Inspiration
Keeping up with fast-moving online-safety laws is brutal. A/B tests, UI tweaks, and true legal obligations look similar in specs. GeoGov spots the difference fast so engineers don’t ship the wrong thing to the wrong place.
What it does
Classifies specs into:
- requires_geo_logic:
true,false, ornull. true= explicit legal hook in the spec.false= clearly product-only (A/B, UX, perf, etc.).null= geo intent is ambiguous and needs review.
- requires_geo_logic:
regulations: populated when there’s an explicit hook (e.g.,
dsa,california_kids_act).reasoning + confidence: short rationale and calibrated score.
How we built it
- RAG: Qdrant over regulation texts seeded via
seed.py(MiniLM embeddings). - LLM:
qwen2.5:3b-instruct(Ollama), JSON-only via a Pydantic schema. - Prompt: Retrieval is supportive only (never creates regs). Rubric enforces: explicit hook →
true; product-only →false; ambiguous geo →null. Deterministic rules (
rules.py):- Explicit-hook regexes (CSAM/NCMEC/2258A, DSA, CA+minors+PF, UT+minors+curfew/controls, FL+minors+parental controls).
- Business-only guardrail (A/B/UX/perf) → force
false+ empty regs. - Ambiguous-geo detector (““EU-only”) →
null. - Canonicalization of reg IDs from
policy.yaml, then retrieval evidence gate to drop weak/unsupported regs.
Confidence calibration: retrieval-driven band (≈0.30–0.90), penalties when evidence < threshold.
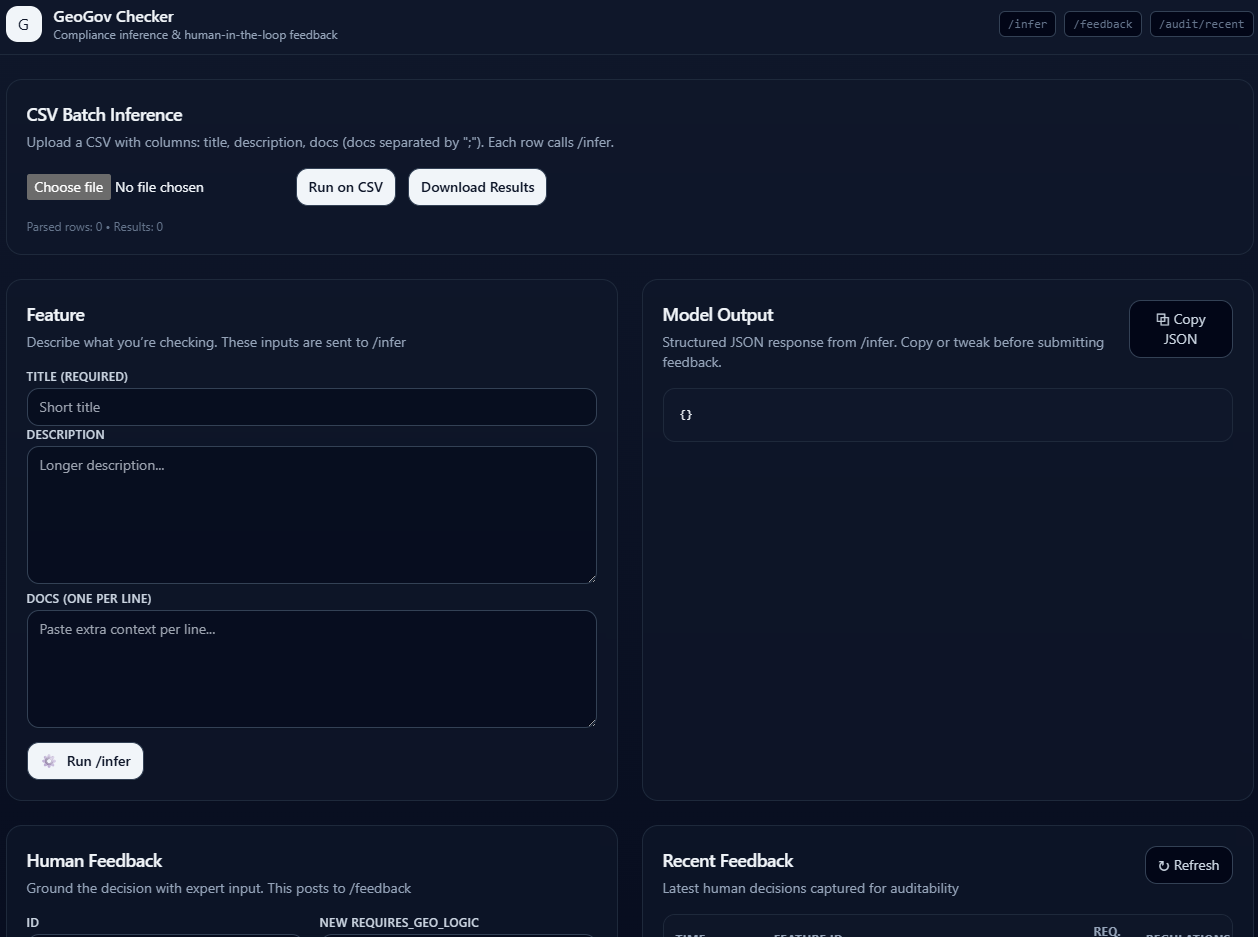
Human-in-the-loop (UI & audit)
HTML/React page
- Run
/inferand inspect structured JSON. - Correct decisions via
/feedback(setrequires_geo_logic,regulations, comment, user). - Review
/audit/recenttable for the latest overrides.
- Run
Updating via feedback
- We hash (title + description + docs) to a stable
feature_id. - Feedback is stored in SQLite (
/app/outputs/audit.db). - On future runs, confirmed feedback overrides the model (early return) and still passes the evidence gate + calibration.
- Result: the system adapts to your org’s calls with a clear audit trail.
- We hash (title + description + docs) to a stable
Challenges we ran into
- Over-eager LLMs: hallucinating laws for product tests. Fixed by hard “supportive-only” retrieval, gating, and post-processing.
- Always-high confidence: early versions pinned ≥0.6. Replaced with retrieval-driven mapping + penalties under
min_sim. - Null vs false drift: We split “ambiguous geo” (null) from “pure business only” (false) and enforced it in both prompt and rules.
Accomplishments we’re proud of
- Stable, auditable JSON from a tight loop: prompt → rules → retrieval gate → calibrated confidence.
- Reviewer override flow that “locks in” decisions and makes future runs consistent.
- Config-first controls in
policy.yaml(allowed regs, synonyms, thresholds).
What we learned
- Put deterministic policy in code; use the LLM for summarization and edge-case reasoning, not as the source of truth.
- Retrieval should narrow and validate, not invent. “Supportive-only” is a great default for compliance tasks.
- Clear taxonomy (true/false/null) avoids noisy labels and keeps reviewers focused where they’re needed.
What’s next for GeoGov
- Scale regs: expand catalog; richer synonym/trigger packs in
policy.yaml. - Evaluator suite: golden CSVs + unit tests for rubric/rules/thresholds.
- Feature diffing: highlight new legal risk between spec revisions.
- Better console: search, filters, bulk label, and exportable audit reports.
- Multilingual: add non-English pattern packs + embeddings.





Log in or sign up for Devpost to join the conversation.