GenomeComparison
MinHashing implementation of LSH Randomized Algorithm for genome comparison
Randomized Algorithms have been used for a long time primarily to cut down on the run-time and space complexity of a similar deterministic algorithm. As its name implies, Randomized algorithms, like the MinHash implementation of LSH, use some sort of random feature as part of its logic to solve the given problem. Locality Sensitive Hashing, otherwise known as LSH, utilizes the basic idea that the hash code will put items with a high similarity index in the same bucket with a high probability, while it will put items with a low similarity index in different buckets with a high probability.
LSH is used commonly in Near-Duplication detection with documents & text files, similar gene expression in genomes, and audio & video fingerprinting. For example, we can compare the different strains of COVID-19 that are found around the world and see if the virus has mutated. The viruses strains that are similar to each other will most likely will be placed in the same bucket, while viruses that are different from each other will placed in distinct buckets. This proves helpful to epidemiologists and Infectious Disease Specialists who can now develop strategies to attack each individual strain of the virus as opposed to one strain. It will also be helpful to know if the virus has mutated, so vaccine researchers can create a COVID-19 shot that is effective against the most prevalent strain or most strains of the virus.
Our LSH algorithm can be classified as a Monte Carlo Algorithm because the underlying concept of LSH is to use randomness to find similarity between two items. As just explained, when the LSH algorithm performs its similarity computations, it only does so to a certain (high) probability, hence its Monte Carlo nature. In other words, the LSH can produce both false negatives and positives.
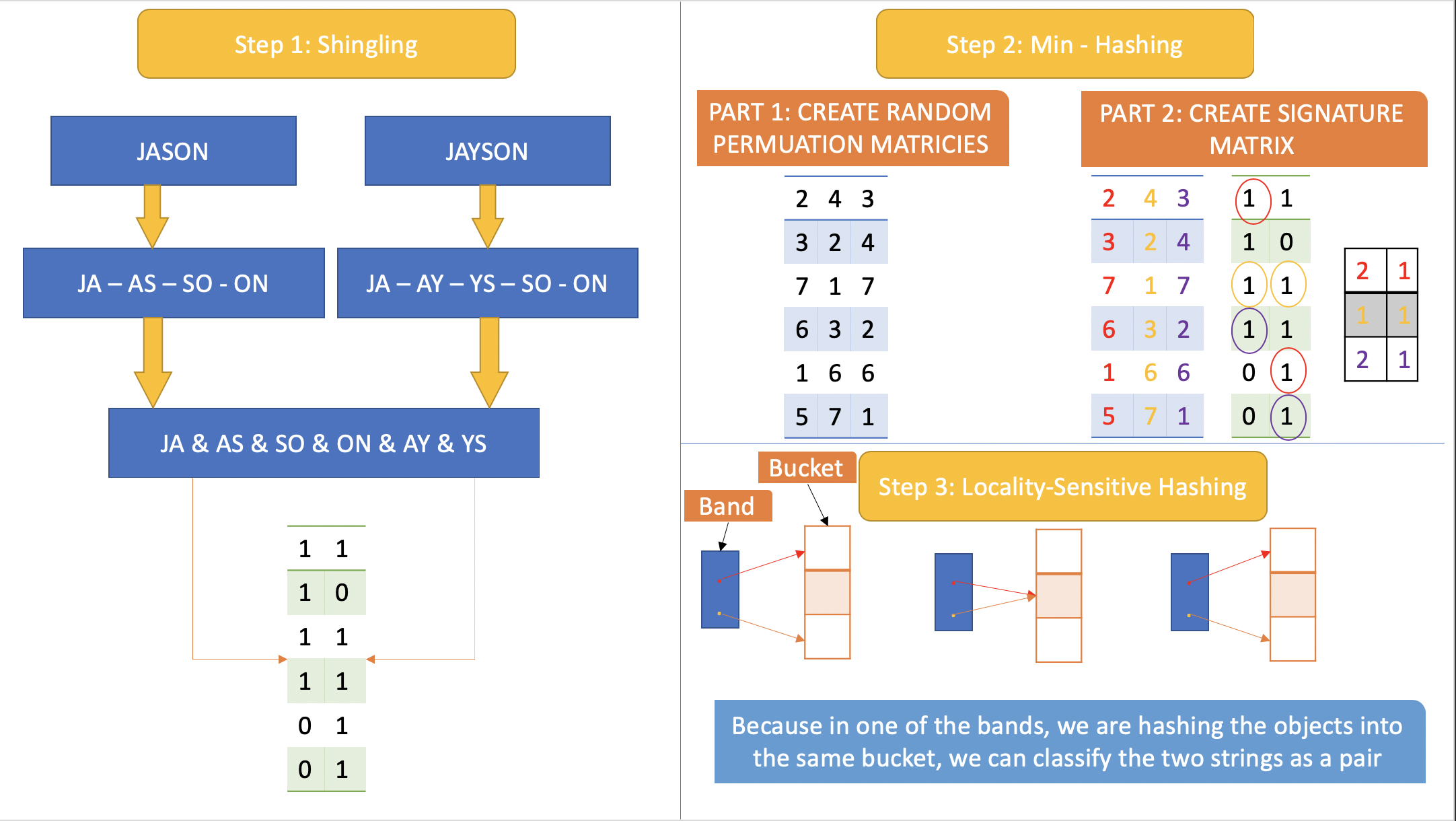
Using the naive approach to the Jaccard index to compute the similarity between two documents, we can essentially use the predetermined shingles to define which shingles the two documents have in common as the intersection, and those that are in either as the union. Computing the index therefore involves diving this intersection by the union, which provides an exact similarity percentage between the provided texts.
The MinHash implementation of LSH provides an effective estimate of the Jaccard index in a few ways. The MinHash implementation acts as an additional step to eliminate the sparseness of the shingles document, improving the space complexity for when we have to hash rows into buckets to determine similarity. This is because rather than mapping shingles to documents (which results in a lot of zeroes, especially with dissimilar documents), we are now mapping permutations to the documents in the new signature matrix, which no longer has to keep track of the large amount of shingles.
 Format:
Format: 
 Format:
Format:

Log in or sign up for Devpost to join the conversation.