-
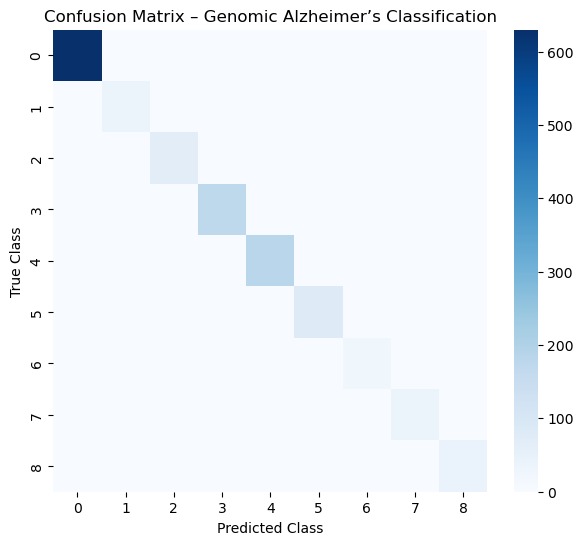
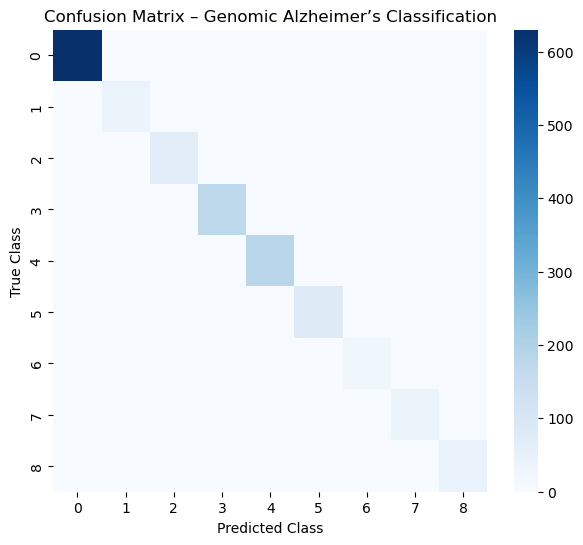
Multi-class confusion matrix showing performance for genomic Alzheimer’s classification.
-
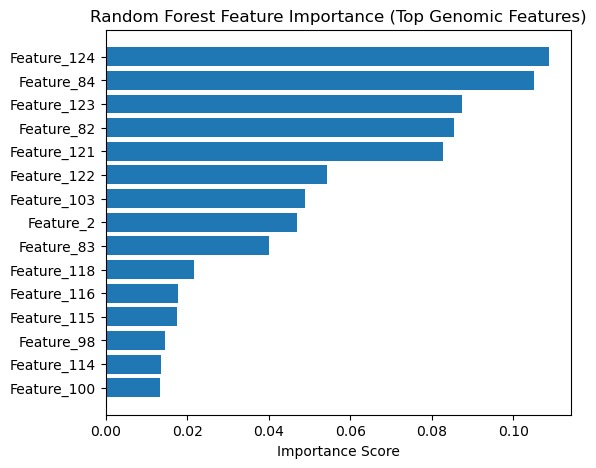
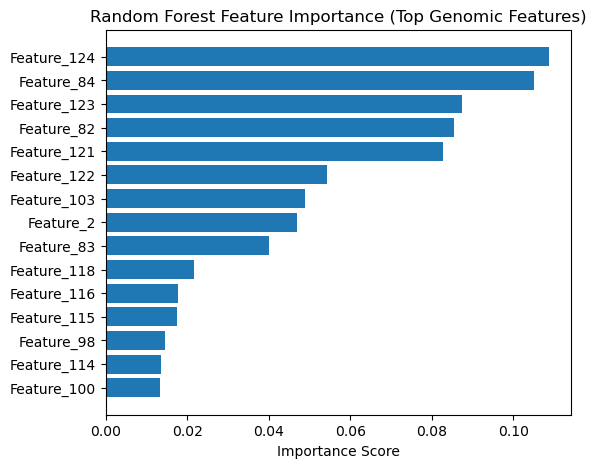
Top genomic features driving Alzheimer’s disease risk stratification in the Random Forest model.
-
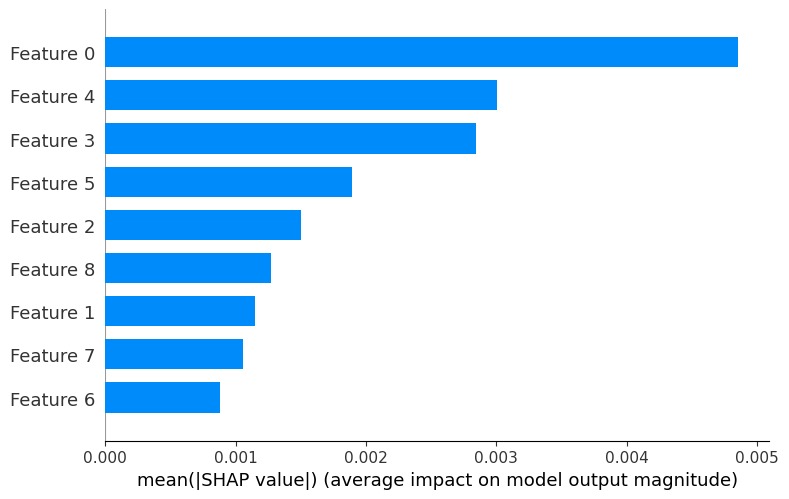
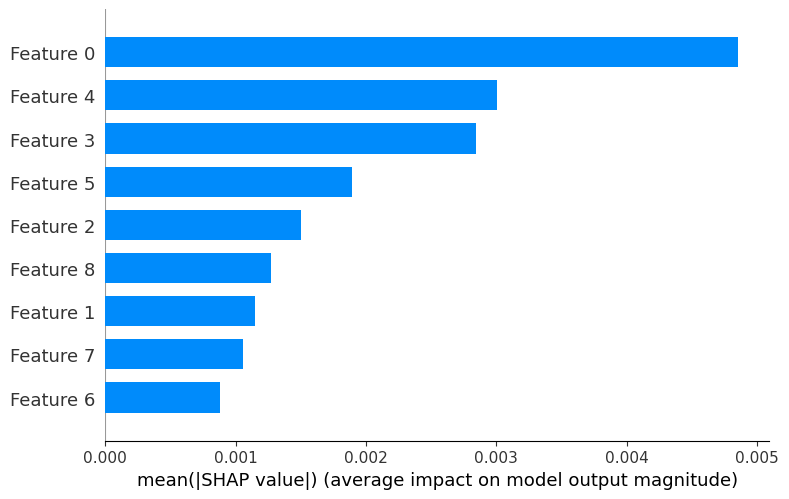
SHAP-based interpretability highlighting genomic features with the strongest impact on model predictions.
-
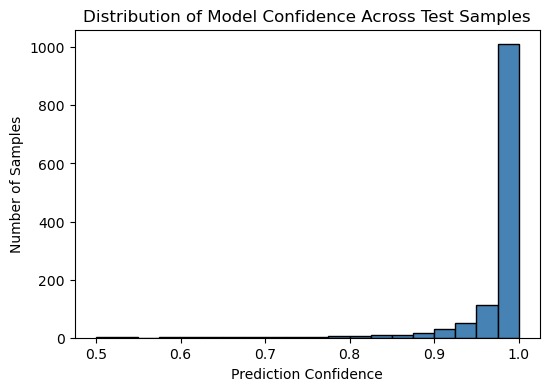
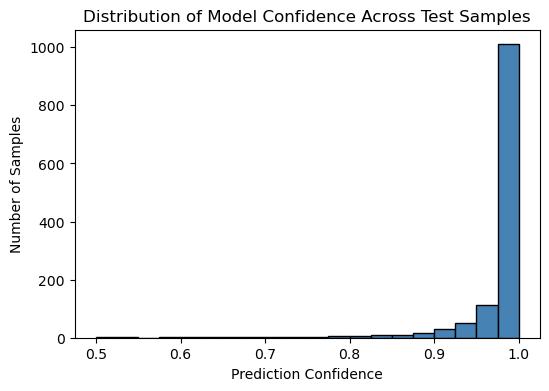
This confidence-aware view prevents overinterpretation of uncertain genomic predictions.
-
End-to-end reproducible Jupyter Notebook workflow for genomic ML analysis and interpretation.
Inspiration
My inspiration for this project comes directly from my ongoing PhD research, where I work with computational and data-driven approaches to study complex biological systems. While working with high-dimensional biological data, I repeatedly encountered a common challenge that many machine-learning models achieve strong predictive performance but offer limited interpretability, restricting their usefulness for meaningful biological or clinical insight.
This hackathon provided an opportunity to translate those research experiences into a conceptual proof-of-idea, exploring how interpretable machine learning could be applied to genomic data for Alzheimer’s disease risk stratification. Rather than building a production-ready clinical tool, the goal was to demonstrate how simple, transparent approaches can support hypothesis generation and research prioritization in real-world settings.
This project reflects the belief that impactful research ideas often emerge from simple, interpretable models-when designed thoughtfully-rather than from overly complex systems.
What it does
This project implements an interpretable machine-learning framework for genomic risk stratification in Alzheimer’s disease. The model performs multi-class classification of genomic profiles and incorporates confidence-based stratification, allowing predictions to be grouped into high and low confidence categories. Using a conservative probability threshold, ~65-70% of test samples fall into a high-confidence category, while the remaining samples are explicitly flagged as uncertain rather than over-interpreted.
This approach helps distinguish cases where the model predictions are more reliable from those that require cautious interpretation, adding a human-interpretable decision layer beyond accuracy alone. Rather than forcing predictions for all samples, this framework explicitly separates high-confidence and low-confidence predictions. This allows downstream researchers to prioritize only reliable genomic risk estimates, while flagging uncertain cases for further biological validation.
How I built it
I used a curated genomic dataset provided as part of the hackathon challenge. After preprocessing and feature handling, I trained a Random Forest classifier, selected for its robustness on high-dimensional tabular data and its inherent interpretability.
Model performance was evaluated on a held-out test set. Feature importance analysis and SHAP-based explanations were applied to understand the contribution of individual genomic features. A probability-based thresholding strategy was used to derive confidence-based risk groups.
Challenges I ran into
Balancing predictive performance with interpretability was a key challenge. High-dimensional genomic data can easily lead to overfitting or opaque model behavior. Ensuring that confidence estimation reflected meaningful uncertainty, rather than being an artifact of probability calibration, also required careful consideration.
Accomplishments that I’m proud of
- Built a complete end-to-end machine-learning pipeline within the hackathon timeframe
- Achieved stable multi-class prediction performance on genomic data
- Integrated model interpretability and confidence-based stratification beyond accuracy-only evaluation
- Delivered a fully reproducible and well-documented workflow
What I learned
One key insight from this project was that effective solutions do not always require complex or highly sophisticated models. In high-dimensional biological problems, carefully chosen simple models-when combined with proper validation, interpretability, and confidence estimation-can provide meaningful and actionable insights. This project reinforced the importance of prioritizing clarity, robustness, and interpretability over complexity for its own sake. It also highlighted the critical role of deeply understanding the data before selecting or designing a modeling approach. In genomics-driven problems, the structure, constraints, and context of the data often dictate the most appropriate solution. These insights align with the broader shift toward precision medicine, where data-informed and context-aware modeling strategies are essential for responsible analysis. Ultimately, this work emphasized that impactful solutions in precision medicine emerge from data-aligned modeling choices, not unnecessary complexity.
What’s next
This project is intended as a proof-of-concept demonstrating how interpretable machine learning can be applied to genomic risk stratification in Alzheimer’s disease. Future work would focus on validating this framework on independent cohorts and exploring its robustness across diverse genomic feature sets.
Building on my ongoing doctoral research, this approach could be extended by integrating additional biological layers such as transcriptomic or pathway-level features, as well as incorporating domain-knowledge-guided feature selection. Further refinement of confidence calibration and uncertainty estimation may improve its utility for real-world research prioritization. In the longer term, such interpretable and confidence-aware genomic models could contribute to precision medicine research by helping stratify heterogeneous patient populations and guiding hypothesis-driven follow-up studies, rather than direct clinical decision-making.
Ultimately, this work highlights how relatively simple, transparent machine-learning models-when thoughtfully designed-can serve as a practical bridge between computational methods and biological insight.
Built With
- jupyter-notebook
- numpy
- pandas
- python
- random
- scikit-learn
- shap



Log in or sign up for Devpost to join the conversation.