-
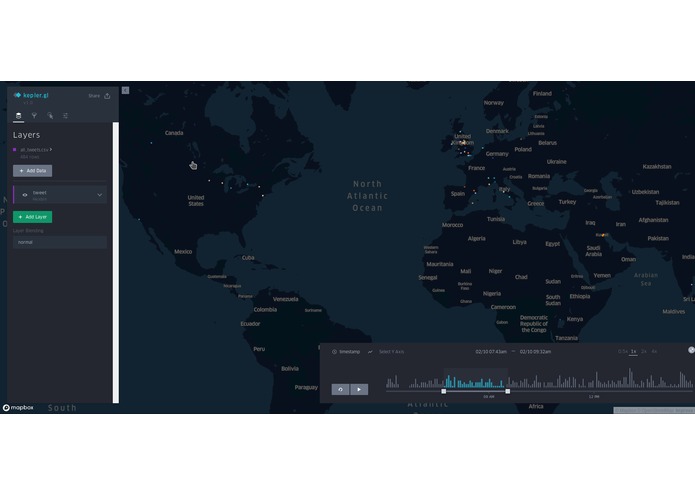
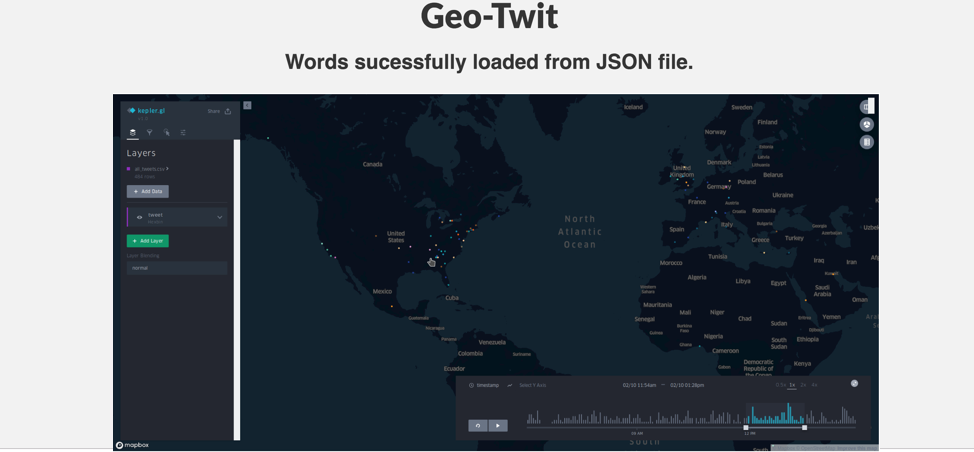
kepler.gl map
-
Welcome to GeoTwit!
-
GeoTwit page after uploading JSON File
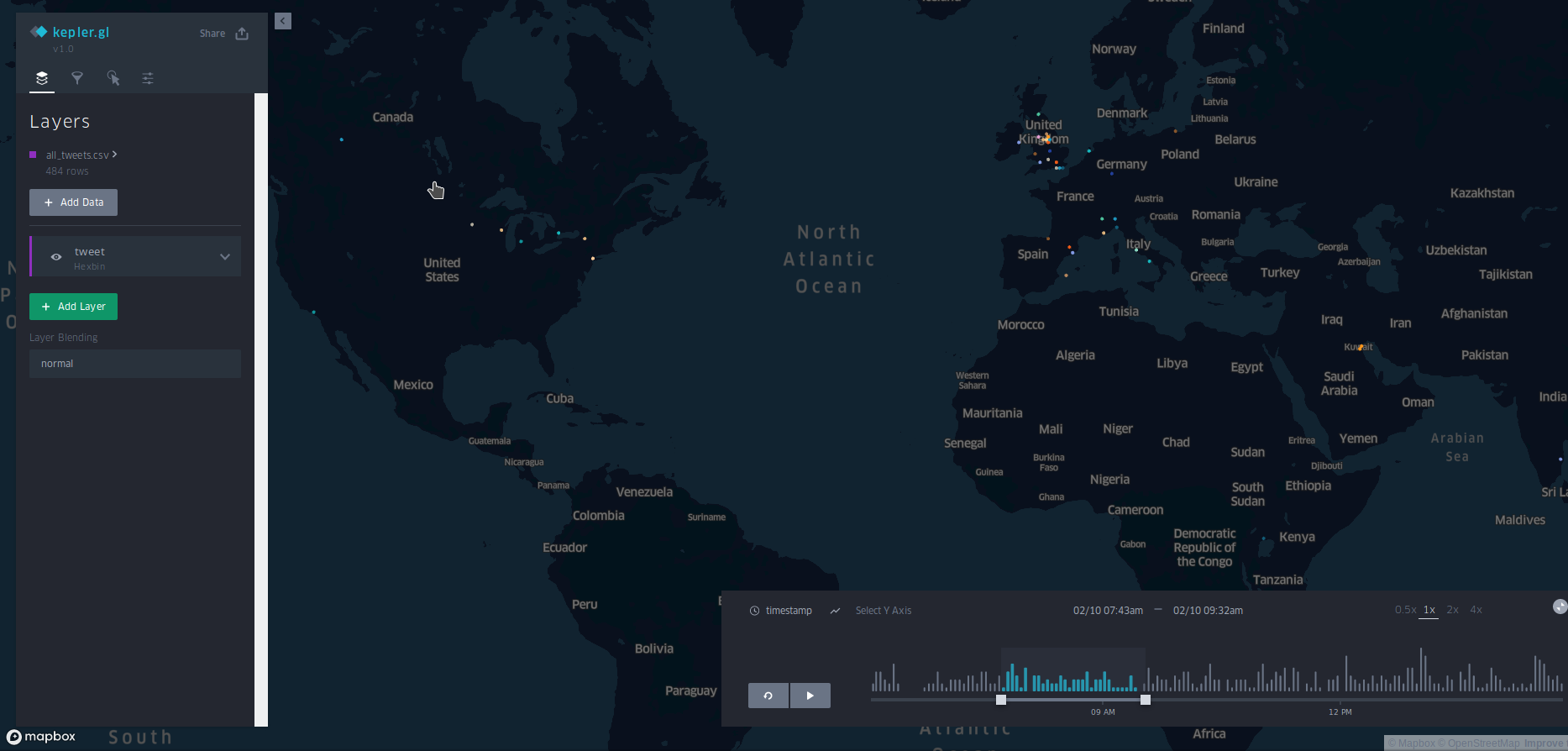
GeoTwit
Inspiration
Analysis of local trending topics and the geographic distribution of data from social media such as Twitter can be extremely useful - for example, in disaster management or for analyzing viral outbreaks. Platforms like Twitter consist of rapidly evolving data as people discuss recent events. Therefore, rapidly obtaining up-to-date and trending data from social networks is desirable.
With this in mind, we present GeoTwit, a data analysis and visualization workflow for geographic and temporal twitter data. Given a set of phrases, GeoTwit collects geotagged tweets containing each phrase and uses kepler.gl to visualize the resultant data set over space and time. For example, given a set of common political words ("Donald Trump", "Hillary Clinton", "Riot", "Yellow Vests") or weather events ("Fire", "Wildfire", "Smoke"), GeoTwit can visualize where and when tweets occur containing each of these phrases.
Moreover, we provide functionality to extract important words from a corpus of tweets (these words represent "trending topics" for the timeframe over which the corpus was collected). With these words, one can generate a new corpus, providing an iterative approach to tracking trending topics over space and time.
What it does
GeoTwit is an iterative data visualization workflow for geographic and temporal Twitter data. It provides tools to generate a corpus of tweets from a list of words or phrases via the free Twitter streaming API including the coordinates, timestamp, status text, and the associated word or phrase for each Tweet.
This data may be directly mapped via Kepler.gl. However, GeoTwit provides additional functionality. The 400 most important words from the corpus can selected using tf-idf weighting with popular.py. (We use 400 words as this is the maximum number of features which may be tracked via the free Twitter streaming API)
The recommended workflow is therefore to generate a seed corpus from the 400 most common English words, as this will generate an unbiased set of pseudo-random geo-tagged tweets. From this, the 400 top trending words or phrases are generated. Using this set of popular phrases, a new set of tweets can be generated, graphed, and analyzed. This may continue iteratively, with each successive iteration tracking the trending words, phrases, and topics of the previous corpus.
As the corpus grows, tf-idf weighting increases in accuracy. Due to limitations of the free Twitter API and the relatively low number of tweets which are geo-tagged (~2-5%), generating a large body of data is time-intensive. Each iteration is therefore recommended to span multiple weeks.
Use and Workflow
If you simply wish to view our example data set, head to kepler.gl and upload our provided keplergl.json file. Otherwise, continue.
Install pipenv, run the command pipenv shell to enter the shell
Create a track.txt file containing a list of phrases (one per line, max 400) to query. If you wish to generate a seed corpus from the most common english words, this list is helpful.
Run geotwit.py to generate the corpus. This is a long-running script, and may take weeks to generate a sufficiently large corpus.
Run aggregate.py for post-processing, preparing data for Kepler.gl
Go to kepler.gl and upload keplergl.json
This will generate a visualization of the dataset using our recommended parameters. From here, modify parameters via kepler.gl to fit your visualization needs.
You may now run popular.py to generate a list of the 400 most important phrases (max 2 words) from the corpus. This will be saved to topn.txt.
For the next iteration, copy topn.txt to track.txt and begin again with geotwit.py.
How We built it
Data collection and processing was done exclusively with Python. The Tweepy streaming API was used for collecting data from Twitter. Sklearn was used for tf-idf weighting.
Data is visualized using Kepler.gl - we use a custom .json configuration to initialize the data in kepler.gl correctly.
Challenges We ran into
We had difficulty establishing a front-end for the service due to a lack of experience from our development team, which is composed of back-end and data analysis focused developers. Our main challenge was figuring out how to properly host a website using PHP/mySQL. This was necessary in order to save data collected from user input. Although this was an obstacle, we were able to create a basic web page where we used html/CSS/javascript to implement the design of the GeoTwit application. Examples of the expected layout can be viewed in the image gallery. Make sure to check out our progress directly in our GeoTwit webpage zip.
It requires weeks to generate a proper corpus each iteration. Our current dataset is therefore inadequate to properly analyze.
Our corpus is half its intended size, as half of the data collected had its coordinates saved as (longitude, longitude) due to an indexing error. This was fixed at midnight.
Accomplishments that I'm proud of
The Twitter streaming API allows the developer to track all tweets containing a phrase or set of phrases. We are interested in tracking all tweets containing any phrase from a set of 400 phrases. The Twitter API allows us to do so, but will not identify which phrase the tweet contains - we are not able to categorize tweets by which phrase they contain. To work around this, we manually parse the text of each Tweet to determine for which phrase it was a "hit."
What I learned
Some hard lessons about the work involved in front-end development.
Story boarding and use case driven development.
Lessons about properly organizing a team of developers.
Finally, limiting the geographic range of the collected data would result in a larger body of data more quickly due to the limitations of the free Twitter API. It would be best in the future to look ahead to such limitations before gathering data.
What's next for GeoTwit
Establishing a front-end which decreases the friction of collecting and analyzing this data.
Identification of trending words can be improved by implementing clustering of documents (tweets) for tfid vectorizer.
Due to the low number of tweets which are geo-tagged, the corpus generated each iteration is relatively small. However, it is possible to predict the location of a tweet based off of information in the tweet. Integrating this research into the GeoTwit project could potentially increase the size of our data sets and decrease the time between each iteration.
Built With
- kepler.gl
- python

Log in or sign up for Devpost to join the conversation.