Inspiration
Google gets 8.5 billion searches a day, but people are increasingly getting answers from ChatGPT, Perplexity, and Google AI Overviews — without clicking a single link. We realized the rules of content discovery are changing. SEO got you ranked. But GEO (Generative Engine Optimization) gets you cited. In real estate, brokerages spend thousands producing market reports and neighborhood guides, yet almost none of that content is structured for AI engines to reference. We wanted to build an agent that closes that gap — one that autonomously researches live market data and produces content briefs specifically engineered to be the source AI search engines cite.
What it does
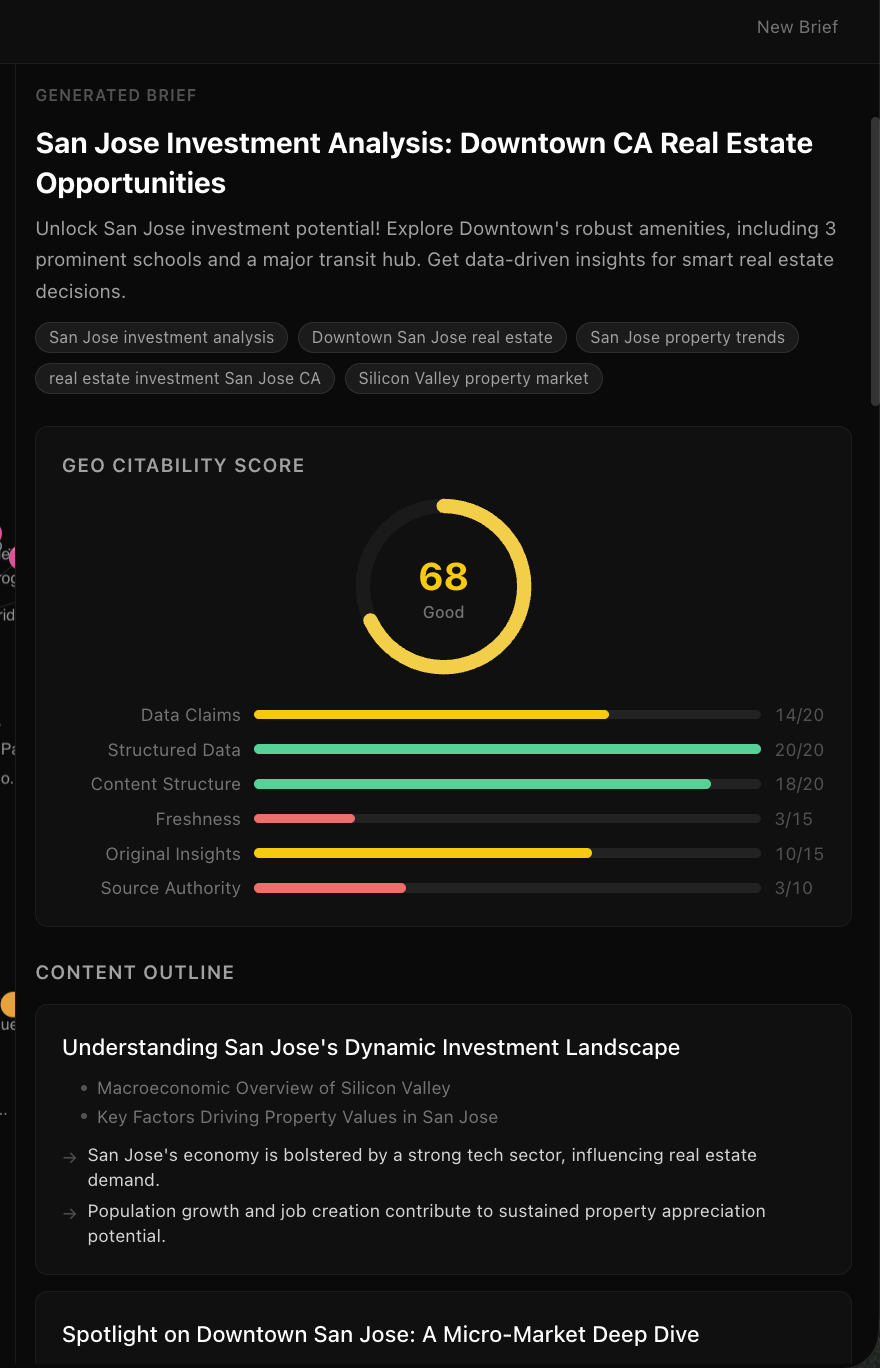
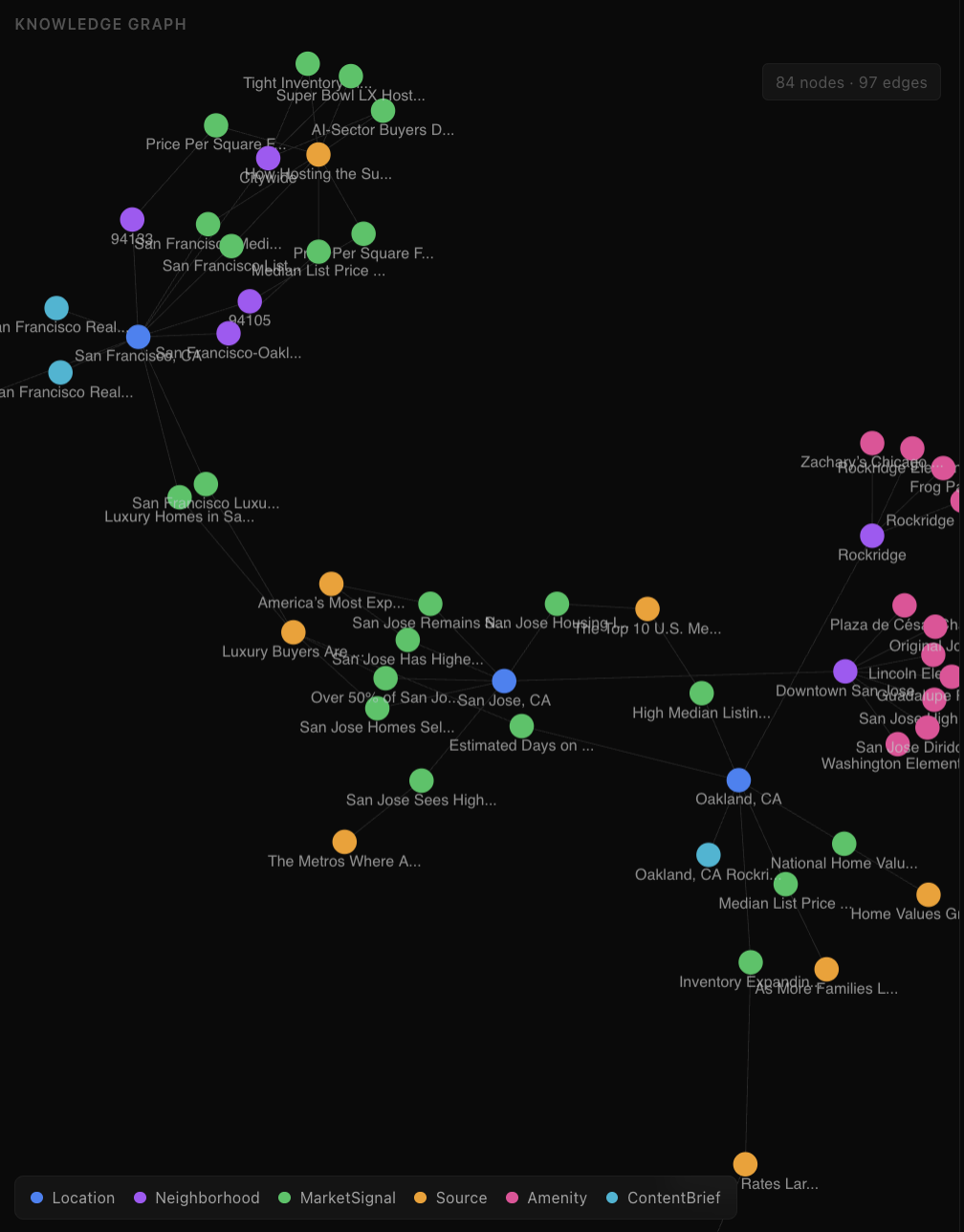
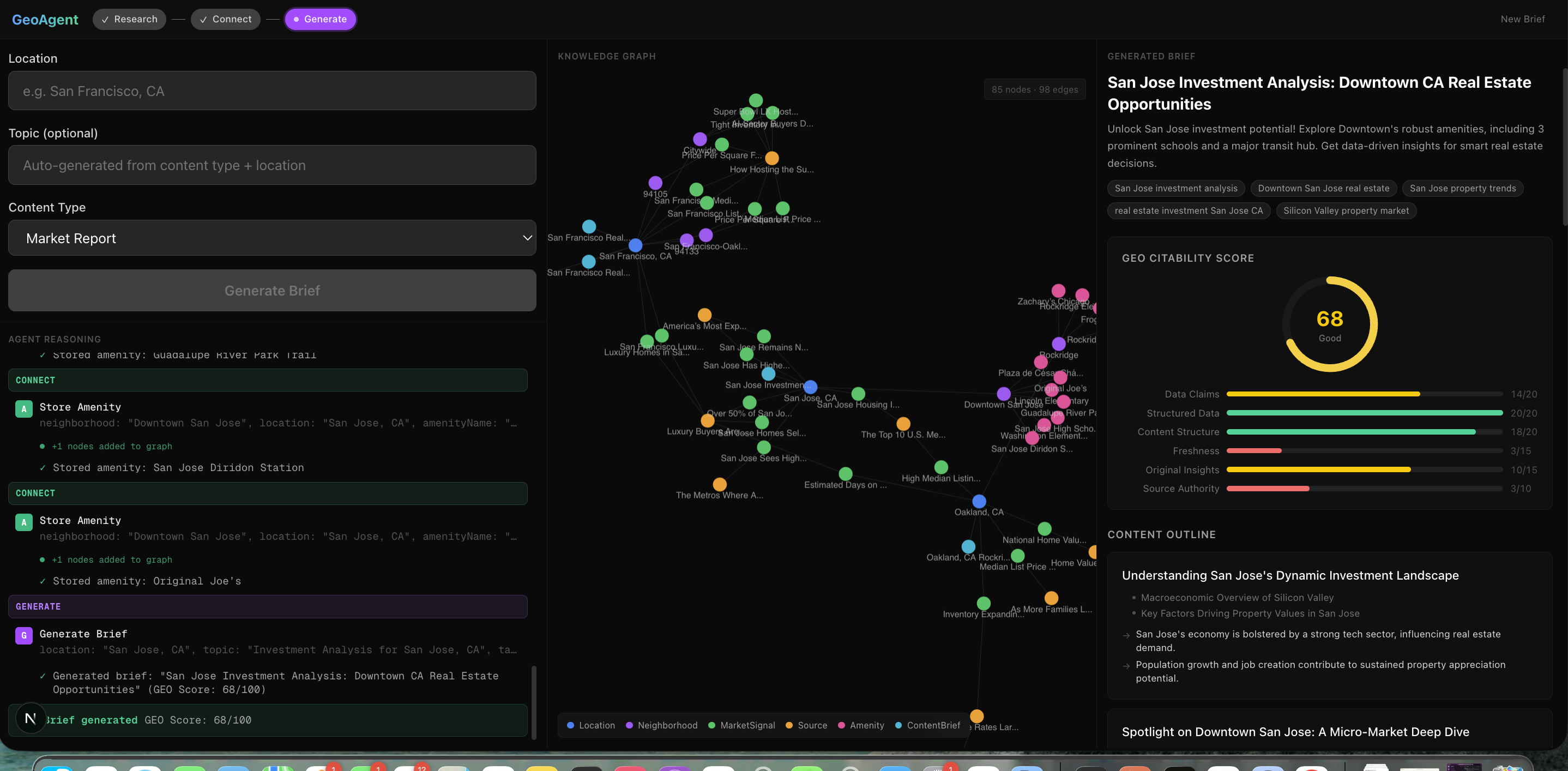
GeoAgent is an autonomous AI agent that takes a location and content type (market report, investment analysis, neighborhood guide, or buyer guide) and produces a complete, GEO-optimized content brief in about 60 seconds. It searches live market data through Tavily, stores every finding in a Neo4j knowledge graph, and generates a structured brief with data-backed claims, source attribution, FAQ sections, JSON-LD schemas, and a deterministic GEO citability score (0-100) across six dimensions. The knowledge graph persists — every run makes the next one smarter. The agent tracks which sources were most productive, what its average score is, and which dimensions are weakest, then adjusts its strategy on the next run.
How we built it
We used a dual-LLM architecture: Grok (xAI) handles agent reasoning and autonomous tool calling — it decides what to research and when. Gemini (Google) handles content generation — it writes the actual brief. Tavily powers real-time web search filtered to authoritative real estate domains and deep content extraction from promising URLs. Neo4j AuraDB stores the persistent knowledge graph with 6 node types (Location, Neighborhood, MarketSignal, Source, Amenity, ContentBrief) and 7 relationship types. The agent has 7 tools it calls autonomously across three phases: Research, Connect, Generate. The frontend is Next.js 15 with SSE streaming so you watch the agent reason in real-time, a force-directed graph visualization that grows as nodes are added, and a brief viewer with the GEO score gauge. We built deterministic GEO scoring (no LLM in the scoring loop) across six dimensions: data-backed claims, structured data, content structure, freshness, original insights, and source authority.
Challenges we ran into
Our initial Neo4j Sandbox instance expired mid-build, and the Bolt protocol connection kept responding with HTTP errors. We tried five different URI formats before switching to AuraDB Professional, which connected on the first try. Getting the agent loop stable was another challenge — when tool calls failed, Grok would fall into repeated apologetic "thinking" messages instead of recovering. We had to add forced brief generation after max iterations and graceful error handling so the pipeline always completes. Balancing two LLMs (Grok for reasoning, Gemini for generation) required careful prompt engineering to make sure Grok calls the right tools in the right order and Gemini outputs valid JSON that parses cleanly.
Accomplishments that we're proud of
The self-improvement loop actually works. Run it for San Francisco, then run it for Oakland — the agent finds existing Bay Area data in the knowledge graph and the system prompt dynamically includes preferred sources from the first run. The second brief is richer because the agent's context got richer. We're also proud of the GEO scoring algorithm — it's fully deterministic, scores six real dimensions, and produces scores (typically 70-80) that meaningfully differentiate well-structured briefs from weak ones. And the whole thing streams in real-time: you watch the agent think, see the knowledge graph grow node by node, and get a complete brief with JSON-LD schemas, sourced claims, and a citability score — all in about 60 seconds.
What we learned
Context engineering is more than just prompt engineering — it's about building systems where the agent's context improves over time through persistent memory, feedback loops, and accumulated knowledge. We learned that Neo4j's graph structure is perfect for this because real estate data is inherently relational (neighborhoods connect to schools, signals, amenities, and sources), and the agent can traverse those relationships to find cross-references that flat retrieval misses. We also learned that GEO is a genuinely underserved space — there are hundreds of SEO tools but almost nothing that helps content teams optimize for AI search engines specifically.
What's next for GeoAgent
Three priorities. First, auto-publish — connect to CMS platforms (WordPress, Webflow) so a brief becomes a live article with one click, complete with embedded JSON-LD and FAQ markup. Second, citation monitoring — track whether published content actually gets cited by ChatGPT, Perplexity, and Google AI Overviews, closing the feedback loop with real-world data. Third, expanding beyond real estate — the GEO scoring engine, knowledge graph architecture, and self-improving agent loop are domain-agnostic. Healthcare, finance, and travel all have the same problem: businesses producing content that AI engines ignore. GeoAgent can be the platform that fixes that for any vertical.


Log in or sign up for Devpost to join the conversation.