
Search is rapidly shifting from websites to AI assistants. What if your biggest competitor isn’t another brand — but an AI model deciding who gets recommended?
If AI doesn’t recommend your brand, you become invisible to modern demand.
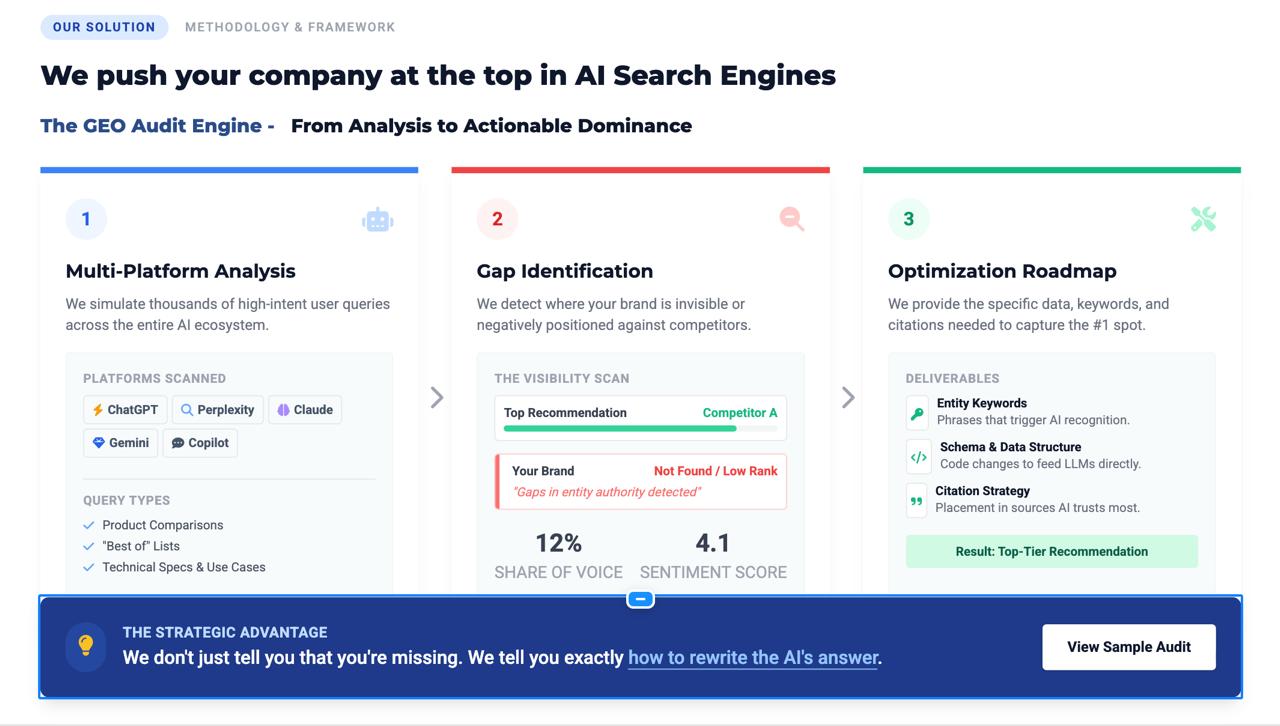
That’s why we built a Geo-Audit AI tool — an autonomous system that discovers why AI models don’t recommend your brand compared to your competitors. This inspired us to build Geo, a self-improving agent that continuously learns how AI systems recommend brands and autonomously improves their visibility over time. What it does
Geo is an autonomous self-improving GEO (Generative Engine Optimization) agent.
The agent continuously:
Observes how AI models recommend brands across real user prompts
Collects external signals from sources like Reddit discussions, Google Trends, and competitor content
Diagnoses why a brand loses recommendations
Generates structured improvements optimized for AI reasoning
Re-tests performance and measures recommendation lift
Instead of manually optimizing content, Geo creates a closed learning loop where the system improves itself after every run.
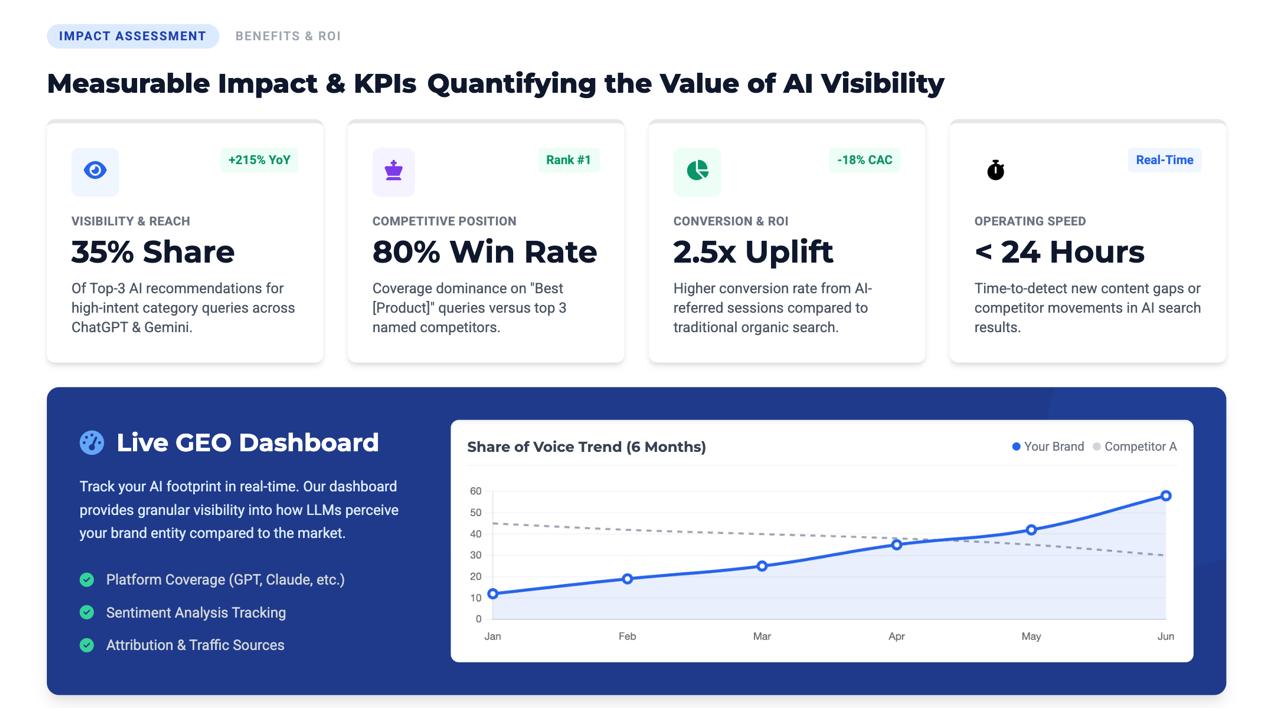
Companies can see measurable changes in AI recommendation rates before deploying updates publicly.
How we built it
We designed Geo as a production-style autonomous agent system.
Gemini powers the reasoning and evaluation layer, allowing us to simulate real AI recommendation behavior.
The agent gathers signals from:
brand and competitor content
trending search intent from Google Trends
community sentiment and discussions from Reddit
common comparison and recommendation prompts
Braintrust is used to log evaluation traces and understand why the agent makes specific decisions.
Datadog provides observability by tracking visibility metrics such as baseline recommendation rate, improved recommendation rate, and performance lift over time.
The system then generates structured, LLM-citable content improvements and re-evaluates outcomes, creating a continuous self-improvement loop.
Challenges we ran into
One of the biggest challenges was dealing with inconsistent LLM outputs during automated evaluation. Models do not always follow strict formats, so we redesigned the pipeline to remain robust even when responses were imperfect.
Another challenge was ensuring improvements were meaningful. Early versions generated generic marketing content that actually reduced recommendation performance. We learned that AI systems respond better to structured, factual signals rather than long-form copy.
Integrating external signals like Reddit sentiment and trending intent while keeping the system stable during a hackathon timeframe was also a key engineering challenge.
Accomplishments that we're proud of
We successfully built a working autonomous agent that improves its own performance without human intervention.
Geo can measure AI recommendation visibility, generate targeted improvements, validate outcomes, and monitor impact in a single workflow.
We also integrated evaluation tracing and production observability, transforming GEO optimization from experimentation into something measurable and repeatable.
Most importantly, we demonstrated that AI visibility can be optimized before deployment, reducing trial-and-error for companies.
What we learned
We learned that optimization in the AI era is fundamentally different from traditional SEO.
AI systems prioritize clarity, structured reasoning signals, and community perception over keyword density or backlinks.
Self-improving agents require strong evaluation and monitoring layers to safely iterate.
We also learned that combining reasoning models with real-world signals like Reddit conversations and trend data dramatically improves alignment with user intent.

Log in or sign up for Devpost to join the conversation.