-
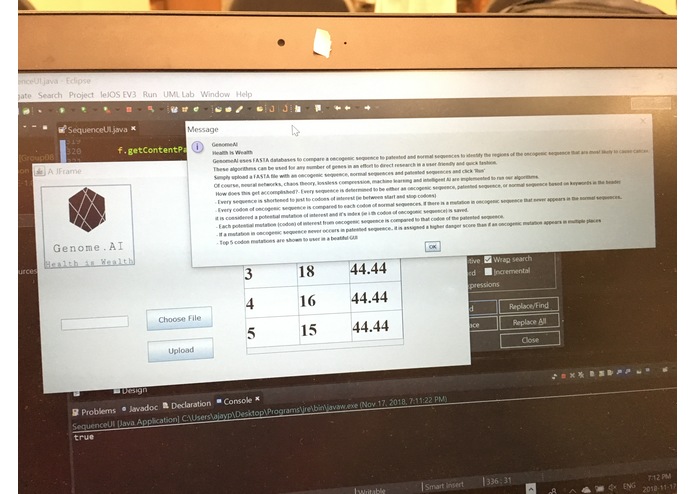
Our GUI in action on ERBB2 gene
-
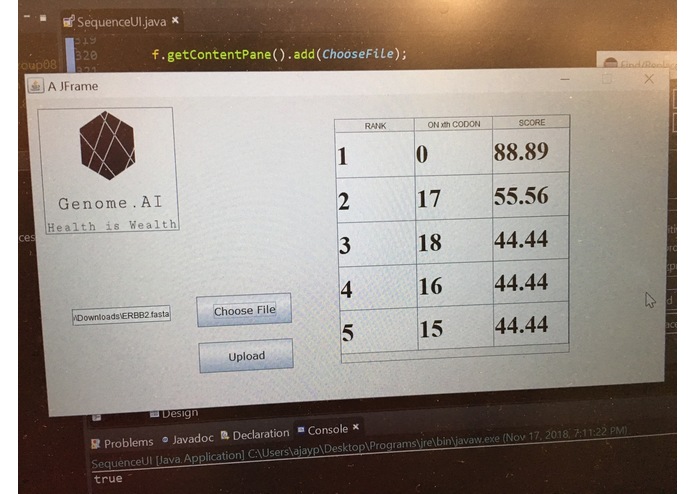
Our GUI in action on ERBB2 gene
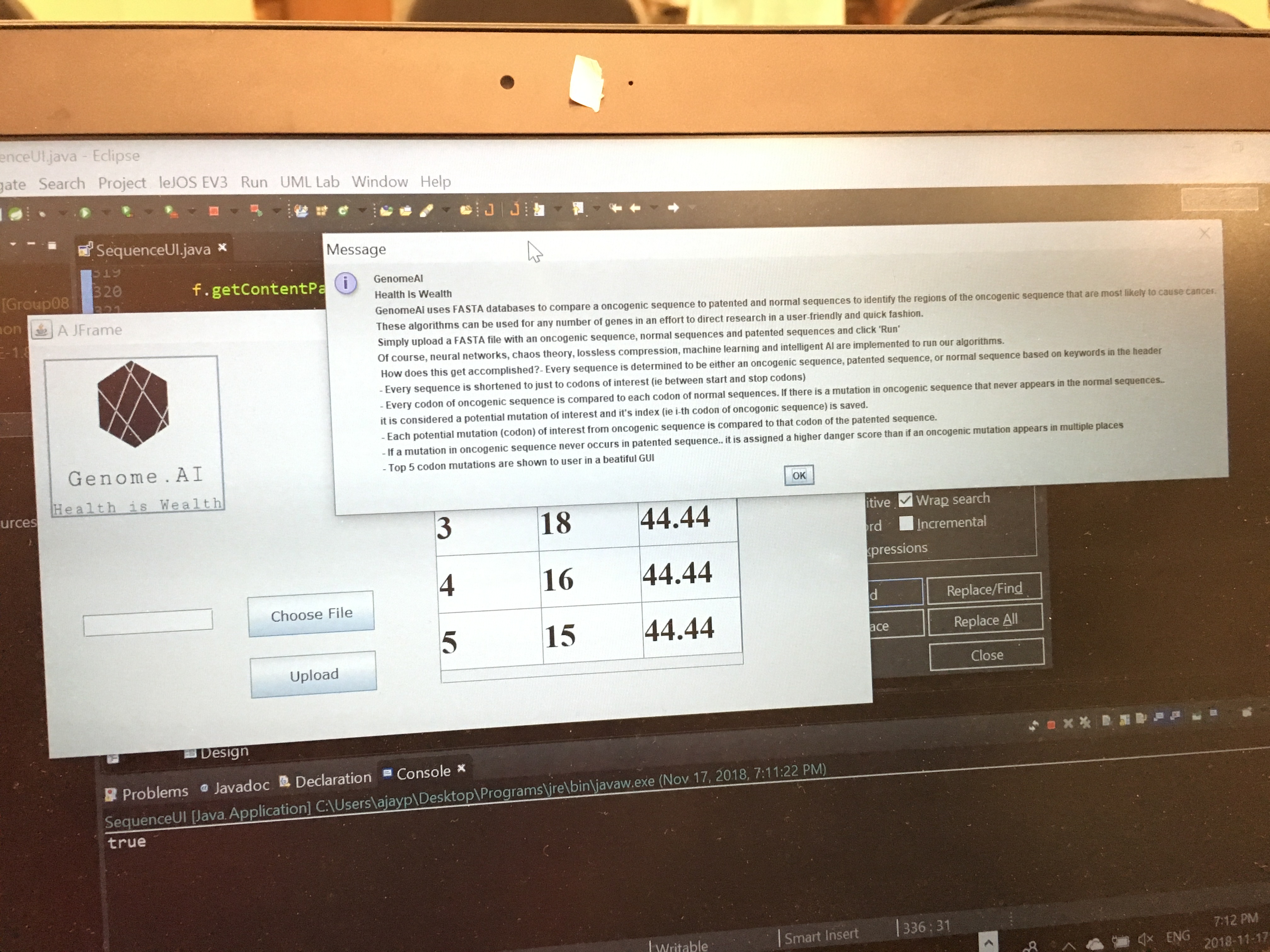
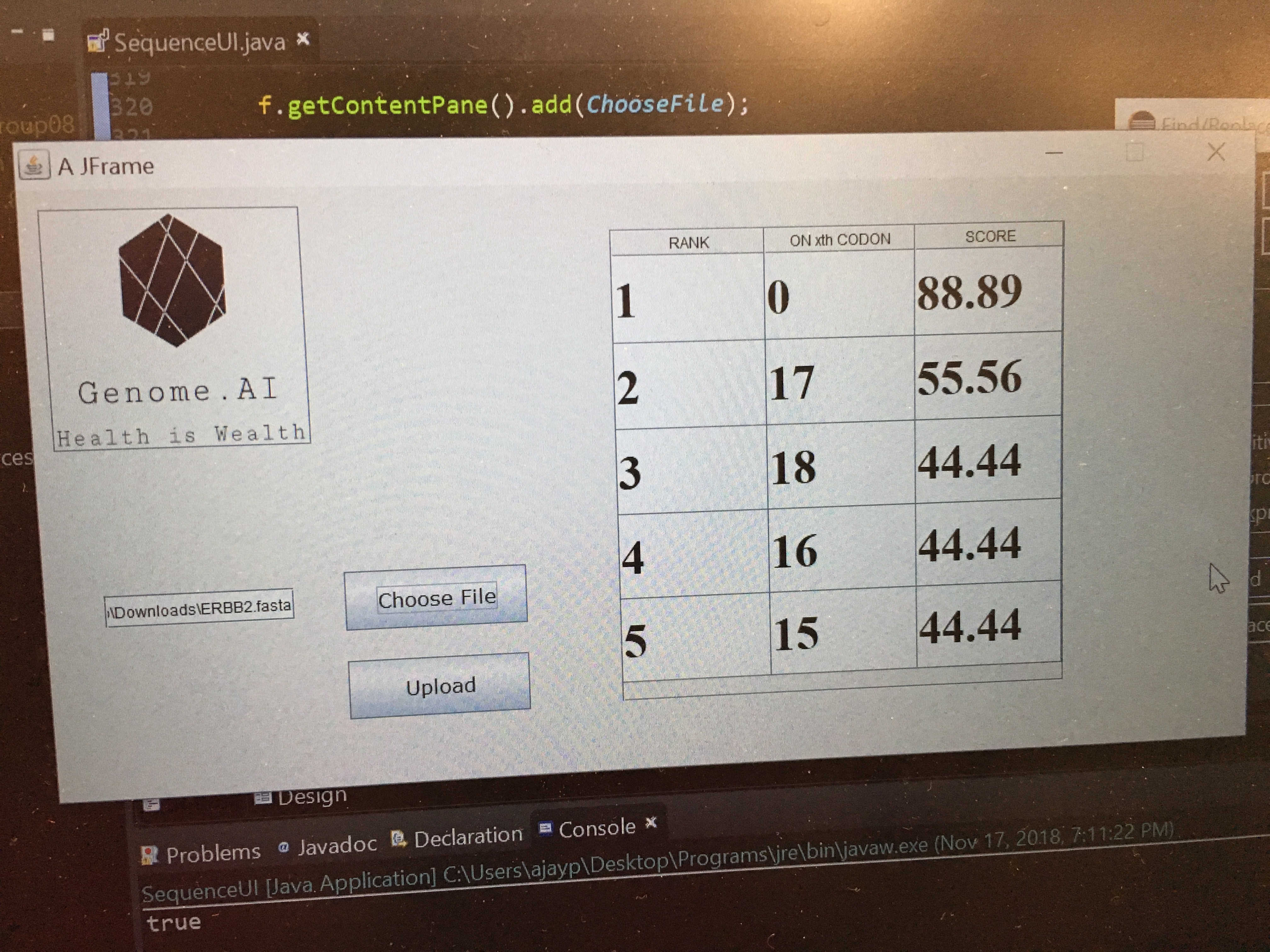
Inspiration: Cancer is one of the deadliest diseases in the world. Part of what is limiting cancer research is knowing where to look, and being able to analyze huge amounts of data. This projects aims to provide useful information to researchers about oncogenic sequences and where to direct their research.
What it does: GenomeAI uses FASTA databases to compare oncogenic sequences to normal sequences to identify the oncogenic muations that are most likely to cause cancer. These algorithms can be used for any number of genes in an effort to direct research in a user-friendly and quick fashion. Simply upload a FASTA file with an oncogenic sequence, normal sequences and patented sequences and click 'Run' on an easy-to use GUI.
ALREADY IMPLEMENTED FOR THE ERBB2 gene!
- Every sequence is determined to be either an oncogenic sequence, patented sequence, or normal sequence based on keywords in the header
- Every sequence is shortened to just to codons of interest (ie between start and stop codons)
- Every codon of oncogenic sequence is compared to each codon of normal sequences. If there is a mutation in oncogenic sequence that never appears in the normal sequences.. it is considered a potential mutation of interest and it's index (ie i-th codon of oncogonic sequence) is saved.
- Each potential mutation (codon) of interest from oncogenic sequence is compared to that codon of the patented sequence.
- If a mutation in oncogenic sequence never occurs in patented sequence.. it is assigned a higher danger score than if an oncogenic mutation appears in multiple places
- Top 5 codon mutations are shown to user in a beautiful GUI.
Challenges we ran into: Understanding the complexities of DNA sequences was very challenging for us since we do not all have biological backgrounds and in order to provide useful output, we needed to ensure we had a grasp of the science. Moreover, working with big data sets and many files was not easy.
What's next for GenomeAi: We would like to create a database of many genes in order to incorporate AI and machine learning to predict which mutations in oncogenic sequences are the most important. Moreover, increase the functioning of the GUI and increasing the number of statistics on the data in order to help doctors and researchers as much as we can.






Log in or sign up for Devpost to join the conversation.