-
-
All Set
-
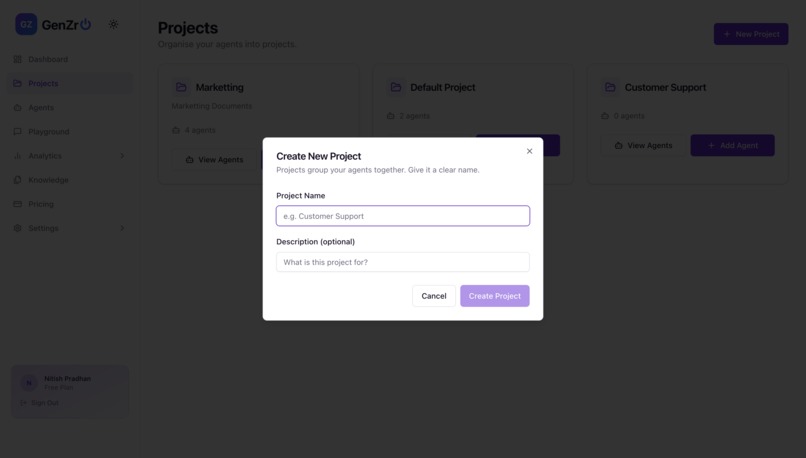
Creating the project
-
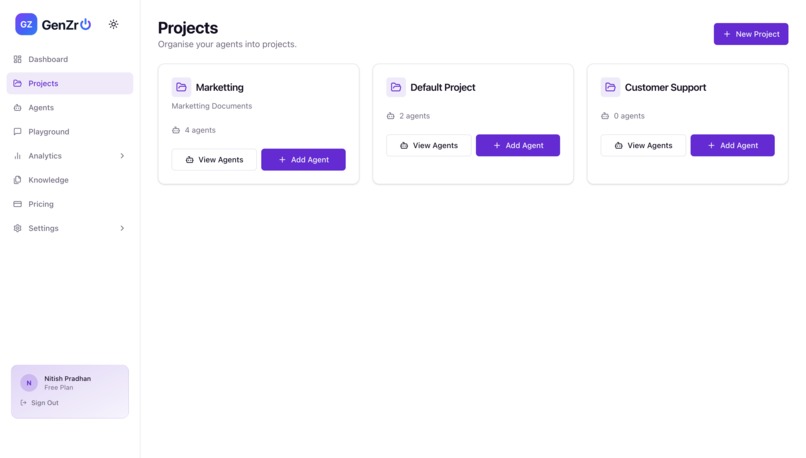
1st Step- Create the Project
-
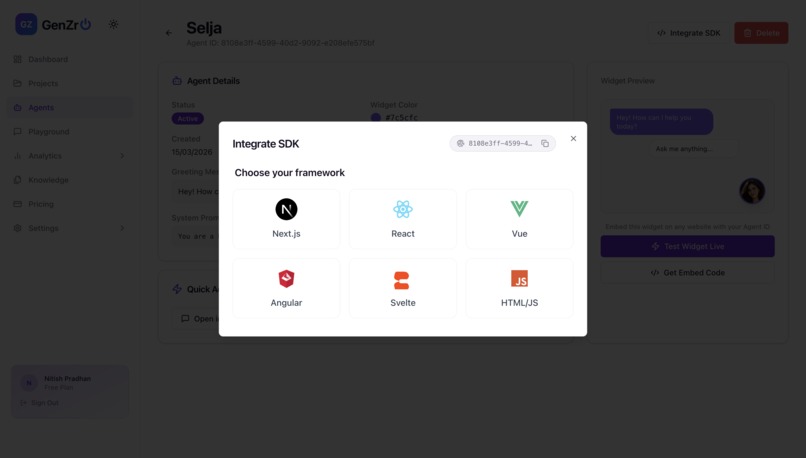
Deployment of Agents
-
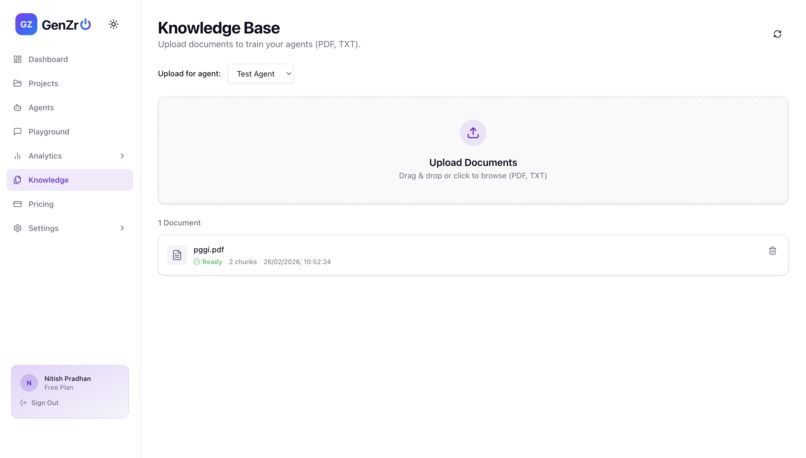
3rd Step- Provide the Knowledge to Agent
-
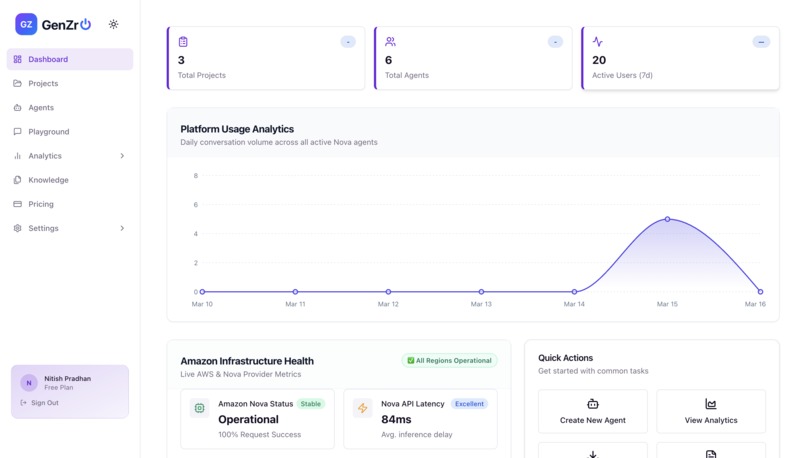
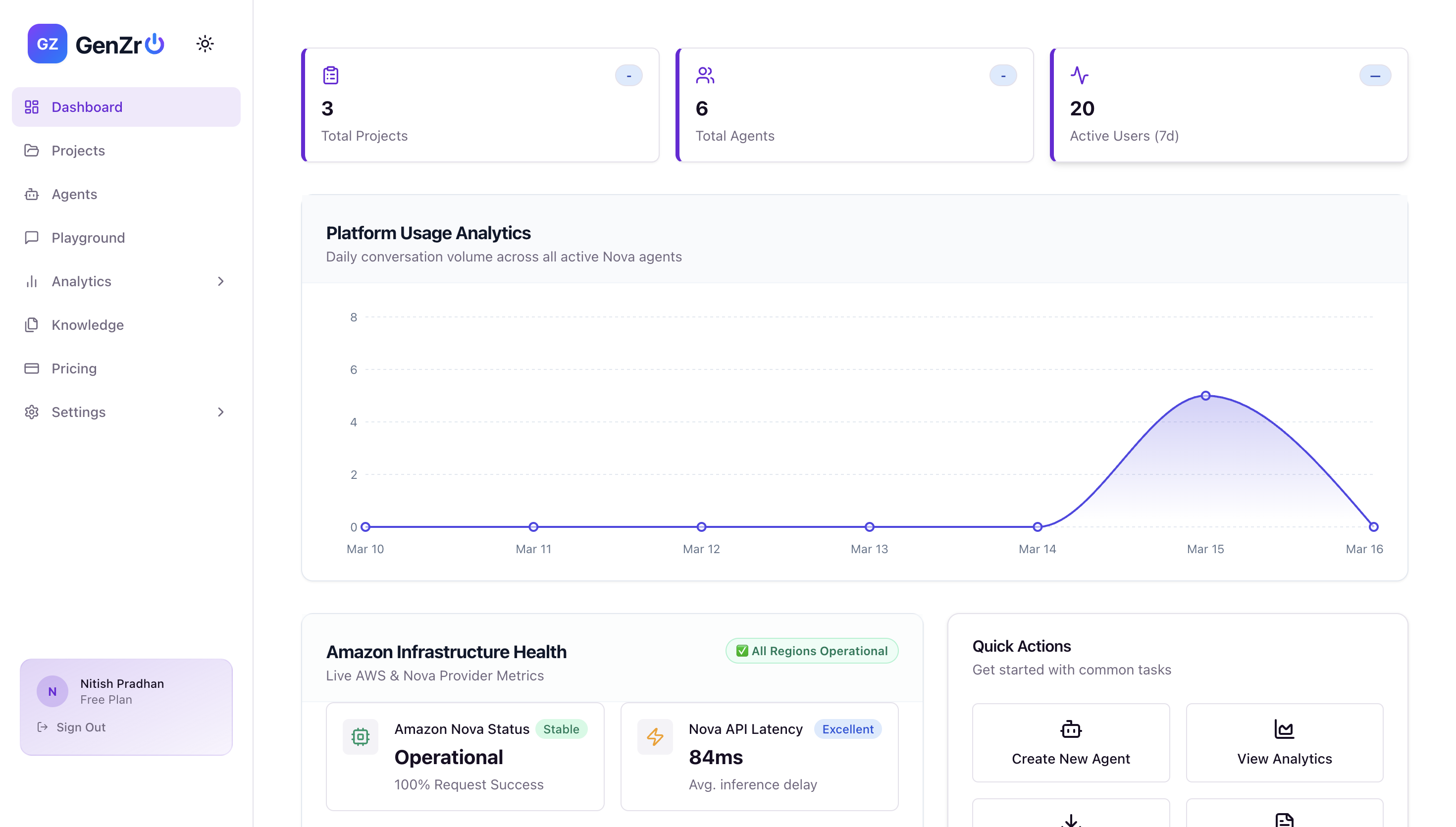
Home Page
-
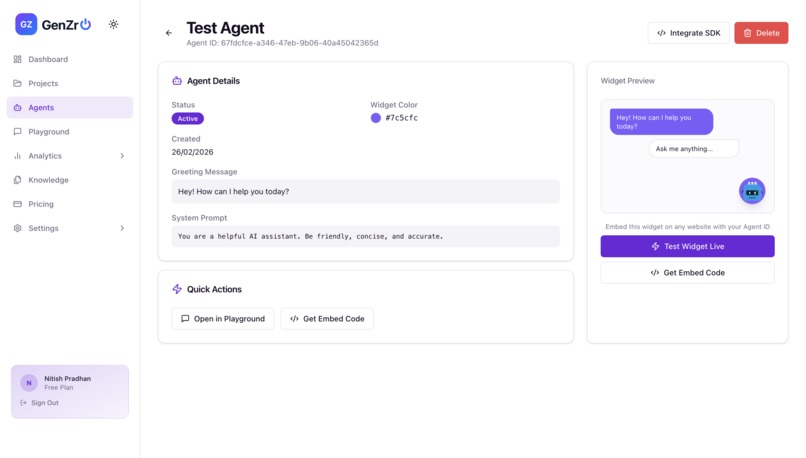
Agent is ready
-
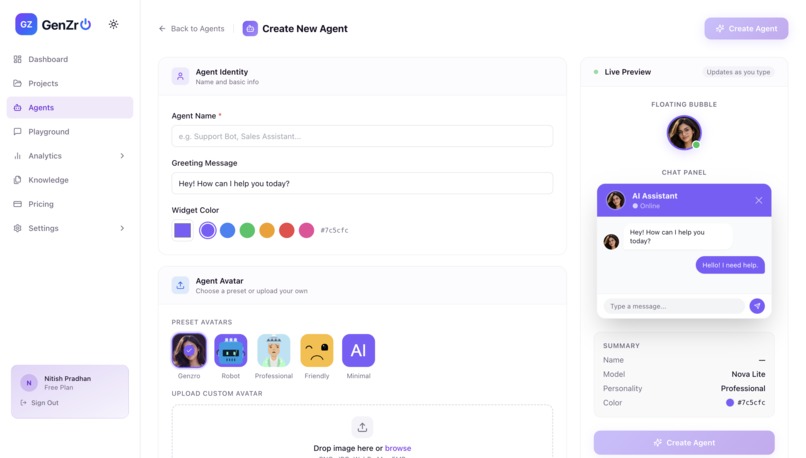
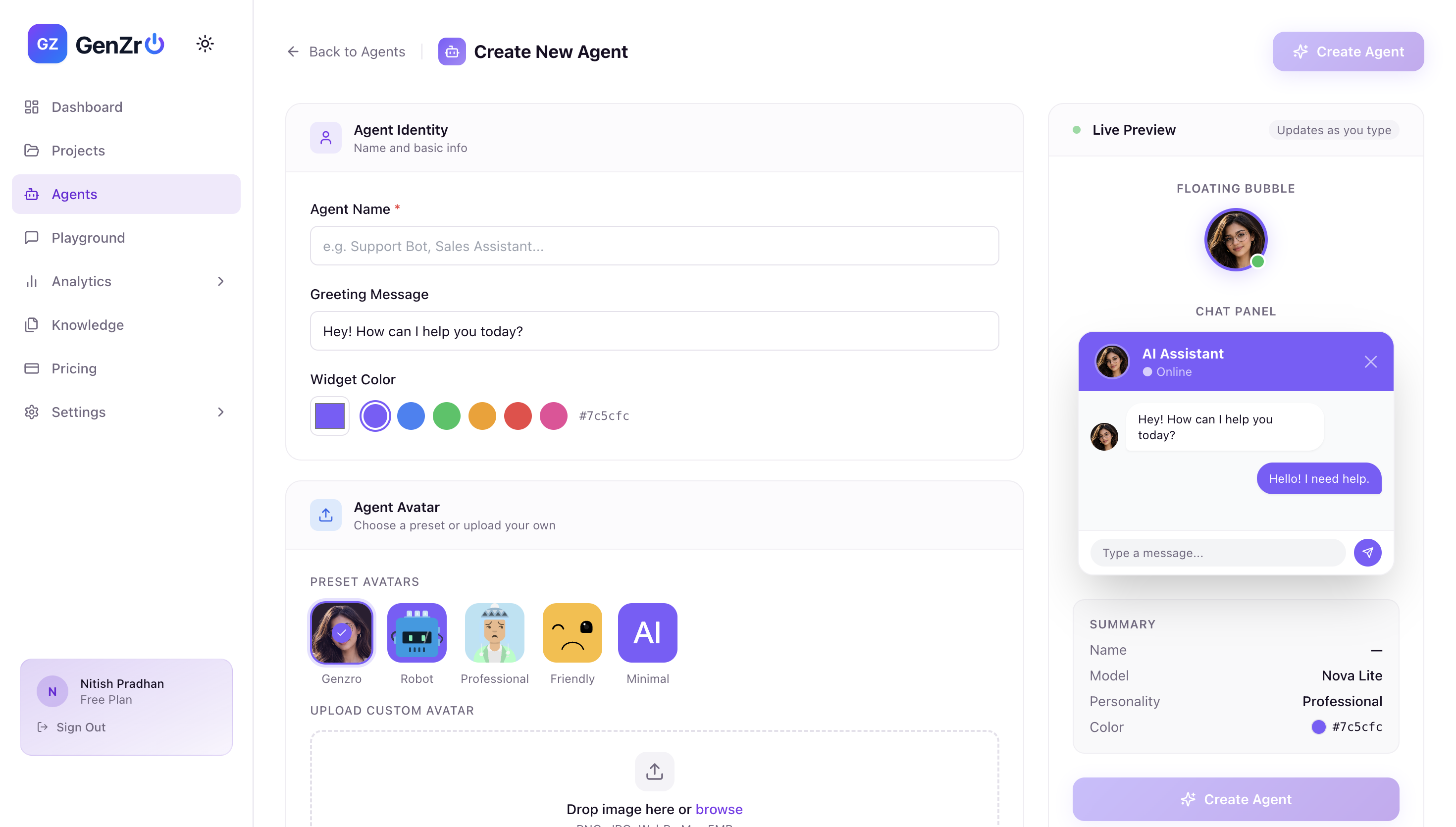
2nd Step- Create the Agent
-
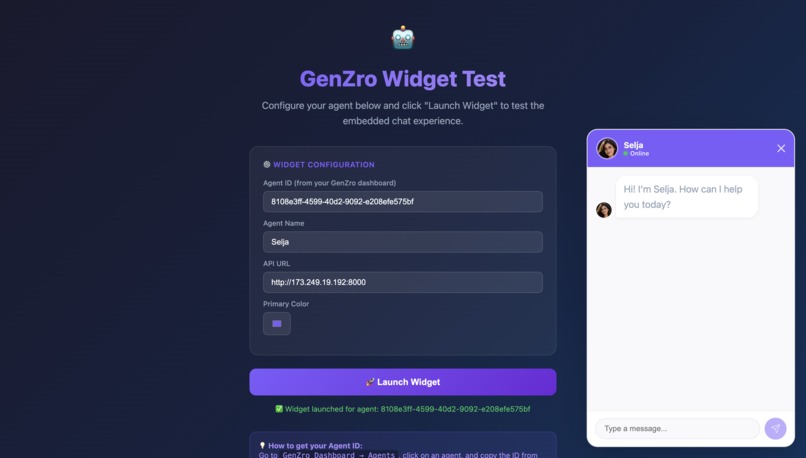
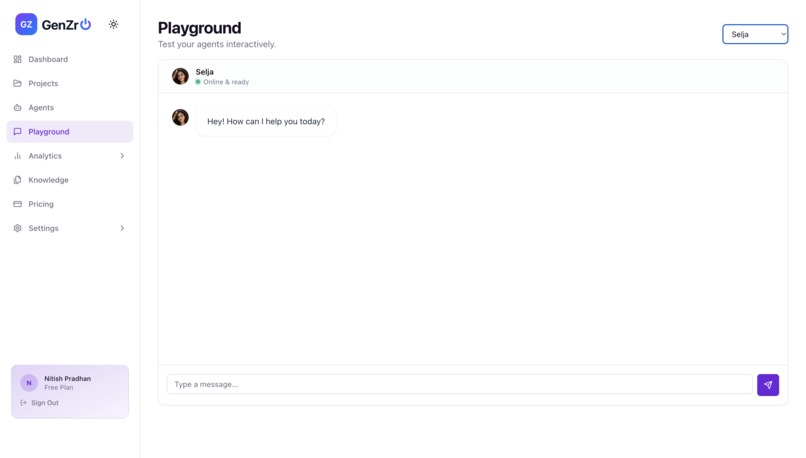
Testing the Agent-Live
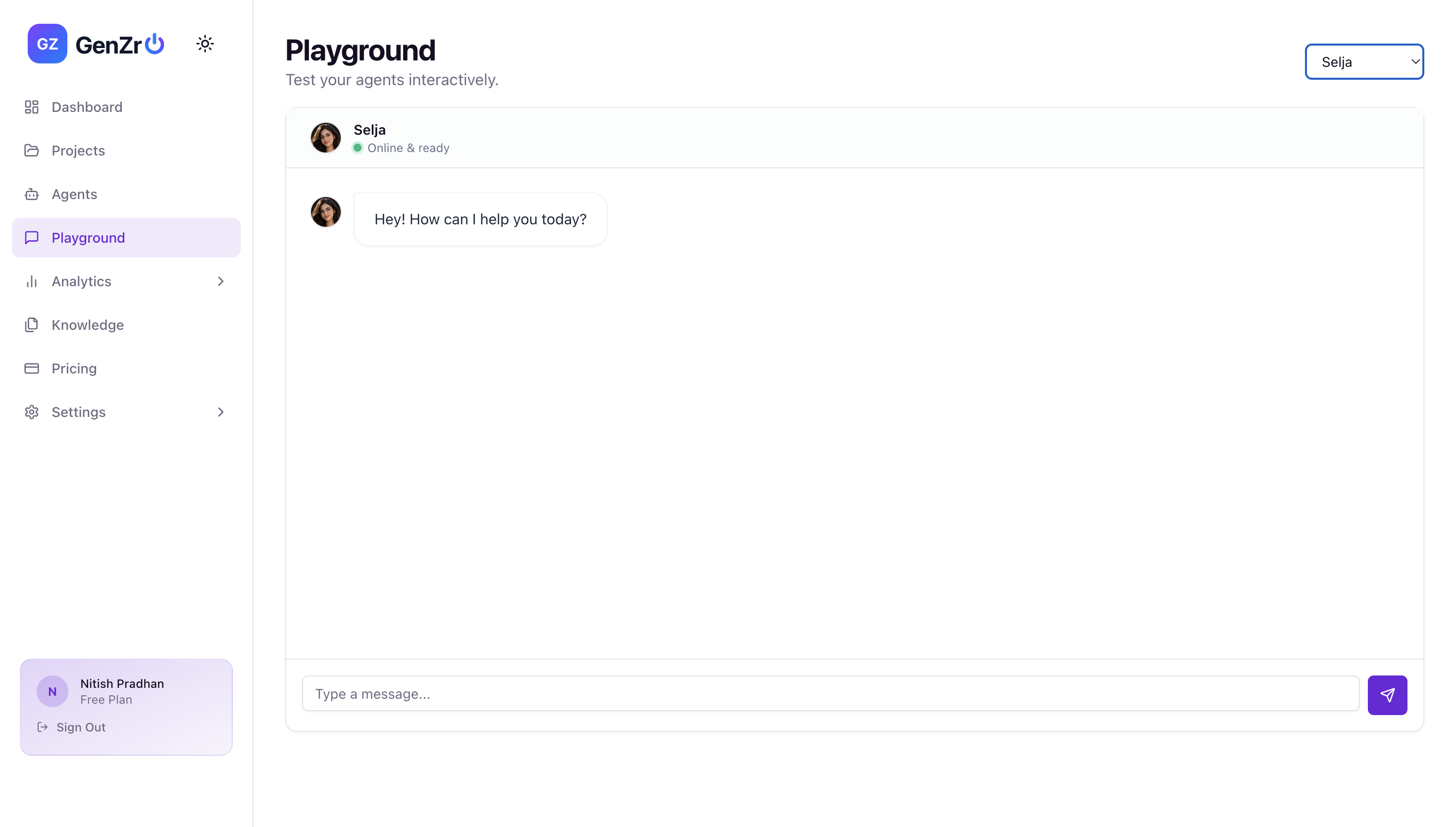
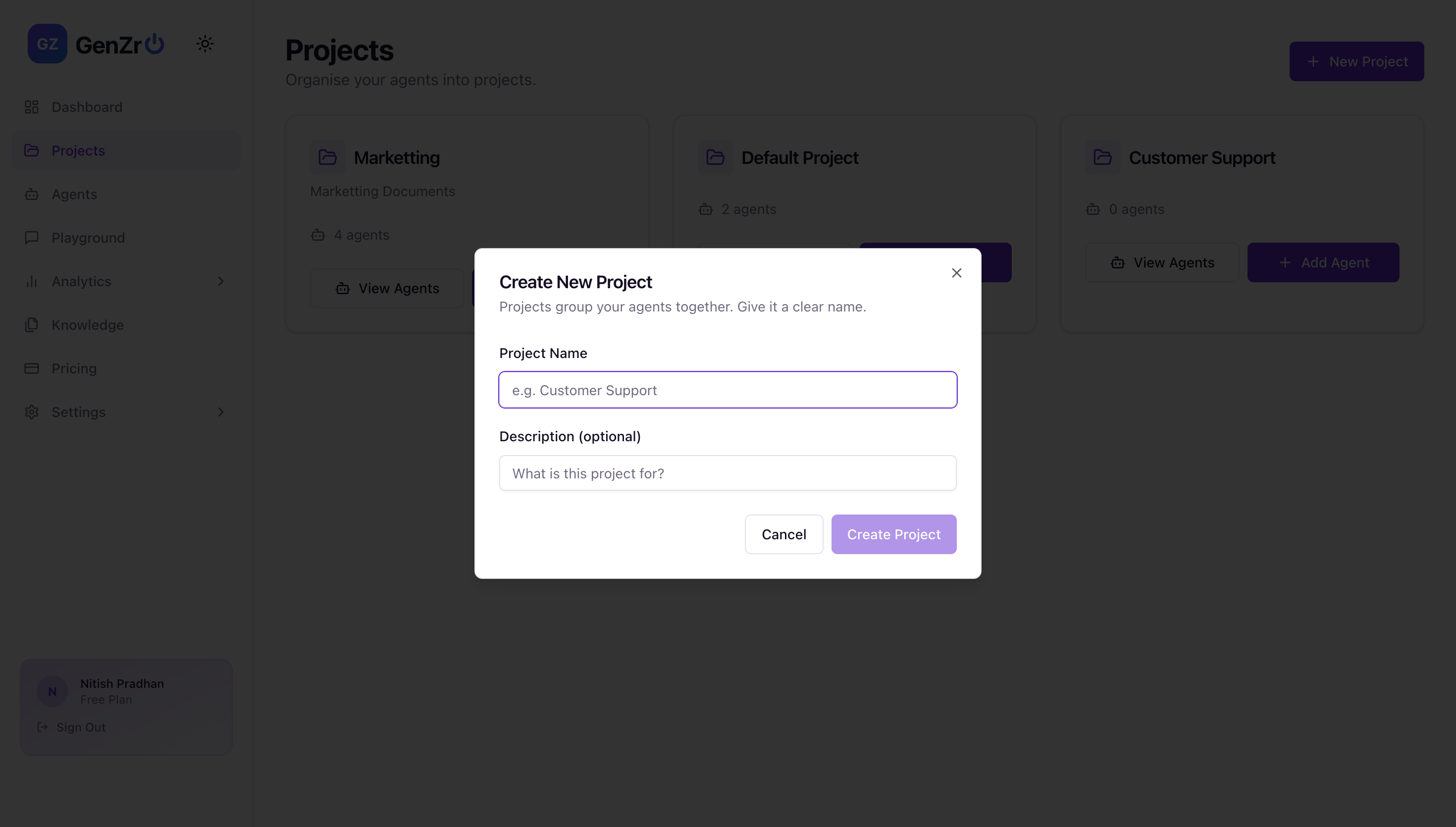
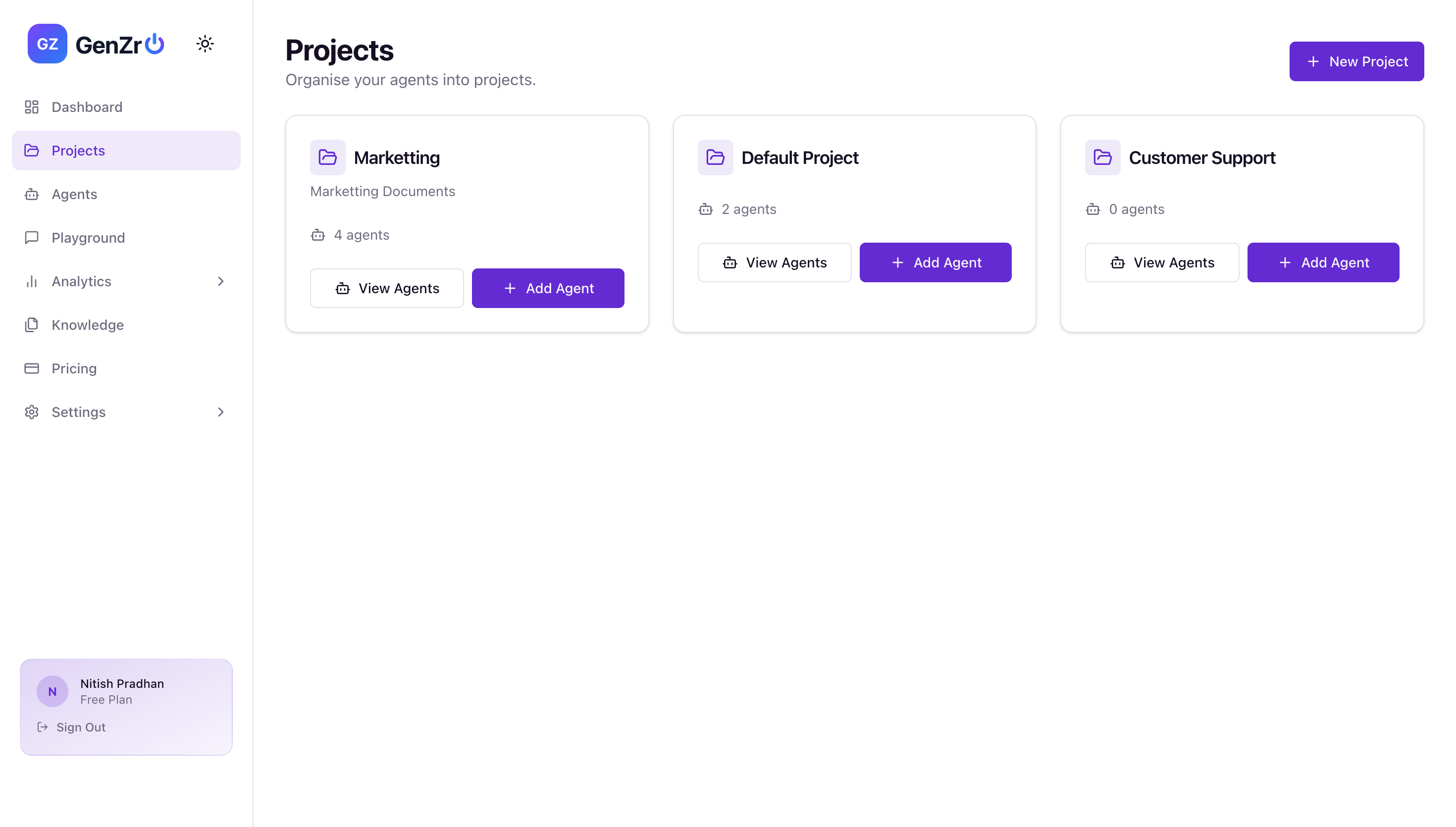

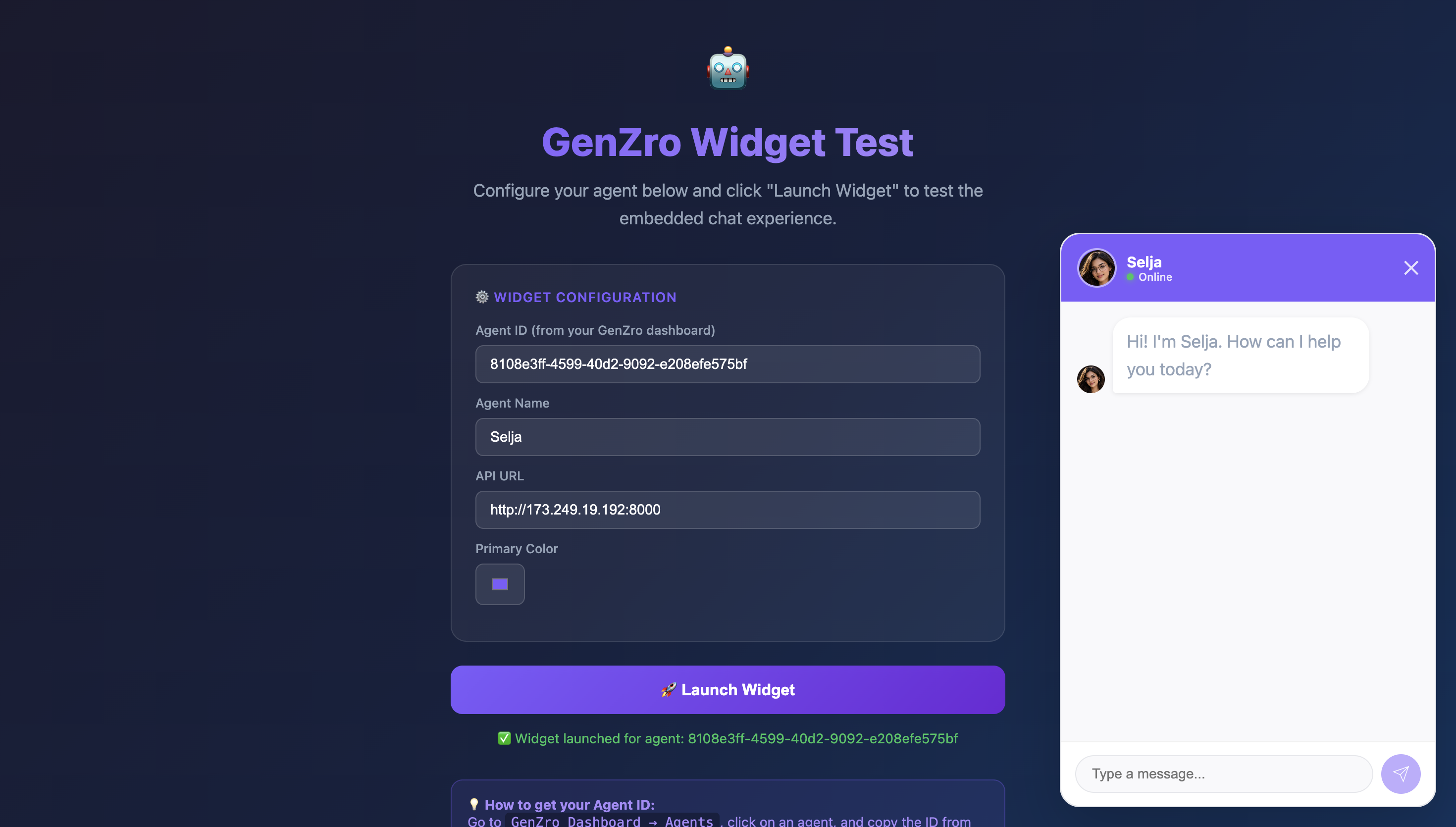
Inspiration
Many SaaS products are difficult for new users to understand. When someone opens a product for the first time, they often feel confused. They don’t know where to click, how the system works, or what the policies are.This creates frustration and a poor user experience. To solve this problem, we built GenZro.
What it does ?
we built the ZenZro zero-code AI agent platform.And the best part — business can create, train and deploy the UI AI agent in less time than it takes to cook a bowl of Maggi.
For admins: A premium dashboard where you create agents with custom personalities, upload documents to build a knowledge base (RAG), select the right Amazon Nova model for each agent, monitor conversations, and track cost per model.
For end users: A lightweight chat widget (under 50KB) that embeds on any website with a single script tag. Visitors interact with the AI agent in real time, with streaming responses powered by Amazon Nova via Bedrock.
Under the hood: When a user asks a question, the platform embeds the query using Amazon Titan, performs a semantic search against the agent's knowledge base stored in PostgreSQL with pgvector, retrieves the most relevant document chunks, and feeds them as context to Amazon Nova for a grounded, accurate response.
Each agent can be independently configured with Nova Lite (balanced), Nova Micro (fast and cheap), or Nova Pro (highest accuracy), allowing businesses to optimize cost and quality per use case.
How we built it
Backend: Python with FastAPI. Amazon Bedrock serves as the unified LLM gateway using the Converse API with streaming support. Amazon Nova handles all text generation. Amazon Titan Embed Text v2 generates 1024-dimensional vectors for the RAG pipeline. LangChain orchestrates the document processing and retrieval chain. PostgreSQL with pgvector stores all relational data and vector embeddings in a single unified database.
Frontend Dashboard: Next.js with React. A full admin panel with agent management, knowledge base uploads, analytics dashboards, cost tracking with per-model breakdowns, and system health monitoring.
Chat Widget: Vite with Preact. Compiles into a single IIFE JavaScript bundle that customers embed with one script tag. Preact keeps the bundle under 50KB while supporting real-time streaming, custom themes, and branded avatars.
Infrastructure: Docker Compose for local development with PostgreSQL and MinIO (S3-compatible). The architecture maps directly to production AWS services — Amazon RDS for PostgreSQL, Amazon S3 for storage, Amazon Bedrock for AI.
Challenges we ran into
Hallucination in RAG responses. When the knowledge base lacked relevant information, Nova would confidently generate incorrect answers. We solved this by implementing cosine similarity score thresholds — if the best matching document chunk scores below 0.7, the agent responds with "I don't have enough information" instead of fabricating an answer. Combined with low temperature settings (0.1 to 0.3) and strict system prompts, this dramatically reduced hallucination.
Embedding model migration. We prototyped with OpenAI embeddings (1536 dimensions) but needed to migrate to Amazon Titan (1024 dimensions) for the AWS-native architecture. This required re-embedding every document and rebuilding the pgvector indexes — essentially a full pipeline rebuild mid-development.
Widget bundle size. The first version of the chat widget was 180KB — far too heavy for embedding on customer websites. By switching from React to Preact and applying aggressive tree-shaking with Vite, we reduced it to under 50KB.
Multi-tenant vector isolation. Ensuring that one agent's RAG queries never accidentally retrieve another agent's documents was critical. We implemented metadata-filtered vector searches scoped by project ID at the database level.
Accomplishments that we are proud of
We built a production-grade, multi-tenant AI agent platform in a single hackathon cycle — not a demo, but a working system with authentication, role isolation, analytics, and cost tracking.
The embeddable widget is genuinely lightweight. Under 50KB, loads in milliseconds, works on any website, and streams responses in real time. It feels native, not bolted on.
What we learnt
Hallucination is not just a model problem — it is a system design problem. The right combination of similarity thresholds, temperature control, and prompt engineering makes RAG reliable. No single technique works alone; you need all three.
pgvector is production-ready. We initially assumed we would need a dedicated vector database like Pinecone, but PostgreSQL with HNSW indexes handles millions of vectors with sub-millisecond latency. The simplicity of keeping everything in one database cannot be overstated.
Bundle size discipline matters. When your code runs on someone else's website, every kilobyte is a tax on their users. The Preact migration was painful but worth it.
What's next for GenZro - AI Agent Platform Agentic capabilities. Migrating from LangChain to LangGraph to support multi-step agent workflows — agents that can browse the web, call APIs, query databases, and chain actions together, not just answer questions.
Voice-first agents. Deeper Amazon Polly and Transcribe integration for full voice-in, voice-out conversational agents — enabling phone and smart speaker deployments.
Built With
- amazon-nova-lite
- amazon-nova-micro
- amazon-nova-pro
- amazon-polly
- amazon-s3-frameworks:-fastapi
- amazon-titan-embed-text-v2
- boto3
- javascript
- jwt
- langchain-databases:-postgresql
- languages:-python
- minio
- next.js
- pgvector-other-technologies:-docker
- preact
- react
- sql-aws-cloud-services:-amazon-bedrock
- sqlalchemy
- typescript
- vite



Log in or sign up for Devpost to join the conversation.