-
-
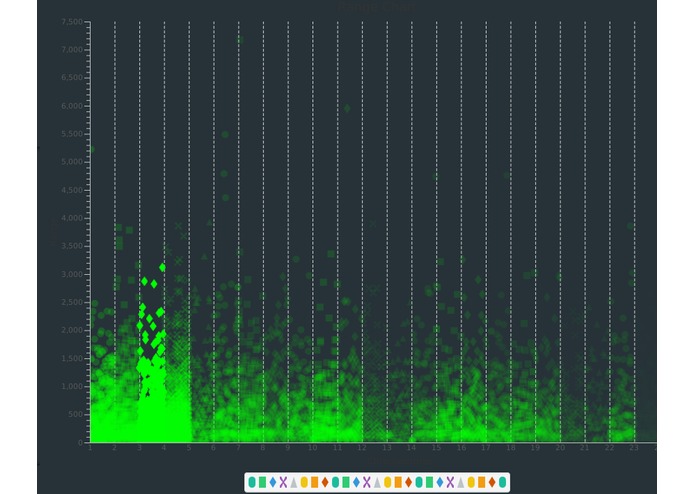
shows greener points where there is more overlap
-
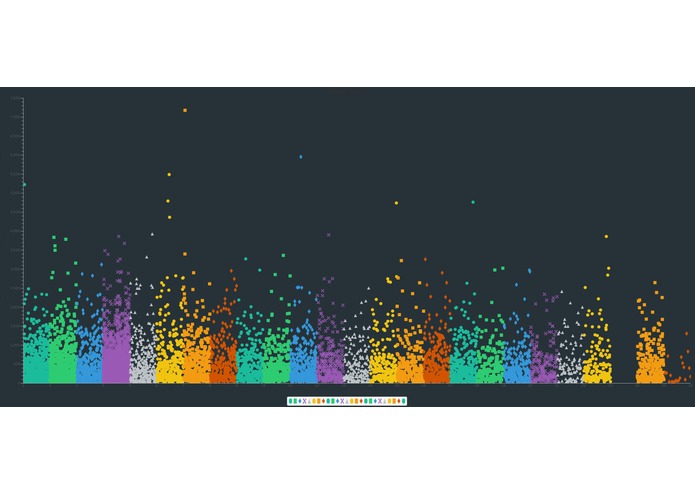
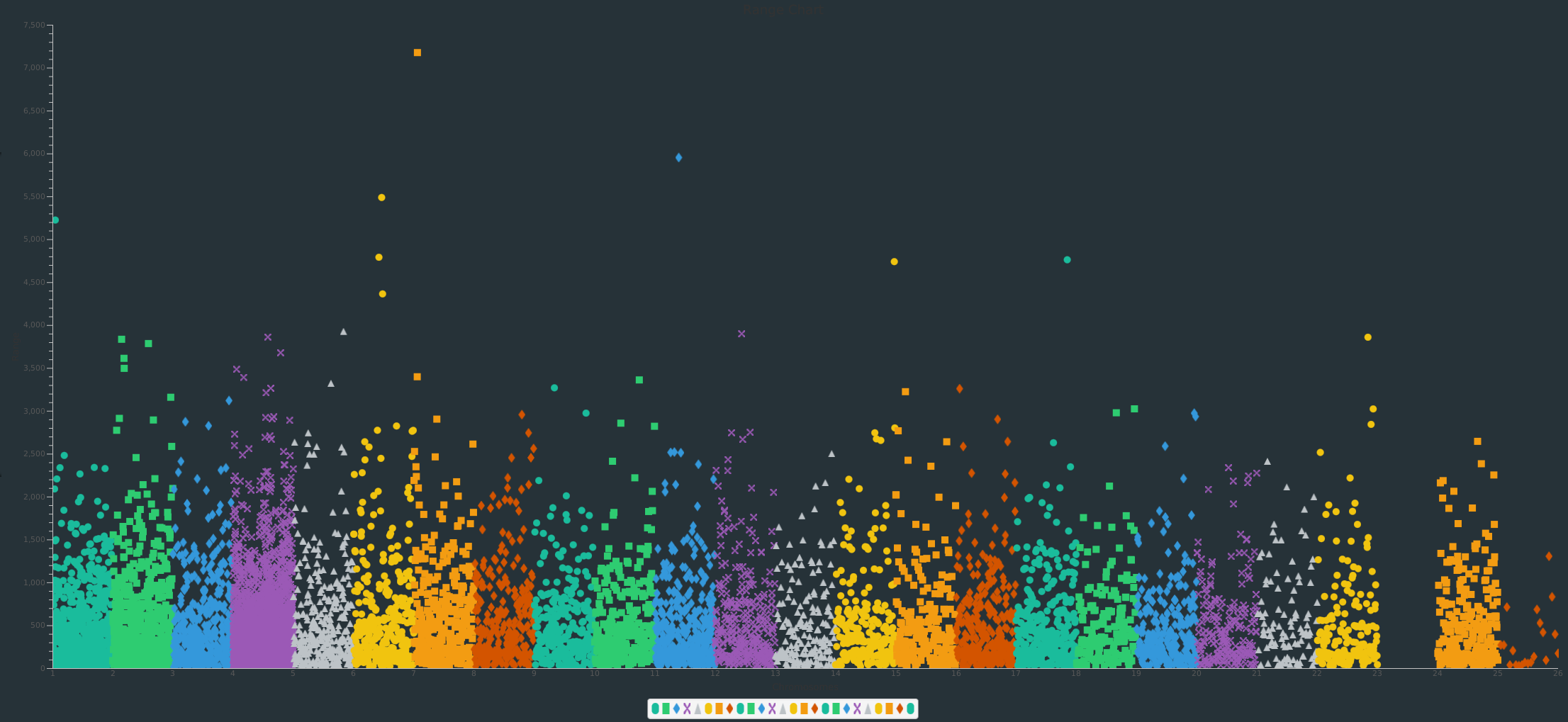
Shows a equal gap of range between chromosomes
-
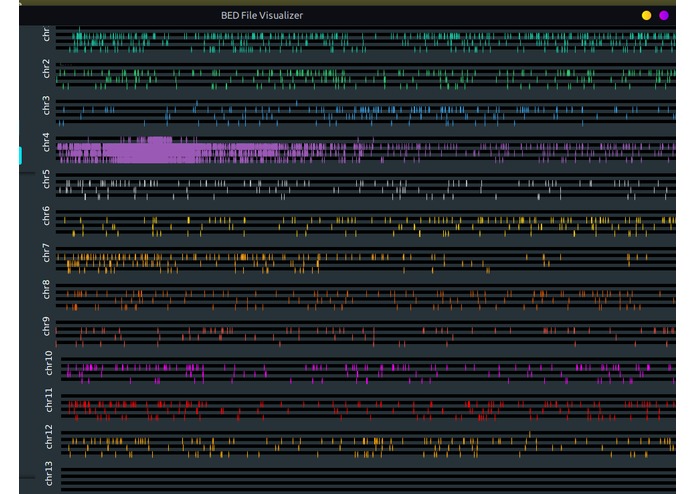
Shows interections between chromosomes on N number of files, Chromosome 4 can be see to have a prevalent one, meaning huntington's disease
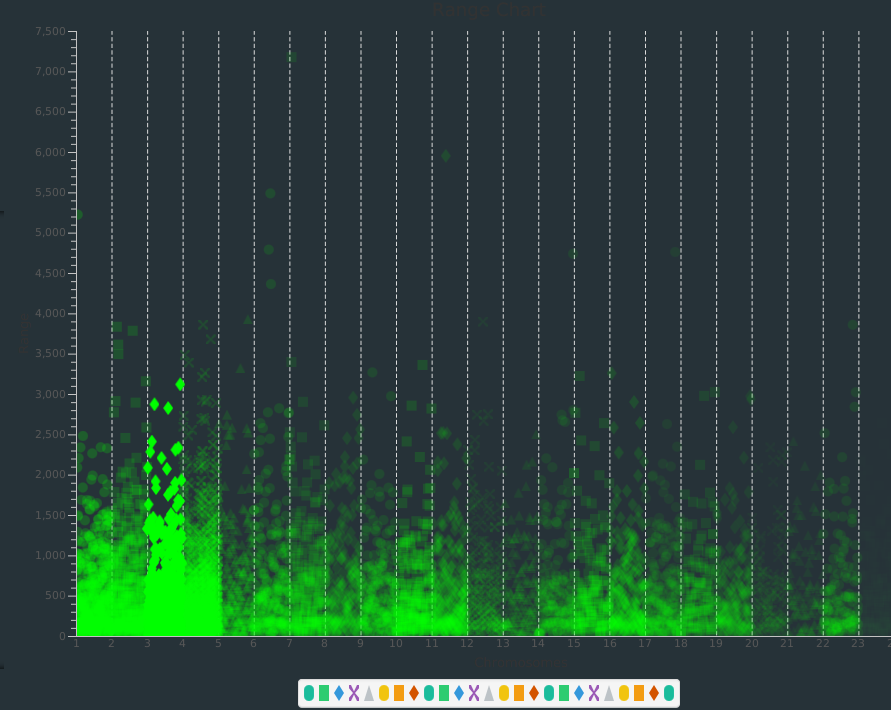

Inspiration
We worked towards using challenge one, because we had just learned about big O complexity in class, and this is a problem requiring speed and effeciency.
What it does
We worked towards creating a multithreaded algorithm to run use BED files, and find intersections, fragments, and lots of other variations inside. This is also visualized and allows people to see the data in a graph.
How we built it
We built it using a platform called Floobits, which allows us to basically have a live workspace where we can see what everyone else is doing, kind of like google docs. This allowed us to have unparralled teamwork experience and rapid development times. We used JavaFX to visualize all of our graphs, along with Python to multithread all of the processing.
Challenges we ran into
We had a lot of trouble creating the custom charts as it required quite a bit of problem solving because we kept running out of memory when performing this linearly, so we made a workaround which iterates through multiple files at once.
Accomplishments that we're proud of
We were proud of the custom graph objects that we made, and also all the data normalization that we performed to create elegant and easy to read user interfaces. We also used multithreading concepts to make the data processing run much much faster. Which allowed us to have instant generation of graphs etc.
What we learned
We learned how to create custom objects in javafx, time and sleep management between team members, and also modularity. We found that splitting up the work into different modules and allowing people to work on their code, and then just plugging it all together was much faster, and allowed us to progress much faster as a team.
What's next for (Genomic) BED File Visualizer
if successfull, we could take this project a lot further and actually maintain it, as it already does a lot of analysis and can really help people find rare diseases in a much cheaper process.





Log in or sign up for Devpost to join the conversation.