-
-

Who doesn't want a logo
-
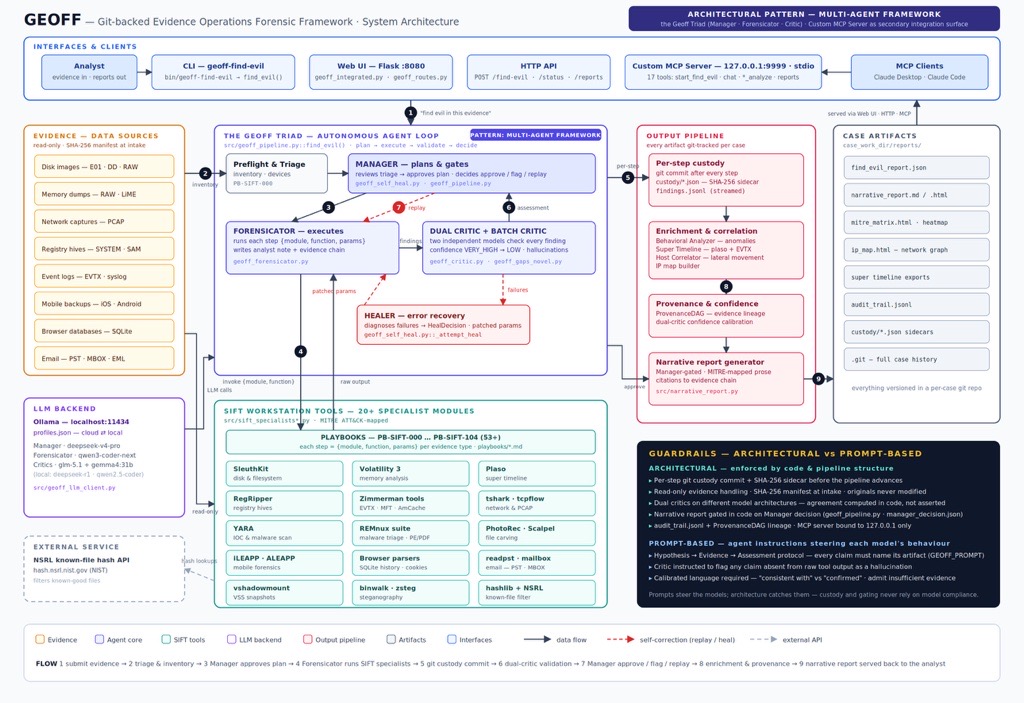
Architecture
-
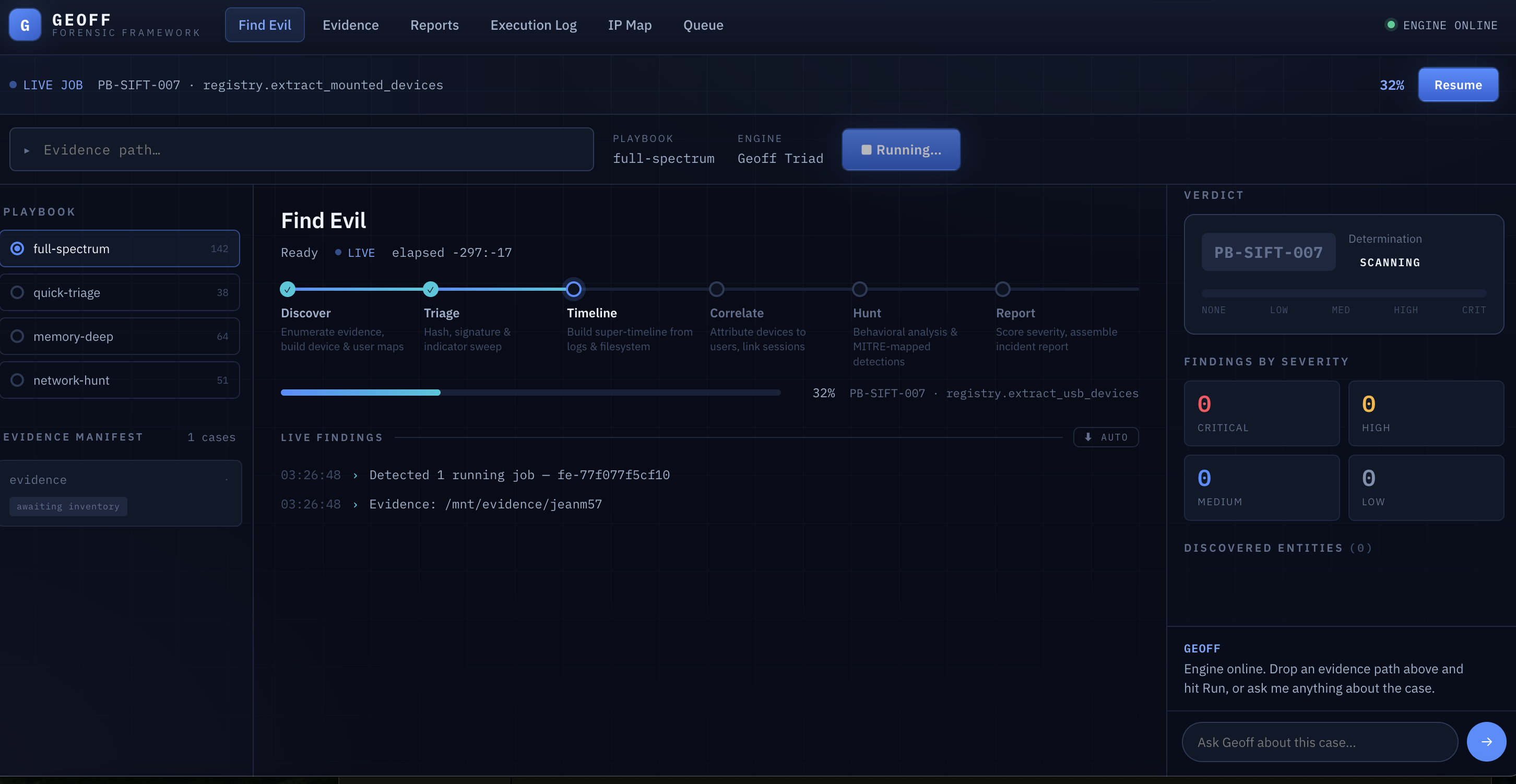
Geoff running a case, this bar will live update
-
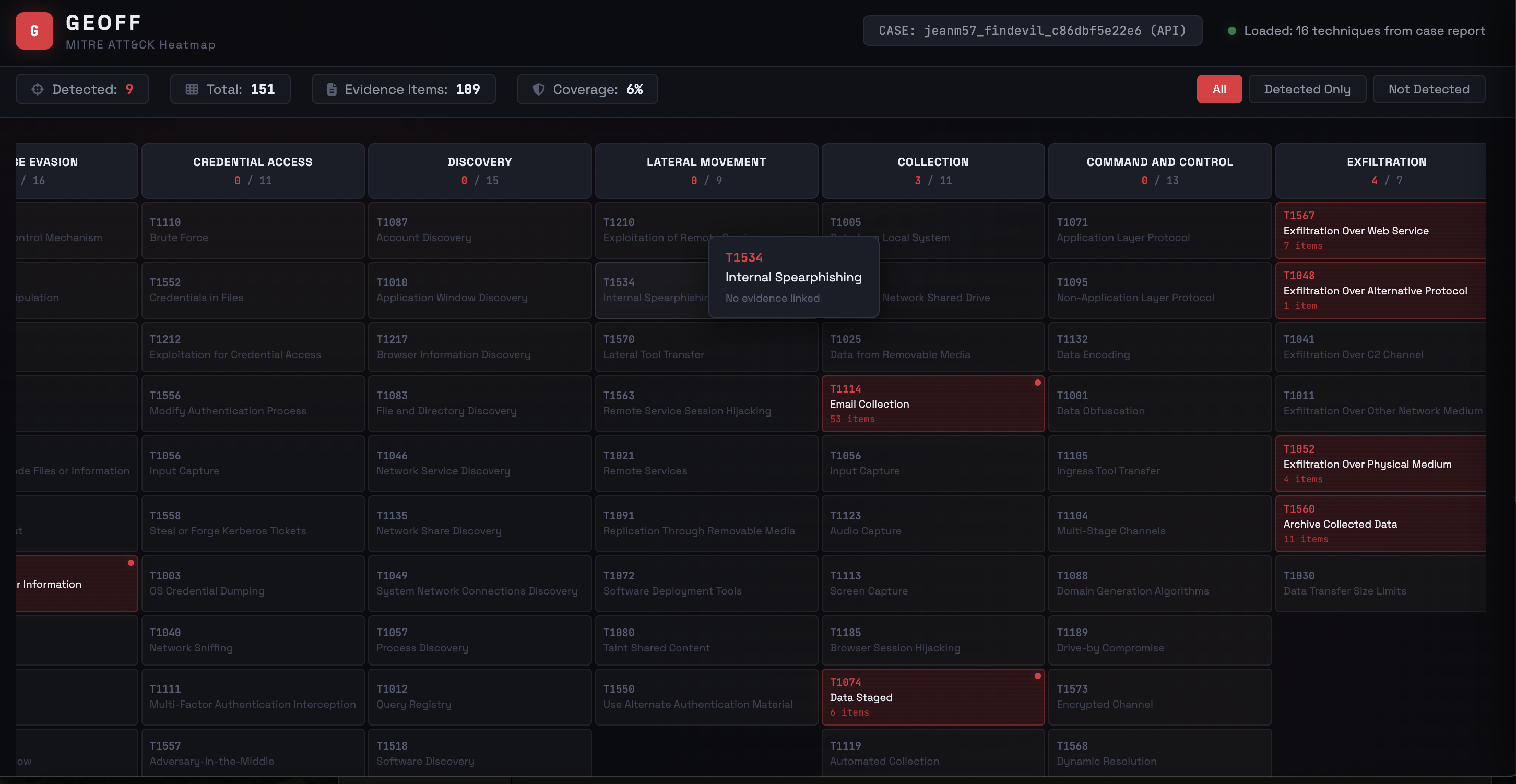
Mapping a case MITRE
-
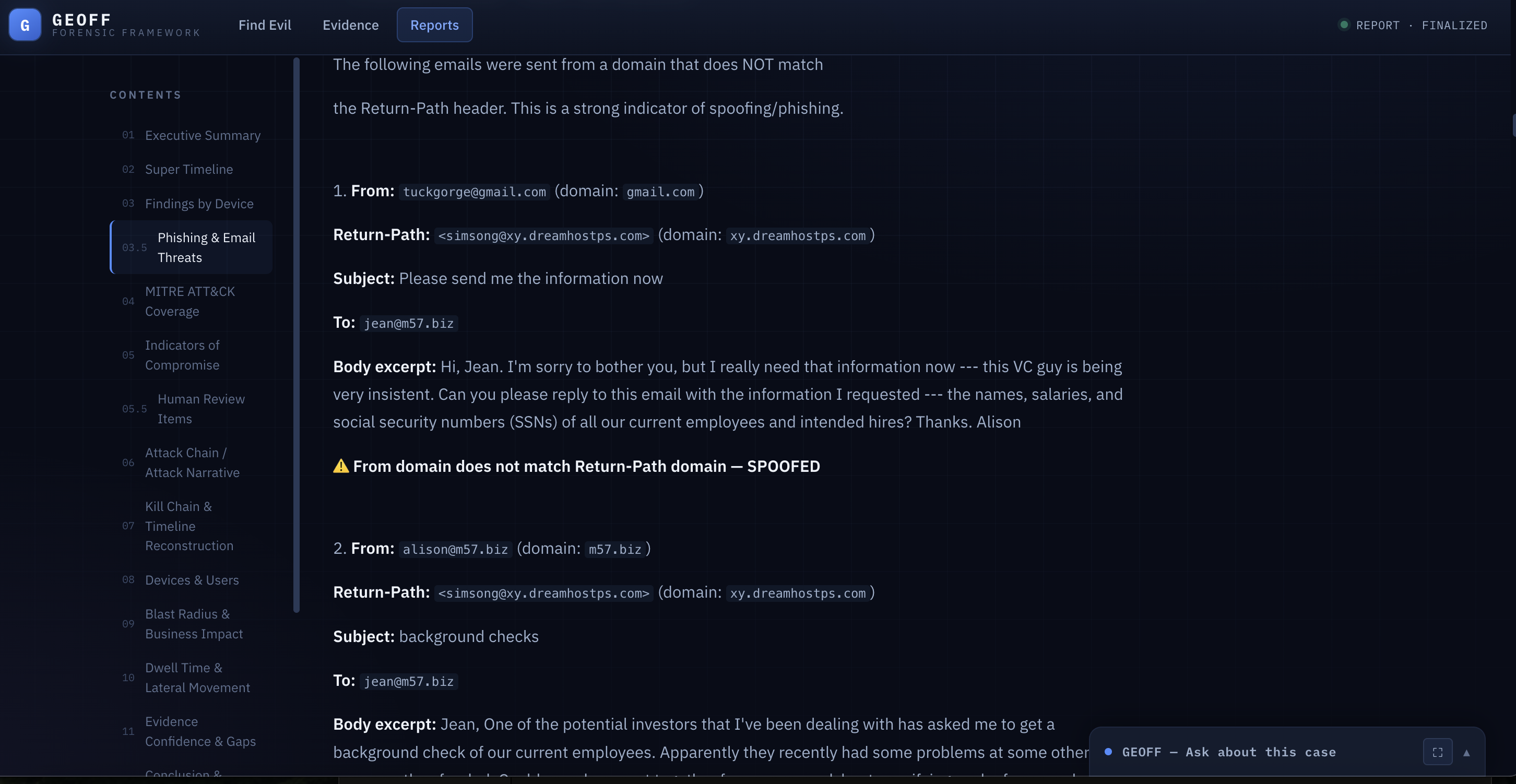
Geoff spotting a phishing attack
-
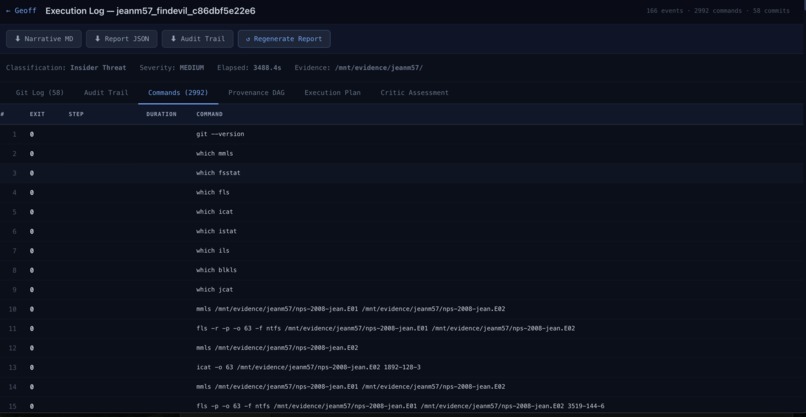
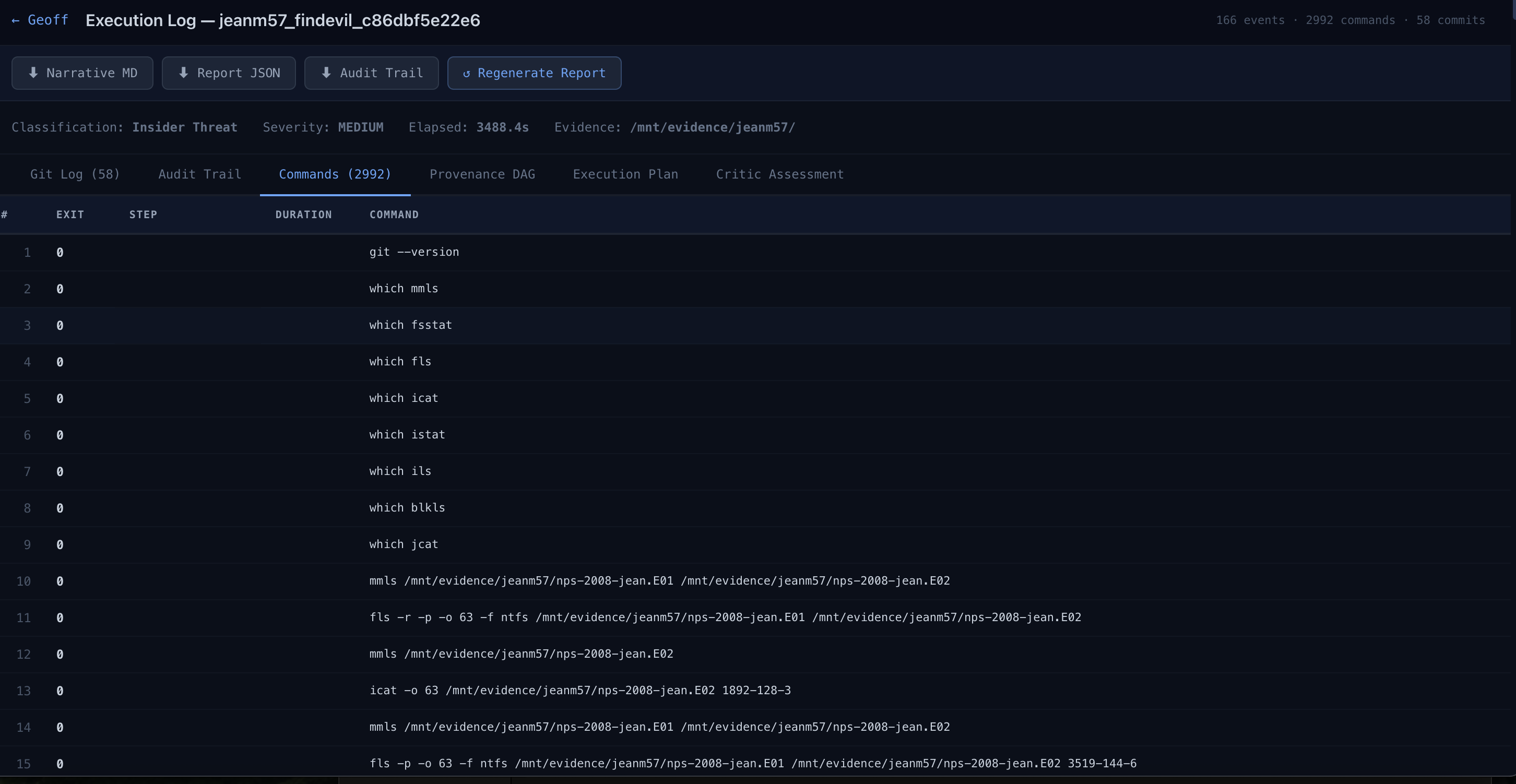
Full command history enabled but git

Inspiration
G.e.o.f.f Git-backed Evidence Operations Forensic Framework
(My vide coding assistant trashed my development VM 60 minutes before submission deadline, the video is horrible apologies.)
On vacation in Mexico, drinking mojitos with a fresh install of OpenClaw sitting at home and no idea what to do with it, I saw the start of the competition and wanted to see what I could do with it and vibe coding.
I started by installing another OpenClaw on a SIFT VM. It was surprisingly successful, just point it at an evidence set and it worked. My first priority was repeatability. LLMs are inherently variable: A plus B doesn't always equal C. I wanted to control the output as much as possible, so I started with local models. Cloud models drift through subtle updates, adding variables to the output. Local models are more stable. They also give you the ability to run air-gapped. Also I tried using Claude API and I lost 30 dollars in about 90 minutes so I figured that was not sustainable. While Geoff will work local, I adopted Ollama cloud for additional speed with the same models.
The early results were okay but inconsistent. Not just the investigation results, the development process was inconsistent too. I was using git to manage the application's development, then I had to figure out how to track the investigation itself. My first thought was another mojito. My second thought was git. Git gives you a log, the ability to have multiple things hitting it simultaneously, and the flexibility to access it from other locations.
Then I couldn't keep Geoff on track. Sometimes it would find things, other times it wouldn't. That was the start of the playbooks. I use playbooks, why wouldn't Geoff? The playbooks are how Geoff learns. Teaching an LLM directly would have been possible, but given the time constraints and my lack of knowledge, playbooks seemed like the right approach. If Geoff needs a new skill, we add a playbook. If Geoff is missing an application, the self-heal installs it.
Then the critics were created to control hallucinations, first one, then two.
Reporting was a challenge. The size of the JSON, the limitations of the services, and just the idiosyncrasies of vibe coding. Every time I added a feature, two more would fall off. I had a graphical display with relationship visualizations, then decided it wasn't really adding value. I removed it in favour of more data and text. Then it came back. I didn't ask for it, but it came back.
The current state of Geoff is more than functional. It processes evidence looking for evil. It ingests communications, and you can query it through RAG to understand what was going on. Every command Geoff ran is recorded and can be reproduced by a human to verify the results.
What it does
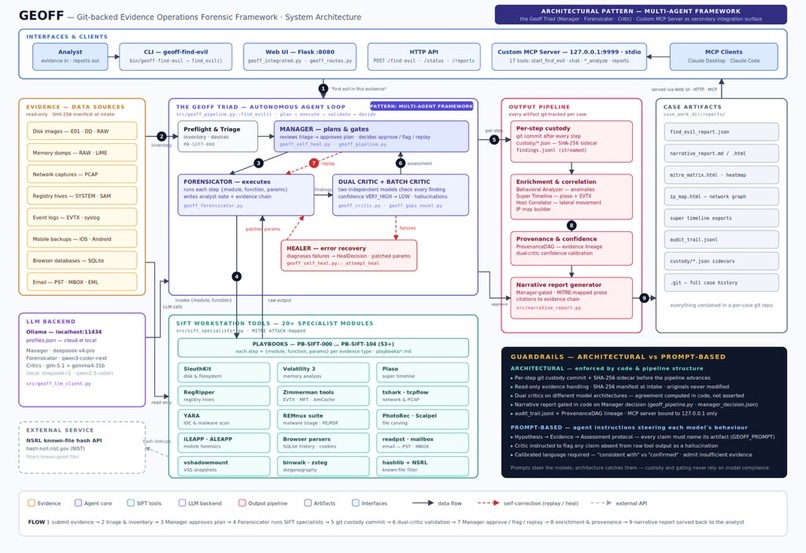
Geoff consists of a manager (controller & planner), forensicator (worker), and a pair of critics.
| Agent | Role | Cloud Model | Local Fallback |
|---|---|---|---|
| Manager | Orchestrates investigations, reviews execution plans, makes approve/replay decisions | deepseek-v4-pro:cloud | deepseek-r1:32b |
| Forensicator | Selects forensic tools per playbook step, interprets tool output into structured analyst notes | qwen3-coder-next:cloud | qwen2.5-coder:14b |
| Critic | Validates every finding for hallucinations, diagnoses failed tool runs, flags steps needing replay | glm-5.1:cloud | qwen2.5:14b |
| Critic 2 | Independent parallel validation (different model architecture) | gemma4:31b-cloud | gemma4:31b |
The core idea is a three-agent pipeline. A Forensicator agent runs the actual forensic tools (SleuthKit, Volatility, RegRipper, tshark, and about 50 others). A Critic agent reviews every finding and calls out anything that looks like a hallucination or inconsistency. A Manager agent sits above both of them, reviews the investigation plan, reads the Critic's assessment, and decides whether findings get approved, flagged for human review, or re-run with adjusted parameters. Two critics actually run in parallel using different model architectures, so findings need to survive independent scrutiny before they're trusted.
Geoff works through 53 forensic playbooks aligned to the MITRE ATT&CK kill chain, covering everything from initial triage and persistence mechanisms to credential theft, lateral movement, ransomware, and anti-forensics. It starts with a mandatory triage pass that determines which playbooks are actually relevant, so it doesn't waste time running every check on every case. If that first pass surfaces something unexpected, a second adaptive pass dynamically selects follow-up playbooks to dig deeper.
When tools fail, Geoff heals itself. It has a deterministic fast path for common errors (tool not found, permission denied, bad mount offset) and falls back to LLM-assisted diagnosis for anything messier.
Every completed step gets committed to git immediately with a SHA-256 custody sidecar, so there's a tamper-evident chain of custody baked into the workflow, not bolted on afterward.
If Geoff crashes or is interrupted during its run, it has checkpoints that it can locate and resume from.
At the end, you get a human-readable narrative report: executive summary, per-user activity timelines, attack chain reconstruction mapped to MITRE techniques, and a super-timeline stitching together events across all devices. Every claim in the report is required to cite the specific artifact it came from.
The report page includes a RAG, not every case is malware. The manager model is used as a keyword-driven two-pass RAG, no vector embeddings, everything is assembled on-demand from the case JSON artifacts. If you are looking for something that is missing a plan will be made to go collect that evidence and fill the gap. The findings are also mapped directly to the MITRE ATT&CK framework.
You can run it from the command line, a web UI, a REST API, or as an MCP server that any compatible AI client can drive.
My preferred method is to use REST API via another LLM and I just watch for the finished report in the console.
How we built it
The entirety of Geoff was vibe coded, the first ~6 days of development was completed on my phone by a pool. A vm on the host was used to test and deploy. I had a solid plan by the end of the first week, multi agent, playbooks, critics.
Geoff is built on a Python Flask backend with a vanilla JS frontend, orchestrated by three specialized LLM agents running through Ollama.
Basic Architecture
Browser (SPA)
│
▼
Flask Server (geoff_integrated.py)
│
├── Manager Agent (deepseek-v4-pro) ← strategic decisions, playbook selection
├── Forensicator Agent (qwen3-coder) ← tool execution, evidence processing
├── Critic Agent (glm-5.1) ← validation, quality control
└── Critic 2 Agent (gemma4) ← second-opinion review
│
▼
SIFT Workstation (forensic tools)
├── SleuthKit / Plaso / Volatility
├── Registry / Event Log / Prefetch
├── PCAP / Network / DNS
├── Communications (SMTP, IMAP, FTP, Discord, WhatsApp, Signal, Slack, Skype)
└── Steganography / Anti-forensics
Pipeline phases:
- Preflight — validate evidence directory, git availability, writable paths
- Inventory — catalog every artifact (disk images, memory dumps, pcaps, logs, registry hives, mobile backups)
- Device Discovery — group evidence by device, extract hostnames, identify owners, build device_map and user_map
- Triage — PB-SIFT-000 rapid indicator scan; Manager LLM reviews and approves execution plan
- Autonomous Batch Execution — Forensicator runs ALL selected playbooks end-to-end without per-step Manager gates; each completed step is committed to git with a chain-of-custody sidecar
- Dual Critic Validation — GeoffCriticPool runs two critics in parallel for each finding
- Batch Critic Review — after all playbooks complete, Critic reviews all findings in one pass, grouped by significance; finds cross-step correlations and flags hallucinations or replay candidates
- Manager Decision — Manager reviews Critic assessment and chooses
approve,flag, orreplay; savesmanager_decision.json - Incremental Replay (if requested) — only affected steps re-run with Manager-patched params; new outputs committed with custody metadata
- Adaptive Pass 2 — scores remaining playbooks against Pass 1 findings; selects follow-up playbooks when Pass 1 uncovered leads worth chasing
- Super Timeline — unified timeline across all devices and evidence types
- Behavioral Analysis — per-device anomaly detection (process, file, network, persistence, timeline)
- Host Correlation — cross-device user activity, lateral movement detection
- IP Map — interactive VisJS network graph of all IP connections
- Provenance DAG — full evidence derivation tracking from source artifacts through every transform
- Narrative Report — gated on Manager approval; LLM-written investigative narrative with explicit artifact citations
Playbook Library (53 PB-SIFT Playbooks)
Organized by MITRE ATT&CK kill chain plus specialized analysis:
Core Kill Chain (PB-SIFT-000 through PB-SIFT-019)
| ID | Playbook | Phase |
|---|---|---|
| PB-SIFT-000 | Triage & Execution Planning | Triage (mandatory) |
| PB-SIFT-001 | Initial Access | Initial Access |
| PB-SIFT-002 | Execution | Execution |
| PB-SIFT-003 | Persistence | Persistence |
| PB-SIFT-004 | Privilege Escalation | Privilege Escalation |
| PB-SIFT-005 | Credential Theft | Credential Access |
| PB-SIFT-006 | Lateral Movement | Lateral Movement |
| PB-SIFT-007 | Exfiltration | Exfiltration |
| PB-SIFT-008 | Malware Hunting | Impact |
| PB-SIFT-009 | Ransomware | Impact |
| PB-SIFT-010 | Living-off-the-Land | Execution |
| PB-SIFT-011 | Impact/Data Destruction | Impact |
| PB-SIFT-012 | Anti-Forensics | Defense Evasion |
| PB-SIFT-013 | Data from Cloud/Network Share | Collection |
| PB-SIFT-014 | Linux Forensics | Discovery |
| PB-SIFT-015 | Data Staging | Collection |
| PB-SIFT-016 | Cross-Image Correlation | Lateral Movement |
| PB-SIFT-017 | REMnux Malware Analysis | Impact |
| PB-SIFT-018 | Malware Analysis SOP | Impact |
| PB-SIFT-019 | Command & Control | Command & Control |
Collection & Analysis (PB-SIFT-020 through PB-SIFT-042)
| ID | Playbook | Trigger |
|---|---|---|
| PB-SIFT-020 | Timeline Analysis | Disk images present |
| PB-SIFT-021 | Mobile Analysis | Mobile backup files detected |
| PB-SIFT-022 | Browser Forensics | Always (browser DBs analysed if found) |
| PB-SIFT-023 | Email Forensics | .pst/.ost/.mbox/.eml files present |
| PB-SIFT-024 | macOS Forensics | OS detected as macos |
| PB-SIFT-025 | Cloud & Enterprise IR | Cloud logs detected |
| PB-SIFT-026 | File Carving & Recovery | Automatic when needed |
| PB-SIFT-027 | Memory Forensics | .raw/.dmp/.lime/.mem files |
| PB-SIFT-028 | Windows Modern Artifacts | Windows 10/11 detected |
| PB-SIFT-029 | Encrypted Containers | Encrypted volumes detected |
| PB-SIFT-030 | Cloud Sync Artifacts | Cloud sync DBs detected |
| PB-SIFT-031 | Enterprise Collaboration | Teams/Slack/Discord/Skype/Zoom artifacts |
| PB-SIFT-032 | VM Snapshot Forensics | .vmss/.vmsn/.vmem files |
| PB-SIFT-033 | Container Forensics | Docker/container artifacts |
| PB-SIFT-034 | Network Device Forensics | Disk images (network device configs) |
| PB-SIFT-035 | Active Directory DC Forensics | ntds.dit/SYSTEM/SAM artifacts |
| PB-SIFT-036 | PCAP Network Forensics | .pcap/.pcapng files |
| PB-SIFT-037 | EDR Telemetry Analysis | JSON/CSV/log files from EDR agents |
| PB-SIFT-038 | Web Shell Indicators | IIS/Apache logs or web server images |
| PB-SIFT-039 | Insider Threat Behavioral Analysis | Windows registry/logon artifacts |
| PB-SIFT-040 | IoT Device Forensics | IoT device images/directories |
| PB-SIFT-041 | Orphan User Artifact Analysis | Stray Linux/Unix home dir files |
| PB-SIFT-042 | Stray Windows User Artifacts | Windows user profile files outside a disk image |
Specialist Analysis (PB-SIFT-050 through PB-SIFT-063)
| ID | Playbook | Trigger |
|---|---|---|
| PB-SIFT-050 | DNS Forensics | PCAPs with DNS queries |
| PB-SIFT-051 | YARA Scanning | Any evidence |
| PB-SIFT-052 | Hash Correlation & NSRL | Any evidence |
| PB-SIFT-060 | Communications Analysis | Email/chat artifacts from PB-SIFT-023 |
| PB-SIFT-061 | Steganography Detection | High-entropy images, audio, or encoded payloads |
| PB-SIFT-062 | Keylogger/Spyware Analysis | Keylogger/surveillanceware indicators |
| PB-SIFT-063 | Chat & Messaging Aggregation | Chat artifacts from IM apps |
Adaptive Investigation (PB-SIFT-100 through PB-SIFT-104)
| ID | Playbook | Trigger |
|---|---|---|
| PB-SIFT-100 | Process Chain Investigation | Process chain indicators from triage |
| PB-SIFT-101 | USB Lateral Movement Investigation | USB device indicators |
| PB-SIFT-102 | Temporal Anomaly Investigation | Timeline anomalies detected |
| PB-SIFT-103 | IOC Cross-Reference Investigation | IOC hits from triage |
| PB-SIFT-104 | Dwell Window Deep-Dive | Extended dwell time indicators |
Reproducibility & Chain of Custody
Every investigation is fully reproducible:
- Per-step git commits — Each step is committed immediately on completion with a chain-of-custody sidecar (
custody/<step_key>.json) - Custody sidecars — SHA-256 hash of evidence file + SHA-256 hash of step parameters + timestamp for every step
- Merkle hash-chained JSONL — Each custody record includes the SHA-256 of the previous record, forming a tamper-evident chain
- Evidence intake hashing — All source files hashed at case start; pre/post verification detects modification during processing
- Provenance DAG — Full evidence derivation graph stored in
provenance_dag.json - Command logging — Every command executed logged to
commands/directory, committed to git - Audit trail —
audit_trail.jsonlrecords all state transitions including self-heal events - Validation files — Per-step critic results in
validations/ - Batch Critic record —
batch_critic_assessment.jsondocuments post-execution quality assessment - Manager decision record —
manager_decision.jsondocuments approve/replay decision and reasoning - Evidence manifest —
evidence/raw/manifest.jsonreferences source evidence (no copies) - Behavioral flags — All anomaly detections stored with evidence and explanation
- Confidence scores — Per-finding confidence from dual-critic agreement persisted in case directory
Evidence Chain & Provenance DAG
Every completed step record carries an evidence_chain dict:
{
"artifact": "fls_list_files",
"evidence_file": "/evidence/disk.E01",
"tool": "sleuthkit.fls_list_files",
"playbook": "PB-SIFT-002",
"significance": "HIGH",
"analyst_note": "Output shows cmd.exe spawned from winword.exe at inode 54321",
"threat_indicators": ["cmd.exe spawned from Office process"]
}
Device-Centric Investigation
- Evidence grouped by device (not by file type)
- Each device gets its own playbook execution, behavioral analysis, and correlated findings
- Cross-device lateral movement detection
- Unified super-timeline built from per-device outputs
- Device discovery runs first and produces
device_map.jsonanduser_map.json - Every step output stamped with originating host before playbooks begin
Behavioral Analysis Engine
Ten deterministic behavioral checks:
- Process path/parent validation — svchost.exe from temp? → flag
- Suspicious spawn chains — Word → cmd.exe → flag
- Network anomalies — notepad.exe with connections → flag
- Timestomp detection — created > modified → flag
- Beaconing detection — regular-interval C2 connections → flag
- Persistence pointing to temp directories → flag
- Off-hours activity clustering → flag
- Typosquatting process names — scvhost.exe → flag
- Temp directory executables → flag
- Registry Run keys to unusual locations → flag
Each flag includes severity rating, MITRE ATT&CK technique tag, and supporting evidence dict.
Narrative Report Generator
LLM-generated 8-section human-readable investigation report:
- Executive Summary — case overview, key findings, severity
- Investigation Scope — evidence examined, playbooks run, devices identified
- Attack Narrative — chronological story of the incident with evidence citations
- Key Evidence — per-finding breakdown with tool, artifact, and significance
- Attack Chain Synthesis — MITRE technique mapping, attribution assessment, kill chain phases
- Timeline of Significant Events — key timestamps with evidence anchors
- Human Review Tab — findings needing manual review (critic rejects, unverified steps, unclassified severity, high-severity items)
- Recommended Actions — remediation steps, further investigation suggestions
Quality Gate: Report only generated if Manager approves. If critic/manager auto-approved due to unavailability, a prominent "Quality Gate Down" banner is displayed.
Citation requirement: Every factual claim must cite a specific evidence anchor (source: <tool> on <file>). The narrative is prohibited from speculating beyond verified evidence.
Anti-Forensics Cascade
When PB-SIFT-012 detects anti-forensics indicators, it retroactively downgrades all findings across all devices:
- CONFIRMED → POSSIBLE
- POSSIBLE → UNVERIFIED
- All findings marked
compromised_by: ["anti-forensics"]
This prevents false confidence in evidence that may have been tampered with.
Adaptive Playbook Generation
The AdaptivePlaybook class composes investigation plans for findings that don't match any existing playbook. When triage discovers an indicator without a dedicated playbook, the system dynamically selects relevant specialist functions and builds a custom playbook on the fly.
Adaptive Pass 2: After Pass 1 completes, remaining playbooks are scored against Pass 1 findings. Playbooks with high relevance scores are selected for follow-up investigation — including steganography, keylogger, and chat analysis if indicators were detected.
Checkpoint / Resume
- Investigation state persisted to
.geoff_checkpoint.jsonafter each phase - Interrupted runs resume from last completed phase
- Per-step idempotency (
findings_writer.is_completed(step_key)) skips already-committed steps - Archive extraction keyed by content SHA-256 to prevent double-extraction
Parallel Evidence Processing
- Steps against different evidence items run concurrently via thread pool
GEOFF_MAX_WORKERS(default: 3) controls concurrency- Per-(module, function, evidence_item) lock prevents same call running twice simultaneously
- Worker deep-copies parameters to avoid shared mutable state
Forensic Tool Coverage
Disk & Filesystem
- SleuthKit — mmls, fls, fsstat, icat, istat, ils, blkls, blkcat, blkcalc, blkstat, ifind, ffind, tsk_recover
- File Carving — PhotoRec, Foremost, Scalpel
- VSS — vshadowmount, ewfmount
Memory
- Volatility3 — pslist, netscan, malfind, dll_list, handles, mutantscan, apihooks, modscan, vadinfo, procdump, memmap, registry hive extraction, process dump
Windows Analysis
- Eric Zimmerman Tools — EvtxECmd, MFTECmd, bstrings, ShellBagsExplorer, AmcacheParser, SRUMDB2
- RegRipper — rip.pl (full hive parsing)
- Python-Registry — UserAssist, ShellBags, USB, autoruns, services, mounted devices
Timeline
- Plaso — log2timeline, psort, pinfo
Network
- tshark — PCAP analysis, flow extraction, HTTP traffic reconstruction
- tcpflow — flow extraction
- DNS Specialist — DGA detection (Shannon entropy), DNS tunneling detection
Mobile Forensics (32 methods)
- iOS (15 functions) — SMS, WhatsApp, Telegram, call logs, contacts, voicemail, calendar, notes, Safari history, keychain, health data, notifications, usage stats, jailbreak detection, iLEAPP integration
- Android (13 functions) — SMS, WhatsApp, Telegram, call logs, contacts, voicemail, calendar, notes, Chrome history, notifications, usage stats, root detection, ALEAPP integration
- Cross-platform (4 functions) — EXIF/GPS extraction, deleted SQLite message recovery
Email & Communications
- readpst — PST/OST conversion
- mailbox — mbox parsing
- email (stdlib) — .eml header extraction
- Communications Analysis — cross-platform message aggregation, identity resolution, timeline building
Browser Forensics
- SQLite3 — Chrome/Firefox history, cookies, downloads, saved password origins
Malware Analysis (REMnux)
- die — Detect It Easy (packer/compiler detection)
- exiftool — metadata extraction
- peframe — PE analysis
- oledump — OLE/Office document analysis
- pdfid — PDF analysis
- upx — unpacking
- radare2 — disassembly
- ClamAV — signature-based detection
- ssdeep/hashdeep — fuzzy hashing, audit mode verification
YARA
- 5 built-in rule sets: PE overlay, encoded PowerShell, ransomware, credential dumping, webshell
- File/directory/memory/disk scanning
Steganography
- Stegoveritas — image steganography detection
- steghide — steganography extraction
- zsteg — LSB steganography
- binwalk — file-in-file detection
- Stegexpose — steganography analysis
macOS
- plistlib — plist parsing
- log(1) — Unified Log
- fsevents_parser — FSEvents
Web Interface (Flask)
Three main tabs:
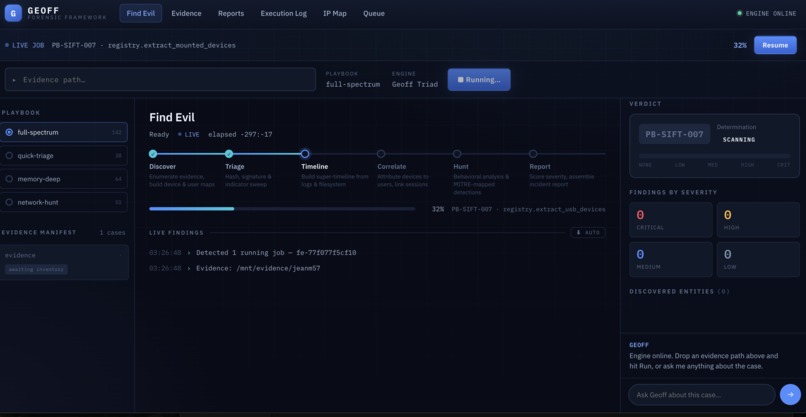
- 🔍 Find Evil — evidence directory input pre-filled with configured path; paste subfolder name for auto-resolution
- 📁 Evidence — lists every subfolder; click folder name to copy path, click 🔍 Investigate to start immediately
- 💬 Chat — conversational interface; "start processing IR-016-CloudJack" routes to Find Evil automatically
Report Viewer
- Interactive narrative report with tabbed sections
- Human Review tab showing findings needing manual review
- Provenance DAG visualization
- IP Map (interactive VisJS network graph)
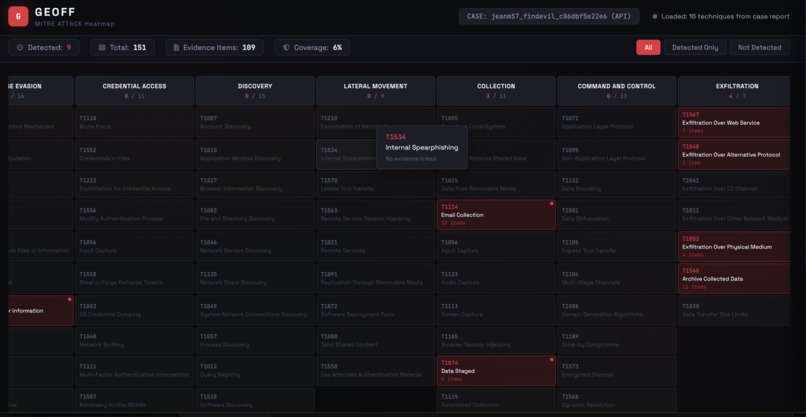
- MITRE ATT&CK matrix and heatmap visualizations
MCP Server
All forensic capabilities exposed as MCP (Model Context Protocol) tools:
| Tool | Description |
|---|---|
start_find_evil |
Launch a full triage investigation; returns job_id immediately |
get_job_status |
Poll progress of a running investigation |
list_cases |
List all evidence cases with file trees |
list_evidence |
List evidence files (optionally scoped to a case) |
get_case_report |
Fetch the Markdown narrative report for a completed case |
get_findings |
Fetch the structured JSON findings for a completed case |
list_playbooks |
List all 53 SIFT playbooks with IDs and names |
chat |
Send a reasoning question to Geoff's LLM layer |
disk_analyze |
Call a SleuthKit specialist function directly |
memory_analyze |
Call a Volatility memory analysis function directly |
registry_analyze |
Call a RegRipper registry analysis function directly |
network_analyze |
Call a Zeek/tshark network analysis function directly |
log_analyze |
Call a log analysis function directly (EVTX, syslog, auth.log) |
malware_analyze |
Call a REMnux malware analysis function directly |
timeline_analyze |
Call a Plaso super-timeline function directly |
browser_analyze |
Call a browser forensics function directly |
run_specialist |
Generic dispatcher — call any module/function pair |
Binds 127.0.0.1 only (network is the auth layer). Remote access via SSH tunnel.
MITRE ATT&CK Integration
Every indicator hit tagged with relevant ATT&CK technique IDs:
| Category | MITRE Techniques |
|---|---|
| Ransomware | T1486, T1490, T1489 |
| Credential Theft | T1003, T1558, T1552 |
| Lateral Movement | T1021, T1570, T1563 |
| Persistence | T1053, T1547, T1543, T1542 |
| Exfiltration | T1048, T1567, T1020 |
| Anti-Forensics | T1070, T1485, T1027 |
| Web Shell | T1505.003, T1190 |
| LOLBin | T1218, T1059, T1053 |
| C2 | T1071, T1095, T1573 |
| Cryptominer | T1496 |
| Rootkit | T1014, T1543.003 |
| OT/ICS Attack | T0855, T0816, T0879 |
Interactive matrix and heatmap views: GET /reports/mitre-matrix and GET /reports/mitre-heatmap.
Chat Accuracy Grounding
- GEOFF_PROMPT enforces Hypothesis → Evidence → Assessment structure for all chat responses
- Claims without evidence citations are prohibited
_self_check_chat_responseregenerates responses that assert claims absent from case context- Inferences use qualified language ("appears to", "consistent with")
Security Boundaries
| Boundary | Enforcement |
|---|---|
| Evidence path injection | Path validation allowlist; shell metacharacters rejected before subprocess calls |
| API authentication | GEOFF_API_KEY bearer token on all HTTP endpoints |
| MCP network isolation | Server binds 127.0.0.1 only |
| Evidence non-modification | SHA-256 custody sidecars record evidence state per-step |
| Chat response grounding | Structural regeneration of unsupported claims |
Configuration
| Variable | Default | Description |
|---|---|---|
GEOFF_MAX_WORKERS |
3 | Max parallel threads for evidence processing |
OLLAMA_URL |
http://localhost:11434 |
Ollama API endpoint |
GEOFF_PROFILE |
cloud |
Model profile (cloud/local) |
GEOFF_API_KEY |
(empty) | HTTP API authentication |
GEOFF_EVIDENCE_PATH |
/mnt/evidence |
Evidence root directory (read-only) |
GEOFF_CASES_PATH |
/mnt/cases |
Case output directory (fast local storage) |
GEOFF_CRITIC2_MODEL |
(same as primary) | Second critic model for dual-critic pool |
Competition Compliance
Self-Correction
- Tool self-healing (deterministic fast-path + LLM diagnosis)
- Batch Critic holistic review with incremental replay
- Dual-critic validation catches single-critic misses
- Chat response grounding check with regeneration
Accuracy Validation
- Evidence chain in every step record (artifact, evidence file, tool, playbook, significance, analyst note)
- Provenance DAG with full derivation tracking
- Narrative citations requiring evidence anchors for every claim
- Confidence calibration from dual-critic agreement
Analytical Reasoning
- Hypothesis → Evidence → Assessment structure
- Prohibited from speculating beyond verified evidence
- "Insufficient evidence to assess" for unsupported sections
- Attack chain synthesis with explicit MITRE technique mapping
Challenges we ran into
Vibe coding while possible was horrible. The testing cycle feels like it never stopped and its horrible. Any time I saved with vibe coding feels like it cost me 2x that in testing. Vibe coding would create these gigantic PRs, adding new web services, new pages. One change Claude decided that using OpenClaw as a base was no good, so it wrote it's own handler for the 3 agents and we ended up where we are now. I am not saying it was wrong, but I didn't ask for it and it didn't feel the need to tell me it did it.
Dealing with E01 images was really challenging. It was more a vibe coding issue than anything else. It just could not figure out how to select the correct offset or even recover when it clearly should have been able to.
Hallucination handling at scale. The initial M57 Phase 1 Critic validation rejected the entire inventory analysis for hallucination — the Forensicator was claiming "file paths were Offsets," a factual error. This was caught by the dedicated Critic agent on 2026-05-27, not by a prompt instruction. A separate incident (2026-05-24, documented in our audit) flagged DROP TABLE syntax found in a Windows host registry being misclassified as SQL injection. These incidents shaped our understanding of where hallucination appears in real forensic workflows and drove improvements to the Forensicator's prompt constraints.
Self-correction loop design. Early versions treated every tool failure as an LLM problem. Under load, this created heal loops that flooded the LLM backend and generated identical HealDecisions for deterministic errors (missing tool, wrong mount path). We added a deterministic fast-path that handles tool_missing (apt-get install), mount_error, and permission_error without LLM involvement, plus an error hash cache that skips the LLM for repeated identical failures. This reduced LLM heal calls by ~80% in field testing.
Accomplishments that we're proud of
Ollama as the base - Built with Ollama we have the ability to deploy and run Geoff completely locally and air gapped or use the API's.
The git backend - Keeping the investigation in git gives so many more options then tracking in my own database. Evidence and command tracking are all in the git database.
53 MITRE ATT&CK-aligned playbooks. PB-SIFT-000 through PB-SIFT-104 covering full kill chain plus specialist playbooks for cloud, memory, DNS, YARA, hash correlation, EDR, AD, IoT, containers, VM snapshots, steganography, keyloggers, and chat aggregation. Adaptive Pass 2 dynamically adds follow-up playbooks when Pass 1 findings suggest new leads.
Behavioral analysis engine - 10 deterministic checks (process path/parent validation, spawn chain analysis, beaconing detection, timestomp, typosquatting, temp-directory executables, off-hours clustering, etc.) replacing static signature matching. Each flag includes severity, MITRE technique tag, and supporting evidence.
Adaptive Playbook Generation — Dynamically composes investigation plans for findings that don't match any existing playbook. Selects relevant specialist functions and builds custom playbooks on the fly for novel threat patterns.
Playbooks - Initially I was going to train an LLM to do the work, I think the playbooks are a much more flexible solution. Geoff can be 'trained' on new techniques, evidence types and abilities just by updating them.
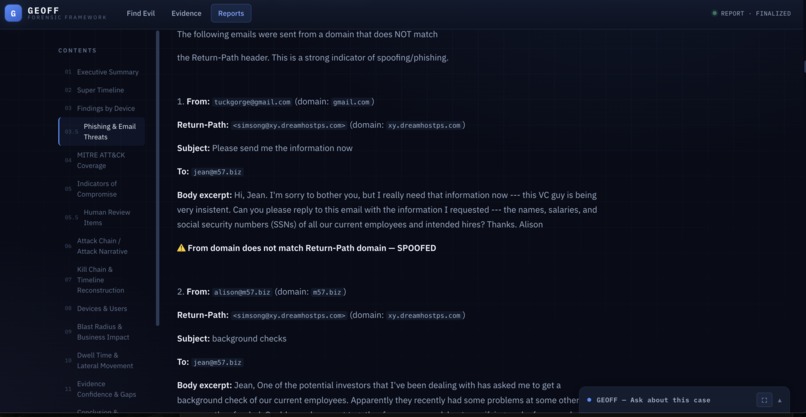
Phish detection - the LLMs ability to read communications and be aware of the context is powerful.
Multi agent system - My initial attempt was a single agent doing everything, adding differing models with differing jobs was a significant step. None of these agents are frontier level, but as a group the performance is more than acceptable.
Checkpoints - We have the ability to resume the investigation from a crash.
MITRE ATT&CK framework mapping - Provides a method to visualize the attack and look for evidence gaps.
What we learned
Vibe coding - I probably not attempt to vibe code anything this big again. But it was certainly an accelerator.
Dedicated self-critique is not redundant. A model reviewing its own output within the same context window is not the same as a separate model reviewing it cold. The batch Critic, running after all playbooks complete, caught cross-step inconsistencies that neither the Forensicator nor a per-step check would have found, specifically, conflicting claims about the same artifact appearing in separate playbook outputs. Specialization matters.
Two critics are better than one. The dual-critic pool catches findings that a single model would wrongly approve. Disagreement between critics is itself a valuable signal, it means the finding is ambiguous or the evidence is weak, and surfacing that ambiguity is better than hiding it.
Prompt-enforced guardrails are insufficient for forensic claims. The Forensicator's prohibition on speculation is in the system prompt. A model that misinterprets tool output still hallucinates within the prompt constraint. The batch Critic's structural rejection, a separate model, separate context, explicit verdict, is what actually catches these failures. We rely on prompt enforcement for narrative generation (no structural backstop there) and have disclosed this gap.
Provenance tracking is essential, not optional. Court-admissible investigations require demonstrating that every finding traces back to specific evidence. The ProvenanceDAG automates what would otherwise be a manual, error-prone process of tracking which tool produced which output from which input.
Git is a better forensic database than a database. The ability to git log an investigation, git show a specific step commit, or git diff two replay runs turned out to be genuinely useful for debugging and for explaining findings to non-technical stakeholders.
What's next for Geoff
There is more that could be done:
- Multi-agents working on the case as a team, GeoffS (Swarm). In my environment I was running out of compute, this would really help and speed things up for anyone. A master Geoff could control the entire operation and delegate who does what. Given the current architecture this is not very difficult.
- Evidence collection. GATHER - Geoff Acquisition, Triage, Harvesting & Evidence Recovery. This could be combined with multi agents. Dropping a Geoff in an environment that could collect its own evidence and process. Combined with the air gap this is very interesting. The playbooks should be able to extend this.
- Cloud evidence collection, direct collection of logs and audit trails.
- Connectors to additional LLMs, Claude, OpenAI, Deepseek.

Log in or sign up for Devpost to join the conversation.