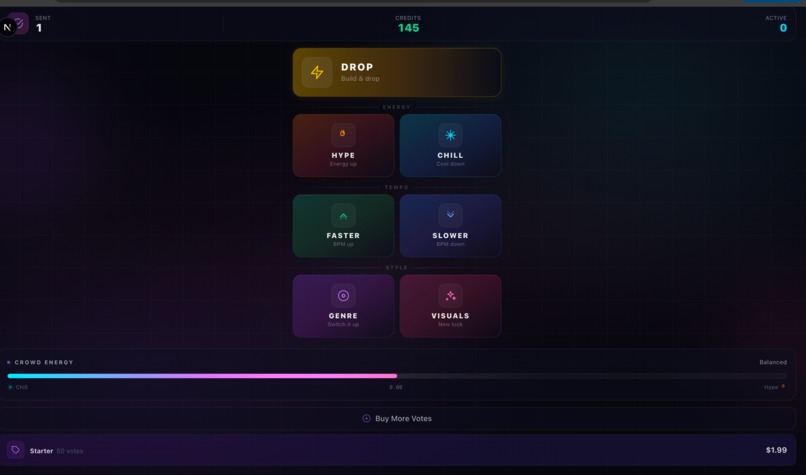
Crowd Voting — Audience members scan a QR code and vote from their phones: HYPE, CHILL, DROP, GENRE SWITCH, FASTER, SLOWER, VISUALS. Votes are session-scoped, rate-limited, and broadcast in real-time via WebSocket. The energy meter pulses with the crowd's mood.
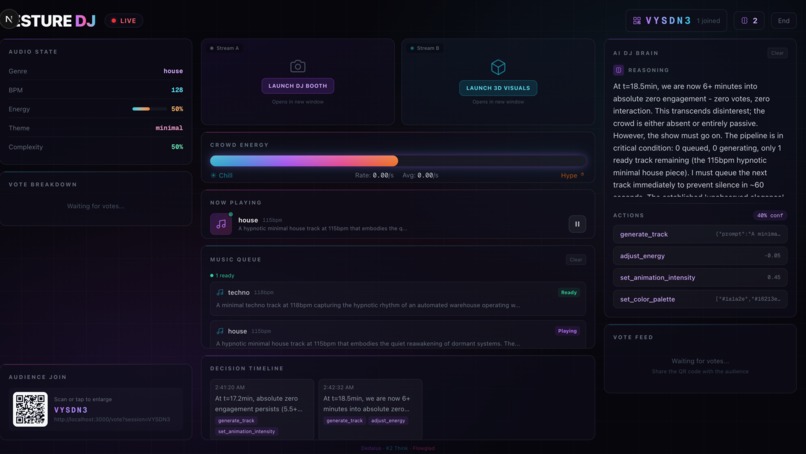
AI DJ Agent — An autonomous reasoning loop powered by Kimi K2 (via Dedalus) polls crowd votes and audio state every 15–30 seconds. It doesn't just follow majority vote — it thinks like a DJ, reasoning about energy arcs, timing, and pacing. It queues AI-generated music prompts to ElevenLabs, adjusts visuals, triggers drops, and shifts genres.
The dashboard ties it all together: live gesture state, vote feed, agent reasoning log, auto-playing generated tracks, and a QR code for audience participation.
How we built it
CV Pipeline: MediaPipe Hand Landmarker running in-browser detects 21 landmarks per hand at 30fps. A custom gesture classifier maps finger states, pinch distances, and hand velocity to DJ actions. A Kalman filter smooths continuous controls (volume, crossfade) while debouncing handles discrete triggers (play/pause, track switch).
Audio Engine: Tone.js drives stem-based playback — each track has 3+ stems with independent gain. The DJ controller bridges gestures to the audio engine with per-stem volume, master controls, and one-shot effects.
Real-Time Layer: A WebSocket server (TypeScript, ws library) routes messages between the CV client, dashboard, visualization, and agent. API routes broadcast votes via an HTTP
/broadcastendpoint to avoid Turbopack's WS connection issues.Voting System: Next.js API routes with a 30-second sliding window aggregator. Session-scoped isolation lets multiple DJ sessions run simultaneously. Server-side rate limiting (1 vote/sec per user). Reactive mobile UI with haptic feedback, animated vote overlays, and ambient energy orbs.
AI Agent: Python async loop using Dedalus SDK → Kimi K2 (
kimi-k2-thinking-turbo). System prompt encodes DJ expertise: energy arcs, crowd anticipation, drop timing. The agent outputs structured JSON with reasoning + actions. It autonomously queues music generation prompts with genre, BPM, energy, and mood metadata.Music Generation: ElevenLabs consumer polls the music queue, generates audio from the agent's creative prompts, uploads to Supabase Storage, and patches the URL back. The dashboard auto-plays ready tracks.
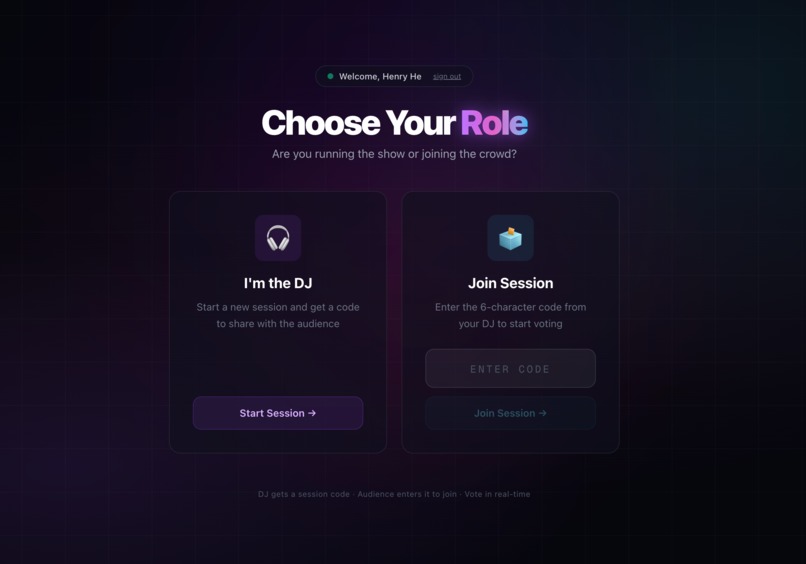
Auth & Sessions: Google OAuth via Supabase. DJs create sessions with 6-char codes; audience joins via code. RLS policies on all tables.
Payments: Flowglad SDK powers vote credit purchases — audience members buy credits via Stripe-backed checkout before they can vote, with usage tracked per session.
Challenges we ran into
Gesture stability — Raw hand landmarks are noisy. We went through three iterations before landing on Kalman filtering + dead zones + debounced discrete gestures. The play/pause gesture needed a 650ms hold threshold to avoid false triggers.
WebSocket routing in Next.js — Turbopack doesn't reliably persist module-level WebSocket connections in API routes. We solved this by adding an HTTP
/broadcastendpoint to the WS server so API routes can fire-and-forget via POST.Kimi K2 latency — The reasoning model takes 30–60s per decision. We had to design the agent loop to be truly autonomous rather than blocking, letting it set its own check interval and layer decisions over time rather than reacting frame-by-frame.
Stem synchronization — Getting multiple audio stems to start and loop in sync with Tone.js required careful transport coordination and preloading all buffers before playback begins.
Session isolation at every layer — Votes, aggregation, dashboard polling, and WS broadcasts all had to be scoped by session code. A single missed parameter would leak data across sessions.
Accomplishments that we're proud of
- End-to-end data flow works — hand gesture → audio stems → WebSocket → dashboard → agent → music generation → auto-playback. Every layer talks to every other layer in real-time.
- 9/9 E2E tests passing — vote aggregation, session isolation, rate limiting, music queue lifecycle, WS broadcast, agent API, and page rendering all tested.
- The agent actually thinks like a DJ — it doesn't blindly follow votes. It reasons about energy arcs, anticipates drops, and creates tension. The chain-of-thought reasoning is visible in the dashboard.
- The gesture controls feel natural — Kalman filtering and dead zones make volume control smooth, and the hold-to-toggle play/pause prevents accidental triggers.
- Session-scoped everything — two DJs can run simultaneously with completely independent vote pools, dashboards, and agent loops.
Monetized audience interaction — Flowglad handles payments and credit purchases so fans buy vote credits before influencing the set.
What we learned
- Kalman filters are magic for turning noisy sensor data into usable continuous controls. A few lines of code transformed jittery hand tracking into smooth DJ faders.
- Agentic AI works best with structured output — giving Kimi K2 a strict JSON schema and a curated action vocabulary made the agent reliable and debuggable.
- WebSocket architecture matters — the broadcast pattern (HTTP POST → WS server → fan-out) was more robust than trying to maintain persistent WS clients from serverless-ish API routes.
- In-memory state is fine for demos — we spent zero time on database migrations for votes/decisions. Supabase handles what needs to persist (users, sessions); everything else resets on restart.
What's next for GestureDJ
- 3D Visualization — A Three.js/R3F scene reacting to FFT data, crowd energy, and agent-driven theme/color/camera changes. The interfaces are defined, just waiting for implementation.
- Multi-DJ collaboration — two performers controlling different stem groups simultaneously.
- Spotify/SoundCloud integration — load any track and auto-separate stems via audio source separation.
- Mobile DJ mode — use phone gyroscope + touch gestures as an alternative to webcam.
- Persistent set recording — record the full session (gestures, votes, agent decisions, audio) and replay it as a visualized timeline.
Built With
- dedalus-sdk
- elevenlabs
- fastapi
- flowglad
- kimi-k2
- mediapipe
- next.js
- python
- react
- supabase
- tailwind-css
- tone.js
- typescript
- websocket



Log in or sign up for Devpost to join the conversation.