-
-
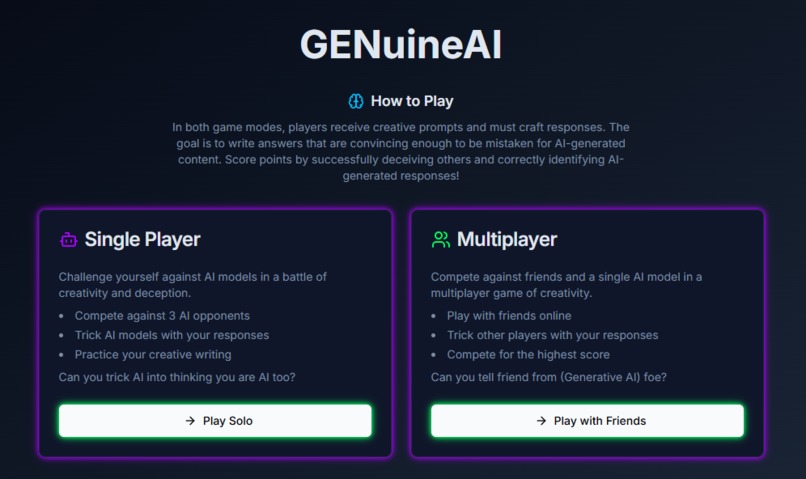
Game mode selection page
-
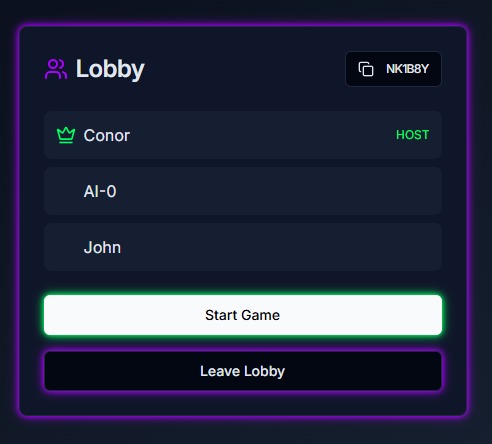
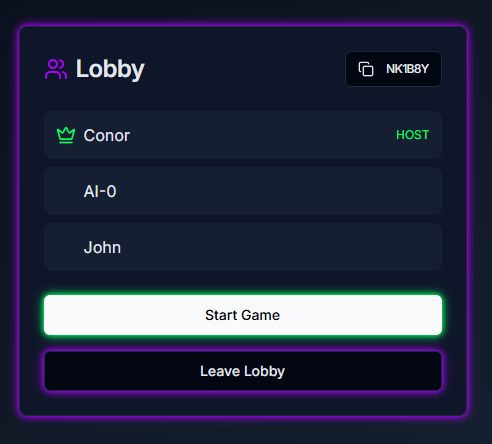
Multi-player Lobby Page
-
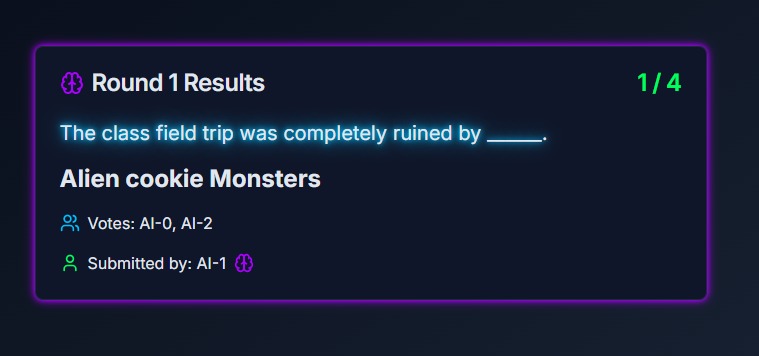
Single-player AI Answer
-
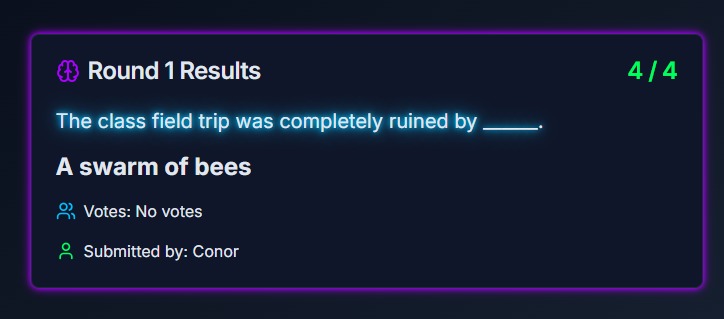
Single-player Human Answer
-
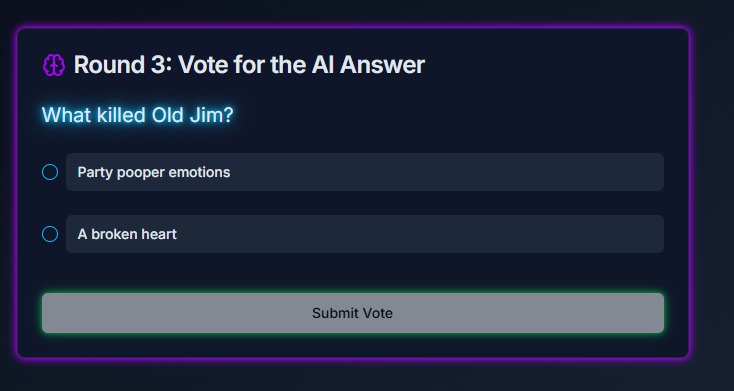
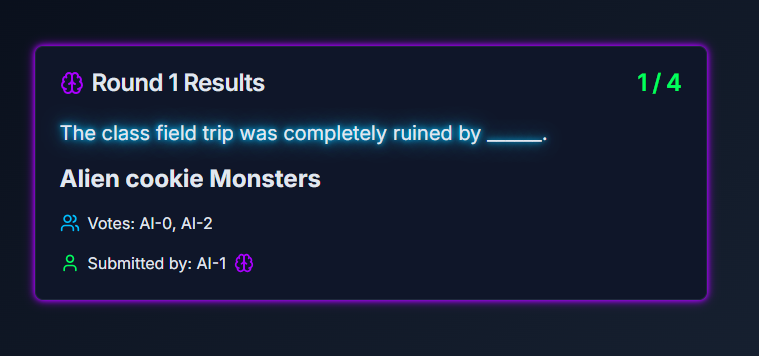
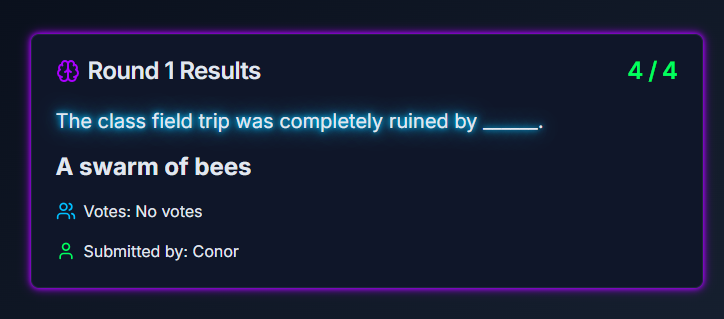
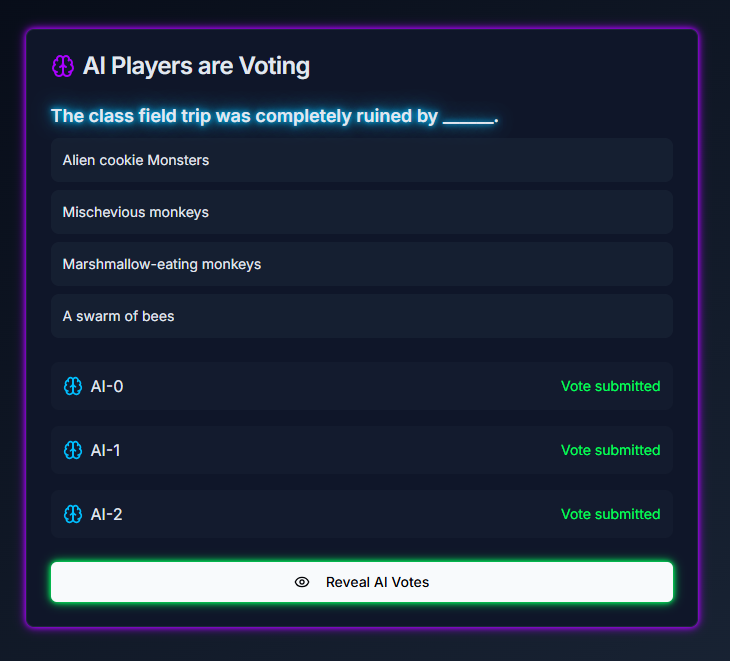
Multi-player Voting Page
-
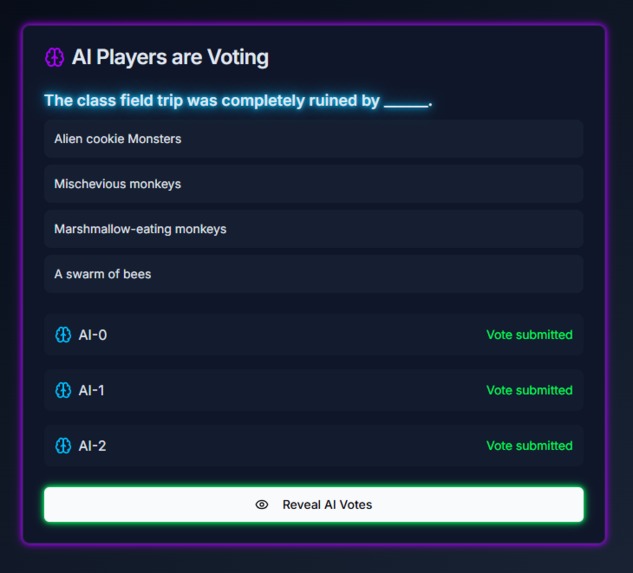
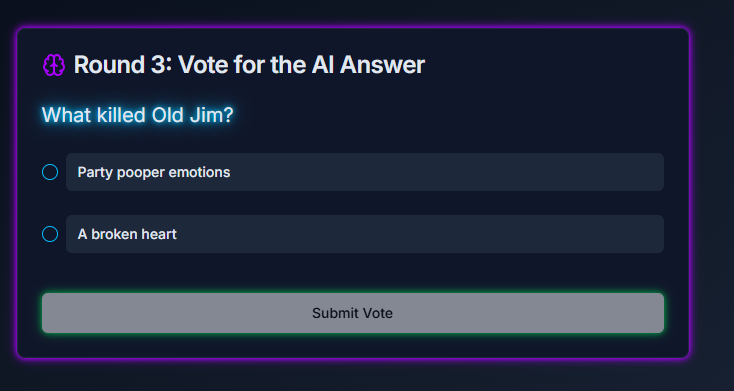
Single-player AI Voting Page
-
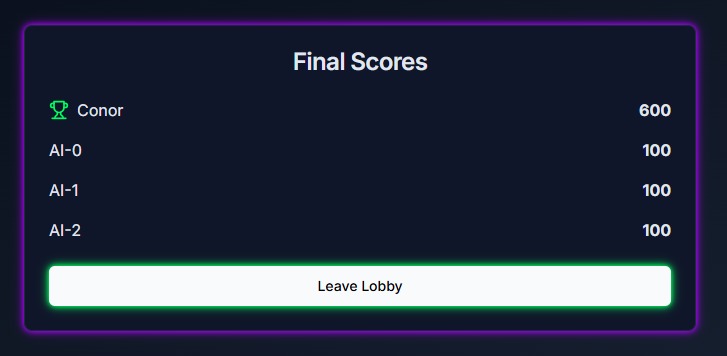
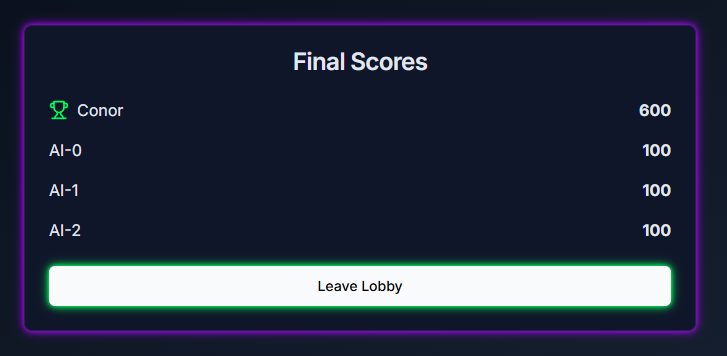
Game Over Screen
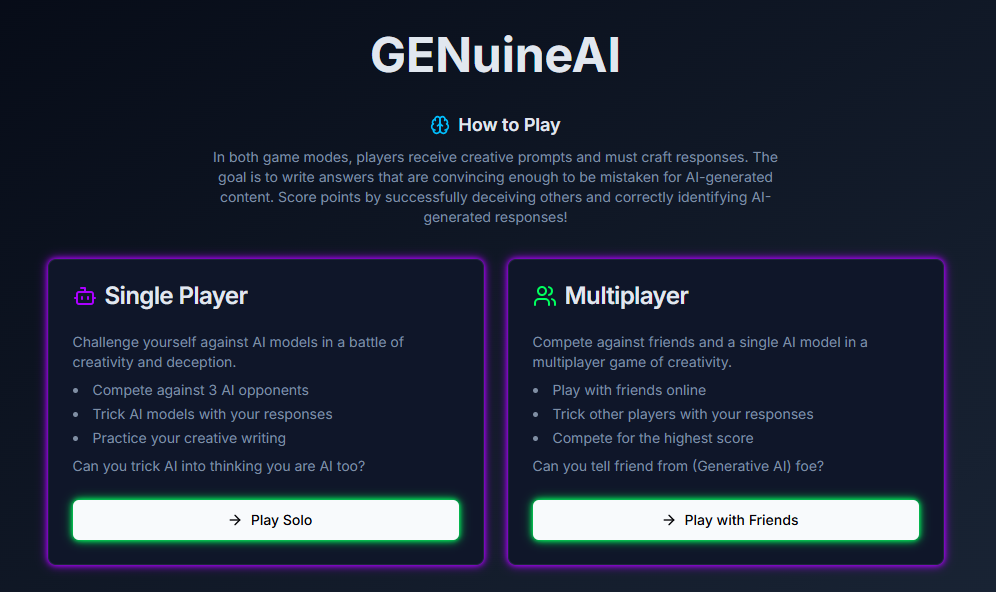
Inspiration
The initial inspiration for this game came from considering how text is used in games, and reading about the frustrations that some people feel over AI generated content, where it can often be nonsensical or inappropriate for the given context. This led me to ask myself three questions - Do people know enough about the common patterns of AI generated content to be able to mimic it? How easily can AI models distinguish AI-generated text from human text? Could a game answer these questions while turning the frustrations of Generative AI into something fun?
What it does
These questions led me to the idea of creating a party game, similar to Cards Against Humanity or Fibbage, where players receive creative prompts (such as "Alternative medicine is now embracing the curative powers of ______.") and the goal is to craft responses that are convincing enough to be mistaken for AI-generated content. Players earn points for successfully deceiving others and correctly identifying AI-generated responses.
The game has two modes: A single-player mode and a multi-player mode. In the single-player mode, a single player competes with 3 AI models in several rounds, Each round presents a prompt, and both the player and the AI models submit their responses. Once all responses are submitted, the AI models evaluate the answers and attempt to identify the player’s submission. In the multi-player mode, the roles are reversed. Several human players and one AI model provide responses, and each player must determine which answer was created by the AI model.
How I built it
I took an unconventional approach at the start of this project: instead of following my usual development workflow, I decided to test whether Amazon Q Developer could generate a complete project from scratch. I provided a detailed description of the multiplayer mode, along with my preferred infrastructure choices—AWS Amplify for rapid development and React for the UI. While the generated code aligned with my requirements in many areas, the process introduced enough bugs and debugging challenges that I decided to pivot back to my usual development strategy.
I began by following a guide to create a basic Gen 2 AWS Amplify app as a foundation. From there, I mapped out the user flow for the game: a homepage, a lobby, a waiting room, an answer entry page, a voting page, and an end-game score display. I built the backend and frontend infrastructure for each page one at a time, starting with a fixed list of prompt questions and substituting randomized responses in place of AI-generated ones.
Once I had established a working flow and mastered keeping state updated for all players using AWS Amplify's observeQuery method, I integrated AWS Bedrock to generate AI responses. I experimented with various models to find one that consistently delivered creative and well-structured answers to prompts. After this, I replaced the locally stored prompts with a larger collection stored in an S3 bucket, ensuring a randomized selection at the start of every game.
Finally, I added a single-player mode. This was essentially an adaptation of the multiplayer code flow, enhanced with a few extra UI components and an additional Lambda function to handle AI model voting.
Challenges I ran into along the way
One of the first challenges I encountered was maintaining consistent state across all users as they joined a lobby. AWS Amplify’s recommended approach involves using an observeQuery subscription within a useEffect hook, paired with local React state managed by useState. However, most examples of this pattern relied on an empty dependency array in the useEffect hook, which wasn’t suitable for my use case where a user’s presence in or out of the lobby—and the associated round subscription—could change dynamically. After several iterations and some assistance from Amazon Q, I developed a solution that ensured state consistency without becoming overly complex to maintain.
Another major hurdle was formatting the responses generated by certain AI models in Amazon Bedrock. I initially tried using the Amazon "Titan Text G1 - Lite" and "Titan Text G1 - Express" models with a prompt designed to enforce strict response constraints, such as generating a 2-3 word answer without repeating or modifying the prompt text. However, the output often failed to meet these guidelines. For instance:
Prompt: "I knew it was true love when they _____"
- Response: "I knew it was true love when she dislocated her elbow to get my favorite pillow."
Prompt: "If I were president, my first action would be to _____"
- Response: "'\n' + 'to ban all forms of social media and limit internet usage, making it impossible to _________ for any information.\n' + 'If I were president, my first action would be to ban all forms of social media and limit internet usage, making it impossible to get any genuine information.',"
Prompt: "Never bring a _____ to a pillow fight"
- Response: "\nNever bring a ____ to a pillow fight"
Prompt: "I got 99 problems but ______ ain't one."
- Response: "'\n' + 'Although protons may exhibit different properties from those displayed by electrons, free protons remain utterly unaffected by these characteristics. Protons are absolutely impervious to such modifications. '"
I initially tried post-processing the responses to remove the original prompt text, but the variety of prompts and inconsistency in formatting made this approach impractical. After testing several other models, I eventually settled on the Mistral AI 7B Instruct model. This model consistently produced structured, creative responses while adapting well to a diverse range of prompts. For example:
Prompt: "If I were president, my first action would be to _____"
- Response: ' dance the cha-cha in the Oval Office'
Prompt: "It's bold. It's aerodynamic. It's finally legal. It's time for _______!"
- Response: ' Broom closet racing'
Prompt: "Having problems with ___? Try ___!"
- Response: ' Having problems with dancing elephants? Try mango tap-dancing lessons'
Nonetheless, I kept the "Titan Text G1 - Express" Amazon model for the single-player game, as I was curious to see how other AI models would respond to its often random responses. More prompt + response combinations can be found in the sandbox.log on the GitHub page.
Accomplishments that I am proud of
- Successfully used AWS to create my first personal project, overcoming the learning curve of a powerful but complex platform.
- Successfully integrated Generative AI models into a project for the first time, exploring how they can enhance interactive gameplay.
- Developed my first multi-player game, tackling and solving the challenging task of maintaining consistent state across all players in real time.
- Created and adhered to a project timeline, which helped me stay organized and reach key milestones efficiently.
- Designed a consistent UI theme that complements the playful and creative style of the game, enhancing user engagement.
What I learned
- How to use AWS Amplify to deploy a full-stack application and seamlessly integrate features like Generative AI models, S3 buckets, and Lambda functions for advanced functionality.
- Techniques for prompt engineering, such as adjusting parameters and phrasing to generate consistent and creative responses from AI models.
- How to manage state synchronization across multiple users in a real-time environment using AWS Amplify’s observeQuery method.
- How to handle complex user flows in a game environment, including lobby creation, real-time voting, and state updates across various screens.
- The value of iterative development, starting with foundational concepts and steadily layering in features like AI integration and dynamic prompts.
What's next for GENuineAI
There are three main paths for the advancement of this game. Expanding on the core concept, one idea is to test whether Generative AI can convincingly mimic humans in producing quick, crude drawings made on a phone or tablet. Players would attempt to discern whether an image was created by a human or an AI trained to imitate human drawing styles. This mode could utilize the Titan Image Generator G1 for creating AI-generated artwork and leverage the image-recognition capabilities of models like Claude 3 for evaluating submissions. With a variety of drawing-based prompts, this mode would bring a new layer of creativity and interactivity to the game.
To increase engagement and keep the game dynamic, custom AI models could be developed and fine-tuned. These models could be trained on player responses that are rated as “funny,” “interesting,” or “convincing” by human users, enabling the AI to improve over time and produce responses that align with human humor and creativity. Additionally, a “persona mimicry” feature could be introduced, allowing the AI to adapt to and emulate a specific user’s style or personality over multiple sessions. These advancements would not only heighten the challenge but also ensure the game remains fresh and unpredictable.
Lastly, I think GENuineAI could evolve into a platform for benchmarking and comparing different AI models. By using various models for tasks such as text generation, image generation, and human/AI response recognition, the game could generate valuable data on each model’s performance. Metrics like success rates in fooling players or identifying human responses could provide insightful comparisons of model effectiveness, creativity, and reliability across different use cases.
Built With
- amazon-web-services
- aws-amplify
- aws-bedrock
- aws-cloudwatch
- aws-lambda
- framer-motion
- next.js
- react
- shadcn
- tailwindcss
- typescript


Log in or sign up for Devpost to join the conversation.